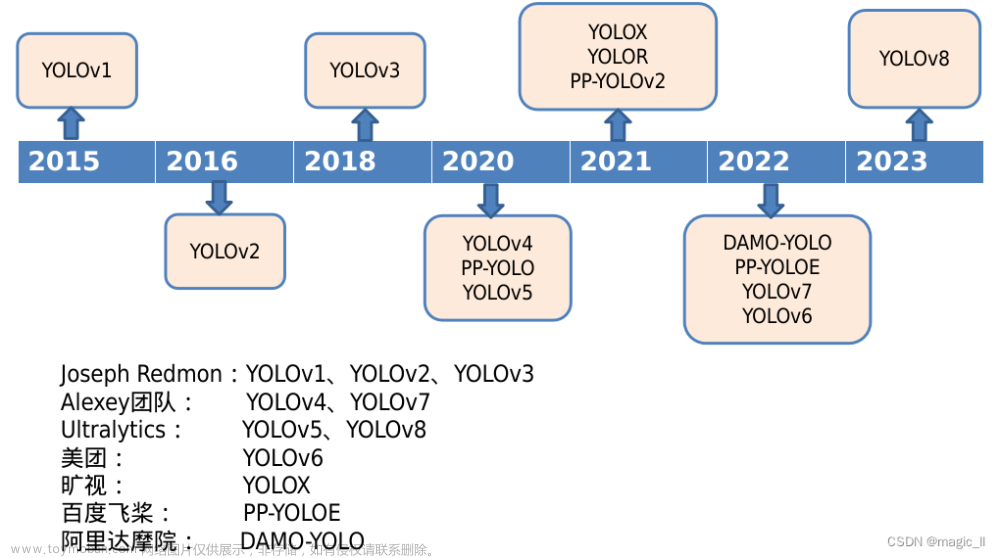
YOLOv8是目前最新版本,在以前YOLO版本基础上建立并加入了一些新的功能,以进一步提高性能和灵活性,是目前最先进的模型。YOLOv8旨在快速,准确,易于使用,使其成为广泛的目标检测和跟踪,实例分割,图像分类和姿态估计任务的绝佳选择。
1、安装YOLOv8
YOLOv8的安装条件
Python>=3.8
PyTorch>=1.7
安装参考方法:
conda create -n yolov8torch python=3.8
activate yolov8torch
#进入到环境之后,克隆下来进行安装
git clone https://github.com/ultralytics/ultralytics
cd ultralytics
pip install -e .
或者直接pip安装(推荐)
pip install ultralytics -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
安装完了之后,我们pip list查看下包的情况:

可以看到默认安装的这个torch为2.0.1版本,对应的torchvision是0.15.2版本,这个跟上一节的YOLOv5的
torch 1.9.0+cu111
torchvision 0.10.0+cu111
版本升级了,torch从1.9到2.0,torchvision也从0.1到0.15
2、YOLO一些命令
2.1、yolo help
一些如何使用的帮助信息:
Arguments received: ['yolo', 'help']. Ultralytics 'yolo' commands use the following syntax:
yolo TASK MODE ARGS
Where TASK (optional) is one of ('detect', 'segment', 'classify', 'pose')
MODE (required) is one of ('train', 'val', 'predict', 'export', 'track', 'benchmark')
ARGS (optional) are any number of custom 'arg=value' pairs like 'imgsz=320' that override defaults.
See all ARGS at https://docs.ultralytics.com/usage/cfg or with 'yolo cfg'1. Train a detection model for 10 epochs with an initial learning_rate of 0.01
yolo train data=coco128.yaml model=yolov8n.pt epochs=10 lr0=0.012. Predict a YouTube video using a pretrained segmentation model at image size 320:
yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=3203. Val a pretrained detection model at batch-size 1 and image size 640:
yolo val model=yolov8n.pt data=coco128.yaml batch=1 imgsz=6404. Export a YOLOv8n classification model to ONNX format at image size 224 by 128 (no TASK required)
yolo export model=yolov8n-cls.pt format=onnx imgsz=224,1285. Run special commands:
yolo help
yolo checks
yolo version
yolo settings
yolo copy-cfg
yolo cfgDocs: https://docs.ultralytics.com
Community: https://community.ultralytics.com
GitHub: https://github.com/ultralytics/ultralytics
2.2、yolo checks
安装的信息和本地CPU,内存和硬盘情况
Ultralytics YOLOv8.0.121 Python-3.8.16 torch-2.0.1+cpu CPU
Setup complete (4 CPUs, 16.0 GB RAM, 128.4/152.1 GB disk)
2.3、yolo version
当前的YOLO版本
8.0.121
2.4、yolo settings
一些设置信息
Printing 'C:\Users\Tony\AppData\Roaming\Ultralytics\settings.yaml'
datasets_dir: C:\Users\Tony\datasets
weights_dir: weights
runs_dir: runs
uuid: 6d4f9bb21b7de61b6e347095d24af1791873a87c908b54735ad4c38b58d6e67d
sync: true
api_key: ''
settings_version: 0.0.3
2.5、yolo copy-cfg和yolo cfg
yolo copy-cfg拷贝模型配置文件
D:\Anaconda3\envs\yolov8torch\Lib\site-packages\ultralytics\yolo\cfg\default.yaml copied to C:\Users\Tony\ultralytics\default_copy.yaml
Example YOLO command with this new custom cfg:
yolo cfg='C:\Users\Tony\ultralytics\default_copy.yaml' imgsz=320 batch=8
yolo cfg直接查看或者打开.yaml文件也可以查看,里面是一些模型相关信息配置和参数等设置
3、运行YOLOv8
3.1、检测图片
安装好了之后,我们来检测下模型:
yolo predict model=yolov8n.pt source='https://tenfei03.cfp.cn/creative/vcg/veer/1600water/veer-327742747.jpg'
其中yolov8n.pt的权重参数文件,对于不能科学上网的朋友或者下载速度特别慢,我也上传到了CSDN,可以点击下载:
yolov8n.pt和yolov8n-seg.pt权重参数文件
下载好了之后,放入到ultralytics目录即可:
Ultralytics YOLOv8.0.121 Python-3.8.16 torch-2.0.1+cpu CPU
YOLOv8n summary (fused): 168 layers, 3151904 parameters, 0 gradientsDownloading https:\tenfei03.cfp.cn\creative\vcg\veer\1600water\veer-327742747.jpg to veer-327742747.jpg...
100%|███████████████████████████████████████████████████████████████████████████████| 348k/348k [00:00<00:00, 3.73MB/s]
image 1/1 C:\Users\Tony\ultralytics\veer-327742747.jpg: 448x640 4 persons, 124.0ms
Speed: 4.0ms preprocess, 124.0ms inference, 3.0ms postprocess per image at shape (1, 3, 640, 640)
Results saved to runs\detect\predict
检测的图片在runs\detect\predict目录里面,如下图:

