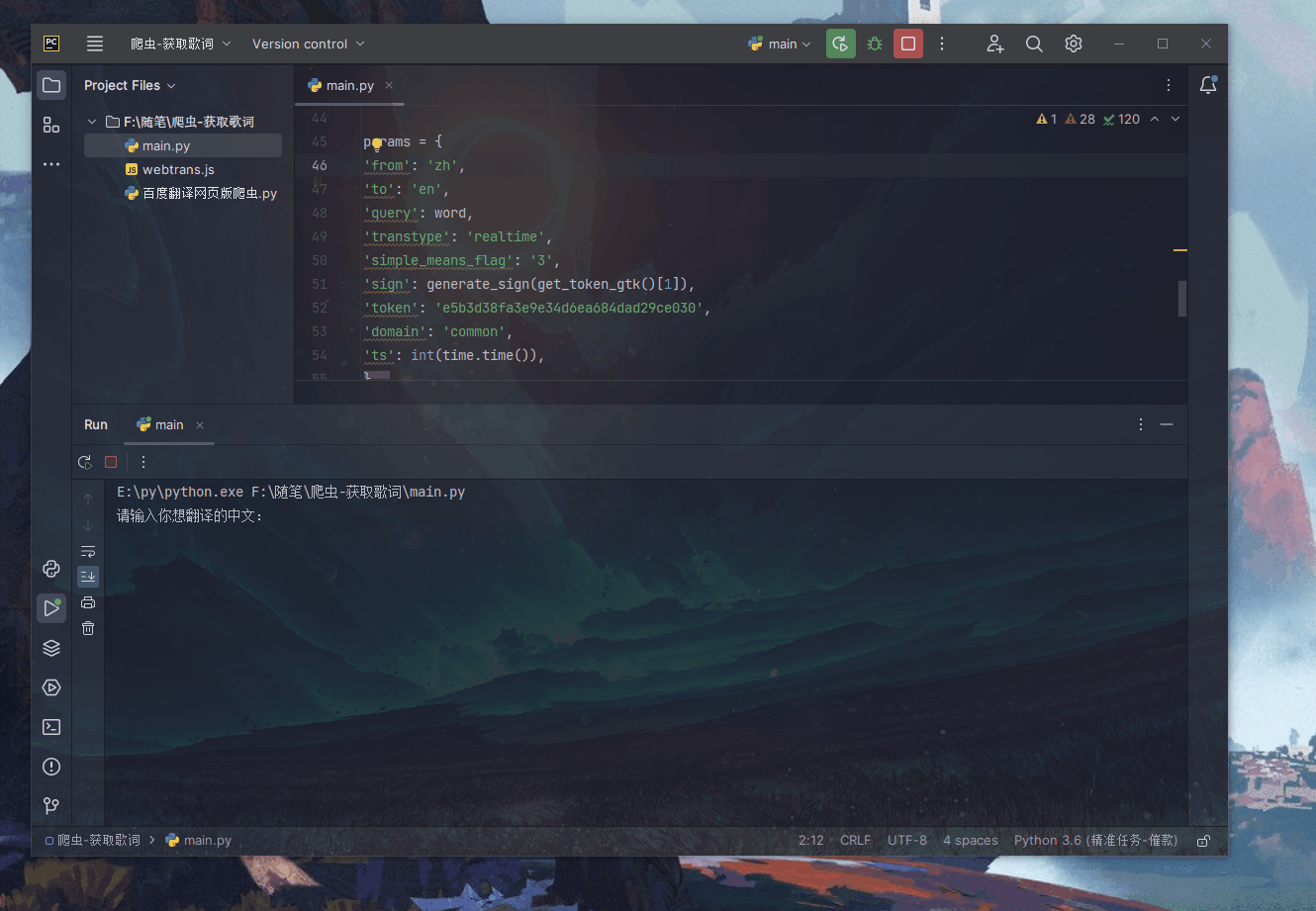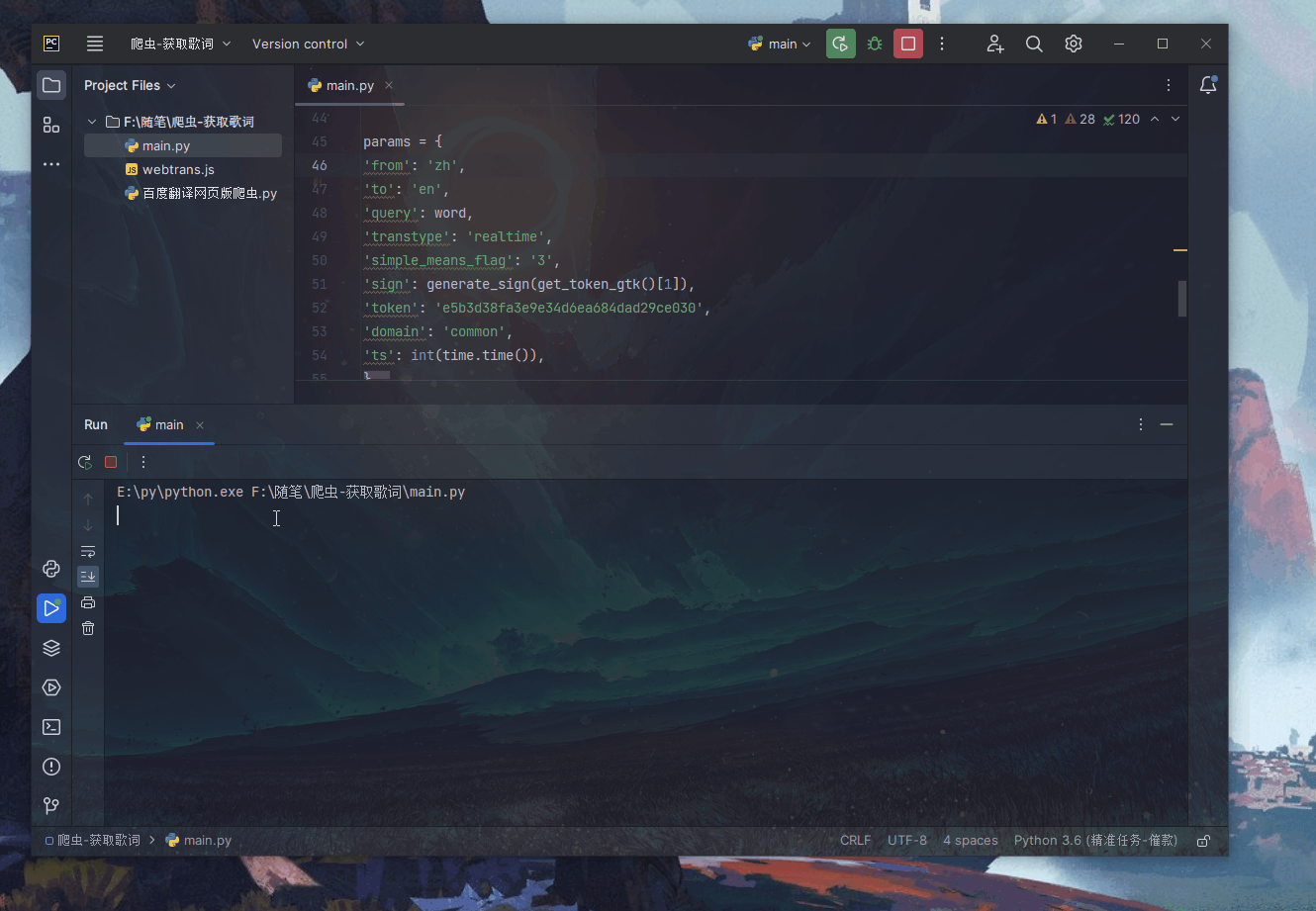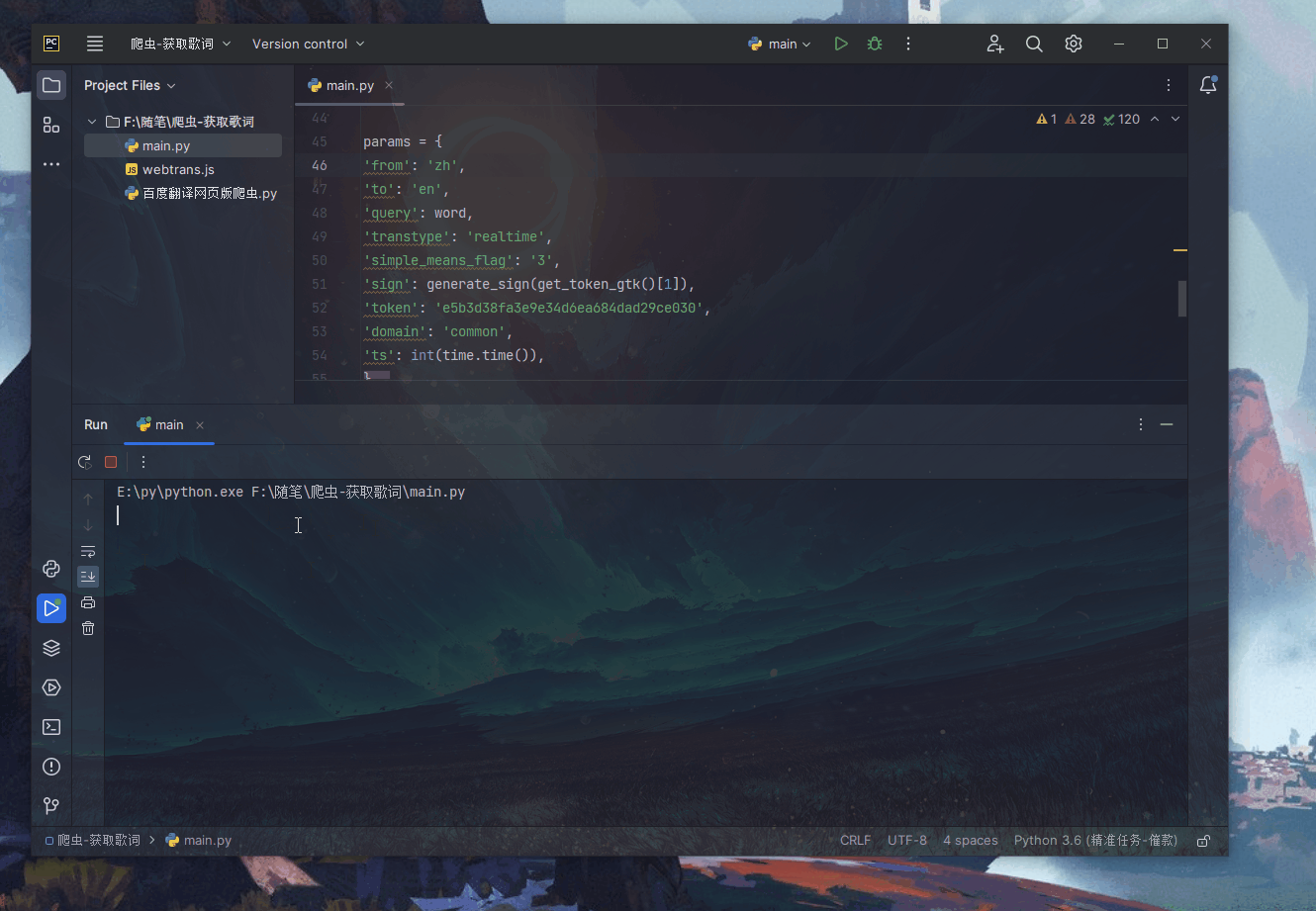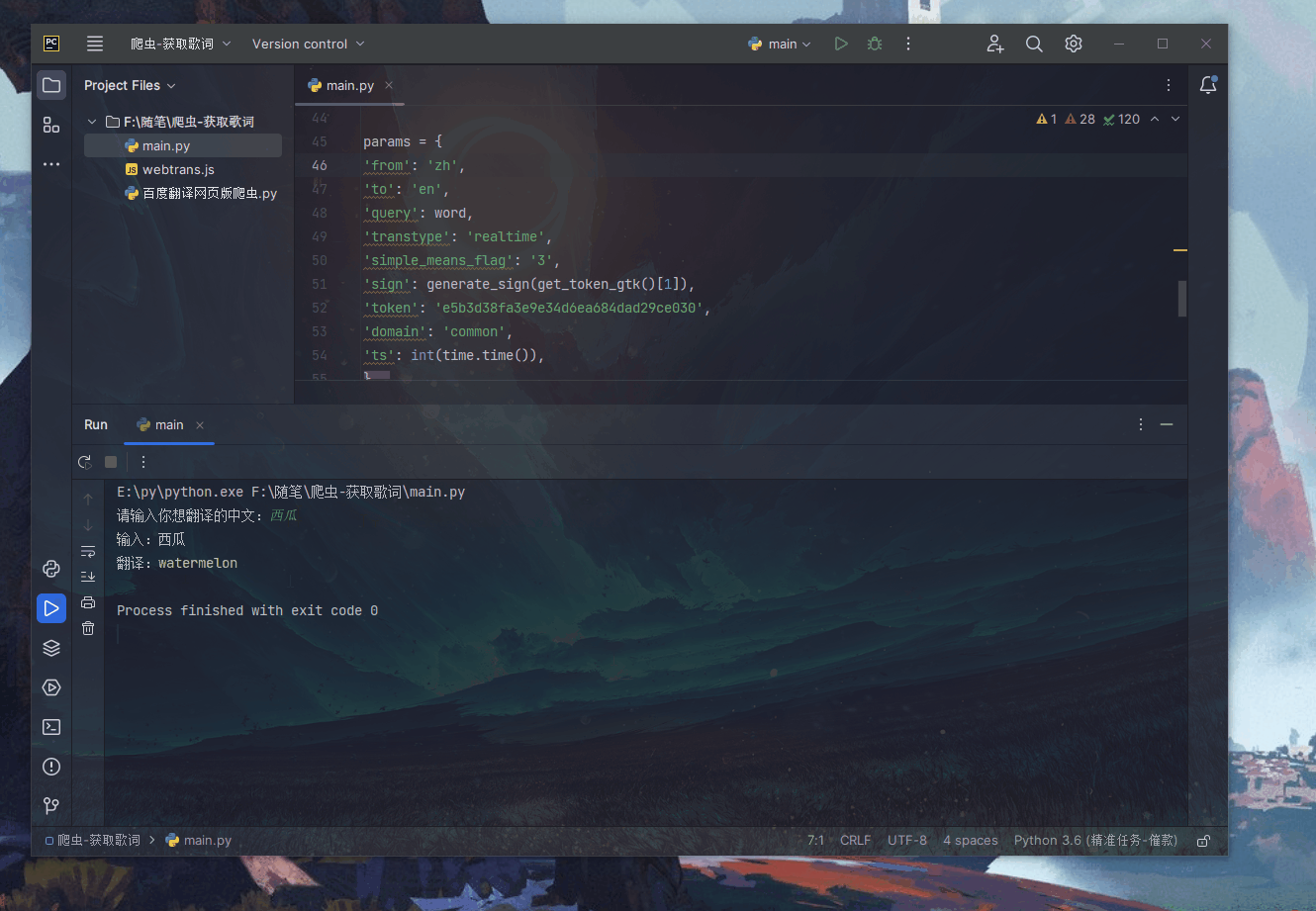
以下是一个基本的Python爬虫代码模板,可以根据需要进行修改:
```python
import requests
from bs4 import BeautifulSoup
# 设置请求头,模拟浏览器访问
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
# 发送请求
response = requests.get(url, headers=headers)
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取需要的信息
data = soup.find_all('tag', attrs={'class': 'class_name'})
# 处理数据
for item in data:
# 对数据进行处理
# 存储数据
with open('filename', 'w', encoding='utf-8') as f:
f.write(data)
# 完整代码
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
data = soup.find_all('tag', attrs={'class': 'class_name'})
for item in data:
# 对数据进行处理
with open('filename', 'w', encoding='utf-8') as f:
f.write(data)
```
其中,需要根据实际情况修改的部分包括:文章来源:https://www.toymoban.com/news/detail-504420.html
- `url`:需要爬取的网页链接。
- `tag`和`class_name`:需要提取的信息所在的HTML标签和类名。
- 数据处理部分:根据需要对提取的数据进行处理。
- 存储数据部分:根据需要将数据存储到文件或数据库中。文章来源地址https://www.toymoban.com/news/detail-504420.html
到了这里,关于Python爬虫完整代码模版的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!