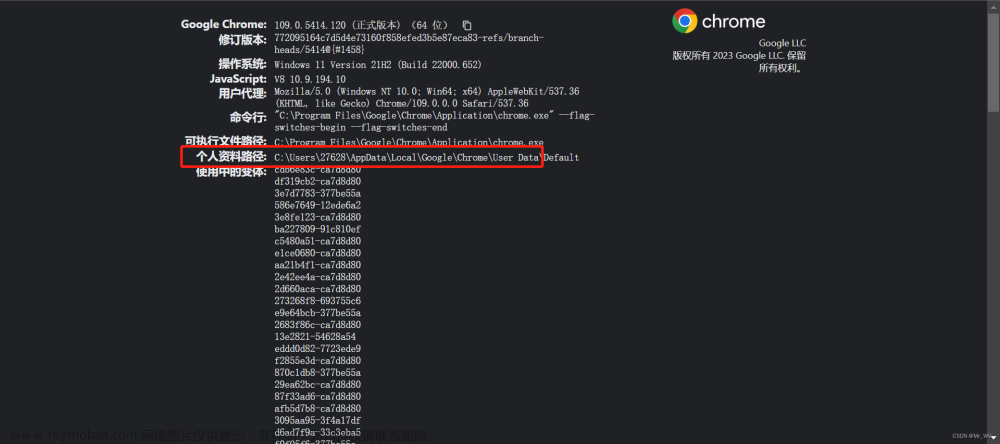
找到谷歌浏览器存放缓存信息的目录
打开谷歌浏览器访问chrome://version/

找到这个路径,把结尾的default去掉
#导入模块
from selenium import webdriver
# 添加保持登录的数据路径:安装目录一般在C:\Users\****\AppData\Local\Google\Chrome\User Data
user_data_dir = r'C:\Users\ASUS\AppData\Local\Google\Chrome\User Data'
#这是一个选项类
user_option = webdriver.ChromeOptions()
#添加浏览器用户数据
user_option.add_argument(f'--user-data-dir={user_data_dir}')
#实例化浏览器(带上用户数据)
driver = webdriver.Chrome(options=user_option)
driver.get("https://www.csdn.net/")输入以上代码再打开浏览器就是登录的状态了
注意:运行前要把谷歌浏览器的进程清理完,把所有的网页都关掉文章来源:https://www.toymoban.com/news/detail-504150.html
如果还不行就cmd输入tasklist | findstr chrome查看一下,如果还有进程就kill一下所有的chromedriver.exe文章来源地址https://www.toymoban.com/news/detail-504150.html
到了这里,关于selenium保留网页登陆信息(保留用户数据)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!