3.2、检测视频
同样的也可以检测视频:
yolo predict model=yolov8n-seg.pt source='https://youtu.be/Zgi9g1ksQHc' imgsz=320
https://www.youtube.com/watch?v=au9k1QRTPlw
这里是油管的4分33秒时长的视频,需要科学上网,其中的权重参数文件yolov8n-seg.pt一起放在上面那个下载地址。
3.3、错误处理
处理视频的时候,不出意外这里出现缺失模块:ModuleNotFoundError: No module named 'pafy'
pafy是一个用于下载油管视频内容和检索元数据的Python库
pip install pafy -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
更多详情可以查阅:https://pythonhosted.org/pafy/
ImportError: pafy: youtube-dl not found; you can use the internal backend by setting the environmental variable PAFY_BACKEND to "internal". It is not enabled by default because it is not as well maintained as the youtube-dl backend.
ModuleNotFoundError: No module named 'youtube_dl'
还需要安装一个对油管视频操作的库youtube_dl:
pip install youtube_dl -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
安装这两个库之后,可以先查看下是否成功
import pafy
dir(pafy)
#['GdataError', '__author__', '__builtins__', '__cached__', '__doc__', '__file__', '__license__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '__version__', 'backend', 'backend_shared', 'call_gdata', 'channel', 'dump_cache', 'g', 'get_categoryname', 'get_channel', 'get_playlist', 'get_playlist2', 'load_cache', 'new', 'pafy', 'playlist', 'set_api_key', 'util']youtube-dl --help
也正常显示出这个库的用法。再来测试下:
youtube_dl.utils.RegexNotFoundError: Unable to extract uploader id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
ERROR: Unable to extract uploader id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
查看版本:
youtube-dl --version 或者 youtube_dl.version.__version__
'2021.12.17'
还以为是版本低了的缘故,于是进行升级
pip install --upgrade youtube_dl
但是发现问题不在这,这个就是最新版本,哈哈
直接下载试下:youtube-dl --list-formats https://www.youtube.com/watch?v=au9k1QRTPlw
依然报错:
ERROR: Unable to extract uploader id; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; see https://yt-dl.org/update on how to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
然后加一个 --verbose 参数看下具体错误,如图:


