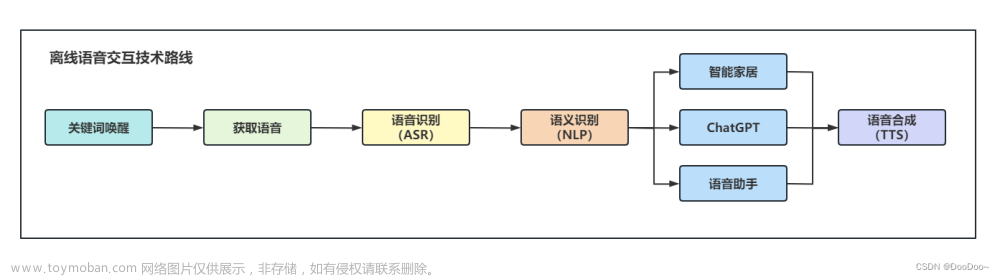
1、申请账户:
https://azure.microsoft.com/zh-cn/free/

这里有个视频教程,根据此完成申请流程:
https://www.bilibili.com/video/BV15a4y1W7re?vd_source=bf07f28d37849885d215dc3aea189eba
申请完成后,就可以到这里申请资源:
https://portal.azure.com/#home
点击资源组,里面就有部署好的服务了

点击这里,可以获取 subscription_key,另外还有个就是位置service_region (上图就是east asia),这两个后面会用到。
2、调用服务
在完成微软azure服务账号申请后,就可以进行调用了。代码:文章来源:https://www.toymoban.com/news/detail-503833.html
'''
After you've set your subscription key, run this application from your working
directory with this command: python TTSSample.py
'''
import os, requests, time
from xml.etree import ElementTree
# This code is required for Python 2.7
try: input = raw_input
except NameError: pass
'''
If you prefer, you can hardcode your subscription key as a string and remove
the provided conditional statement. However, we do recommend using environment
variables to secure your subscription keys. The environment variable is
set to SPEECH_SERVICE_KEY in our sample.
For example:
subscription_key = "Your-Key-Goes-Here"
'''
if 'SPEECH_SERVICE_KEY' in os.environ:
subscription_key = os.environ['SPEECH_SERVICE_KEY']
else:
print('Environment variable for your subscription key is not set.')
exit()
class TextToSpeech(object):
def __init__(self, subscription_key):
self.subscription_key = subscription_key
self.tts = input("What would you like to convert to speech: ")
self.timestr = time.strftime("%Y%m%d-%H%M")
self.access_token = None
'''
The TTS endpoint requires an access token. This method exchanges your
subscription key for an access token that is valid for ten minutes.
'''
def get_token(self):
fetch_token_url = "https://westus.api.cognitive.microsoft.com/sts/v1.0/issueToken"
headers = {
'Ocp-Apim-Subscription-Key': self.subscription_key
}
response = requests.post(fetch_token_url, headers=headers)
self.access_token = str(response.text)
def save_audio(self):
base_url = 'https://westus.tts.speech.microsoft.com/'
path = 'cognitiveservices/v1'
constructed_url = base_url + path
headers = {
'Authorization': 'Bearer ' + self.access_token,
'Content-Type': 'application/ssml+xml',
'X-Microsoft-OutputFormat': 'riff-24khz-16bit-mono-pcm',
'User-Agent': 'YOUR_RESOURCE_NAME'
}
xml_body = ElementTree.Element('speak', version='1.0')
xml_body.set('{http://www.w3.org/XML/1998/namespace}lang', 'en-us')
voice = ElementTree.SubElement(xml_body, 'voice')
voice.set('{http://www.w3.org/XML/1998/namespace}lang', 'en-US')
voice.set('name', 'en-US-Guy24kRUS') # Short name for 'Microsoft Server Speech Text to Speech Voice (en-US, Guy24KRUS)'
voice.text = self.tts
body = ElementTree.tostring(xml_body)
response = requests.post(constructed_url, headers=headers, data=body)
'''
If a success response is returned, then the binary audio is written
to file in your working directory. It is prefaced by sample and
includes the date.
'''
if response.status_code == 200:
with open('sample-' + self.timestr + '.wav', 'wb') as audio:
audio.write(response.content)
print("\nStatus code: " + str(response.status_code) + "\nYour TTS is ready for playback.\n")
else:
print("\nStatus code: " + str(response.status_code) + "\nSomething went wrong. Check your subscription key and headers.\n")
print("Reason: " + str(response.reason) + "\n")
def get_voices_list(self):
base_url = 'https://westus.tts.speech.microsoft.com/'
path = 'cognitiveservices/voices/list'
constructed_url = base_url + path
headers = {
'Authorization': 'Bearer ' + self.access_token,
}
response = requests.get(constructed_url, headers=headers)
if response.status_code == 200:
print("\nAvailable voices: \n" + response.text)
else:
print("\nStatus code: " + str(response.status_code) + "\nSomething went wrong. Check your subscription key and headers.\n")
if __name__ == "__main__":
app = TextToSpeech(subscription_key)
app.get_token()
app.save_audio()
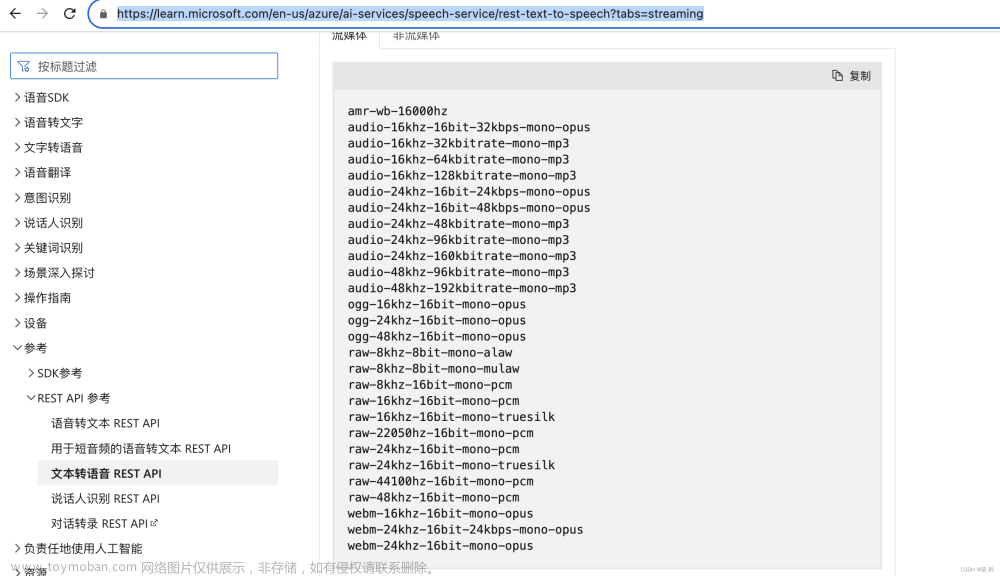
# Get a list of voices https://docs.microsoft.com/en-us/azure/cognitive-services/speech-service/rest-text-to-speech#get-a-list-of-voices
# app.get_voices_list()
参考文档:
https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/
https://github.com/Azure-Samples/Cognitive-Speech-TTS/blob/28681c8292c95aebb36d3696b8822b4cd17c3c45/Samples-Http/OLD/Python/TTSSample.py文章来源地址https://www.toymoban.com/news/detail-503833.html
到了这里,关于微软语音合成(tts)服务申请和调用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[Unity+OpenAI TTS] 集成openAI官方提供的语音合成服务,构建海王暖男数字人](https://imgs.yssmx.com/Uploads/2024/02/761897-1.png)