编码问题,于是将系统编码按上图步骤进行修改,之后,出现新的问题:
Fatal Python error: Py_Initialize: can't initialize sys standard streams
LookupError: unknown encoding: 65001Current thread 0x000027b8 (most recent call first):
Fatal Python error: Py_Initialize: can't initialize sys standard streams
LookupError: unknown encoding: 65001Current thread 0x00002da0 (most recent call first):
Fatal Python error: Py_Initialize: can't initialize sys standard streams
LookupError: unknown encoding: 65001Current thread 0x0000098c (most recent call first):
这整的编码造成不能初始化了,哈哈,然后修改回来,使用一个临时的编码修改来试下:
chcp 65001
这样就将默认的936修改成了65001,也就是中文变UTF-8,再来看下会不会成功:
Encodings: locale cp936, fs utf-8, out utf-8, pref cp936
什么鬼,编码还是没有变化啊。恩,想想也对,这个也只是在当前的命令行界面是更改过的编码。
————————————————————————————————
看来这个问题只能暂时搁置了,有解决办法的大佬欢迎留言,感谢!
4、JupyterLab中操作
上面是在命令行中操作,很多时候在JupyterLab操作还是要方便直观很多。
列出在JupyterLab中的核心:jupyter kernelspec list
删除不需要的:jupyter kernelspec remove xxx
activate yolov8torch
conda install -c conda-forge jupyterlab
conda install ipykernel
python -m ipykernel install --user --name=yolov8torch --display-name yolov8torch
代码如下:
from ultralytics import YOLO
#加载模型
model = YOLO("yolov8n.yaml")
model = YOLO("yolov8n.pt")
#若没有,将会下载coco128数据集(datasets\coco128下面的图片与标签)
model.train(data="coco128.yaml", epochs=3)
#在验证集上评估模型性能
metrics = model.val()
#预测
results = model("https://tenfei03.cfp.cn/creative/vcg/veer/1600water/veer-327742747.jpg")
#将模型导出为ONNX格式的
path = model.export(format="onnx")训练速度还是很快的,然后将会在runs\detect检测目录下面生成train和val的训练和验证的目录,里面有一些训练和验证的图片、权重文件、损失函数等可视化图片,比如说验证的其中一张:

其中需要转换成onnx格式的模型文件,所以需要安装onnx库
pip install onnx -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
将会生成在\runs\detect\train\weights目录
上面生成的onnx文件可以在 https://netron.app/ 这个站点上传,将显示整个模型的流程图和一些属性等,还可以导出,比如我将上面生成的best.onnx文件上传之后,生成的图,截图如下:

5、其他任务
当然除了上面的检测任务之外,还可以将里面的对象进行分类,分割,跟踪和姿态估计这样的任务。
5.1、分类任务
分类是最简单的一种,只需要检测里面的对象即可,不需要指定位置等情况
from ultralytics import YOLO
#加载分类模型(可以是官方给定模型,也可以是训练之后的模型)
model = YOLO('yolov8n-cls.yaml')
model = YOLO('yolov8n-cls.pt')
model = YOLO('yolov8n-cls.yaml').load('yolov8n-cls.pt')
#训练模型,数据集为MNIST
model.train(data='mnist160', epochs=100, imgsz=64)
results = model("https://alifei02.cfp.cn/creative/vcg/veer/1600water/veer-451045761.jpg")训练之后的结果在ultralytics\runs\classify目录里面。
其中权重参数文件和MNIST手写数字数据集(每个类8张图片,训练和测试总计160张),也为了方便大家,上传在CSDN,可以点击下载:数据集与权重参数文件
下载好的权重参数文件放在ultralytics当前项目里面,数据集放在上个目录的datasets中,解压之后为datasets\mnist160
命令行同样跟上面检测命令一样,这里是分类,然后指定预训练模型为分类,数据集这里选择imagenet100,对于不方便下载的朋友,也包含在上面的下载中
yolo task=classify mode=predict model=yolov8n-cls.pt data=imagenet100 source='https://alifei02.cfp.cn/creative/vcg/veer/1600water/veer-451045761.jpg'
分类如图:

5.2、分割任务
对于实例分割是在检测的基础上做的改进,除了识别对象之外,还要知道对象的确切形状,好进行分割。我们来看下分割的情况,当然官方给出的例子是COCO数据集,这个都没关系,我这里依然使用imagenet100数据集
yolo task=segment mode=predict model=yolov8n-seg.pt data=imagenet100 source='https://alifei02.cfp.cn/creative/vcg/veer/1600water/veer-451045761.jpg'
分割如图:

5.3、姿态估计
姿态估计可以识别图像中对象上关键点的位置,关键点可以代表物体的各个部分,如关节、地标或其他显著特征。关键点的位置通常表示为一组二维[x, y]或三维[x, y,visible]坐标。
姿态估计模型的输出是一组点,这些点代表图像中物体上的关键点,通常还有每个点的置信度分数。当你需要识别场景中物体的特定部分,以及它们彼此之间的位置时,姿势估计是一个很好的选择。
yolo task=pose mode=predict model=yolov8n-pose.pt data=imagenet100 source='https://alifei02.cfp.cn/creative/vcg/veer/1600water/veer-451045761.jpg'
姿态估计如图:

这些官方的.pt权重参数文件都保存在上面的一个下载地址中,当然也是可以自己训练得到pt权重文件,然后加载训练出来的权重文件,比如train\weights里面的best.pt,如果对于下载特慢或有需求的可以下载试试,体验下最新版本的YOLO。
引用来源
github:https://github.com/ultralytics/ultralytics文章来源:https://www.toymoban.com/news/detail-503664.html
文章来源地址https://www.toymoban.com/news/detail-503664.html
到了这里,关于YOLOv8的目标对象的分类,分割,跟踪和姿态估计的多任务检测实践(Netron模型可视化)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!