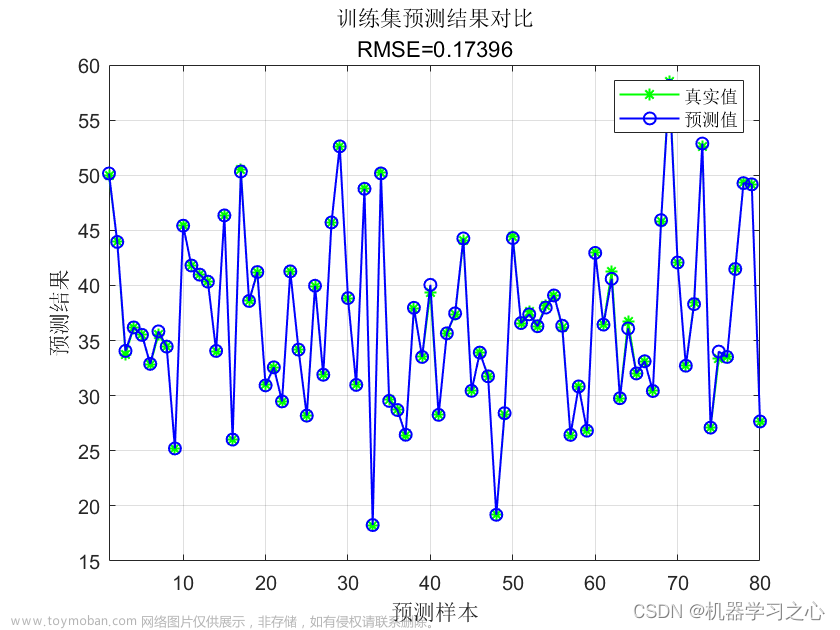
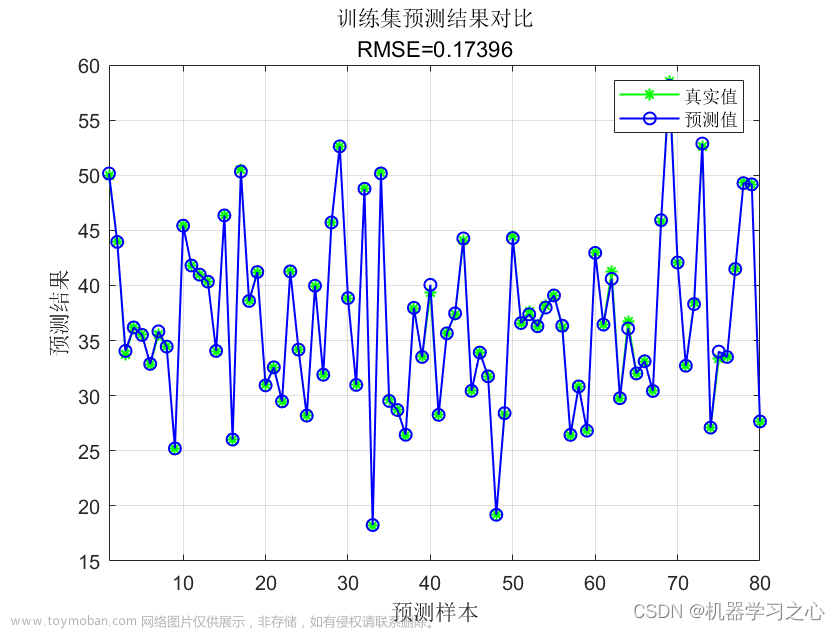
使用了scikit-learn库中的SVR类来实现支持向量机回归模型。首先,我们导入了所需的库,包括numpy用于处理数据,train_test_split用于划分训练集和测试集,SVR用于构建SVM回归模型,以及mean_squared_error和r2_score用于评估模型性能。
接着,我们定义了源数据,包括特征矩阵X和目标向量y。然后,我们使用train_test_split函数将数据划分为训练集和测试集。
接下来,我们创建了一个线性核函数的SVM回归模型,并使用fit方法拟合训练数据。
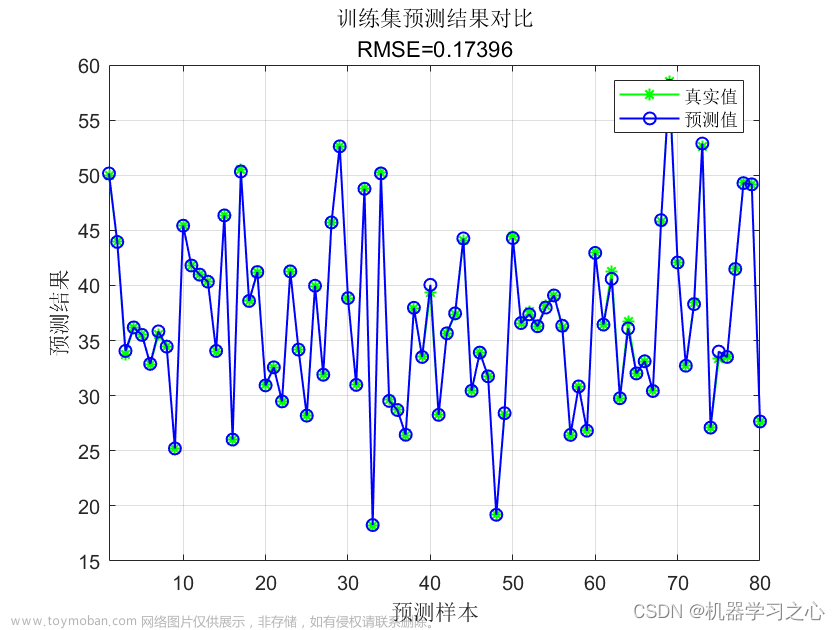
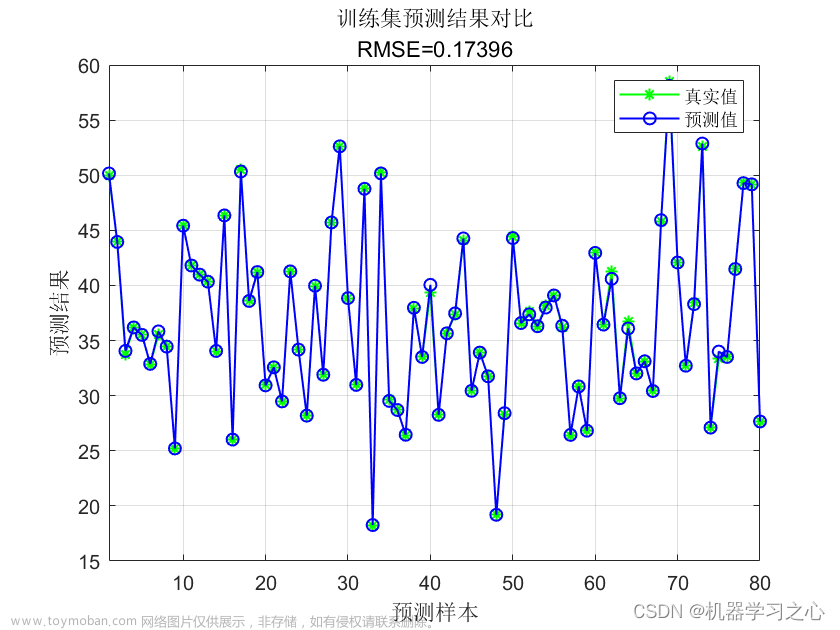
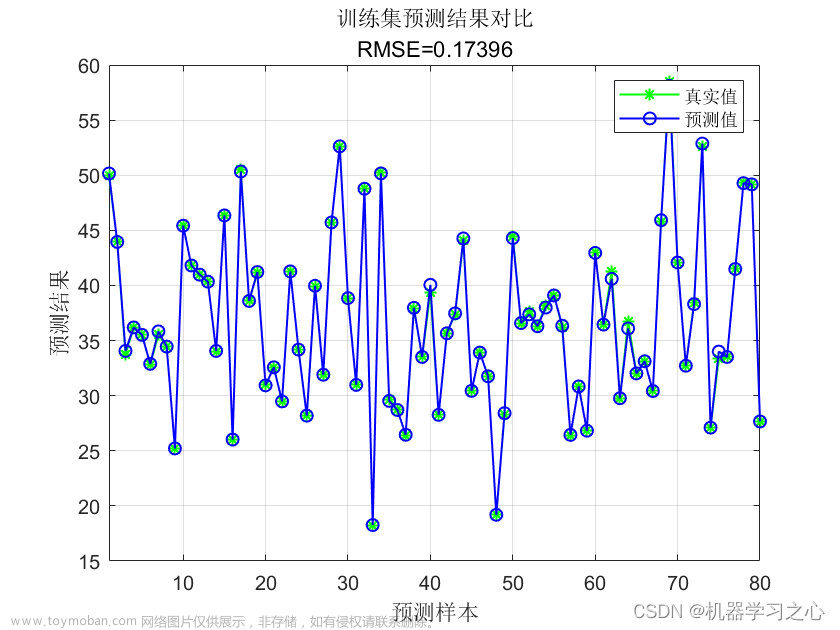
然后,我们使用拟合好的模型对测试数据进行预测,并计算预测结果的均方误差(MSE)和决定系数(R2)作为模型的评估指标。文章来源:https://www.toymoban.com/news/detail-504762.html
最后,我们打印了模型评估结果,包括均方误差和决定系数。请注意,这只是一个简单的示例,实际使用中可能需要根据具体需求进行参数调优和模型性能的进一步评估。文章来源地址https://www.toymoban.com/news/detail-504762.html
# 导入所需的库
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score
# 源数据
X = np.array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]]) # 特征矩阵
y = np.array([3, 7, 9, 11, 13]) # 目标向量
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建SVM回归模型
svr = SVR(kernel='linear', C=1.0)
# 拟合训练数据
svr.fit(X_train, y_train)
# 预测测试数据
y_pred = svr.predict(X_test)
# 计算模型评估指标
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# 打印结果
print("均方误差 (MSE): {:.2f}".format(mse))
print("决定系数 (R2): {:.2f}".format(r2))
到了这里,关于一个简单的使用支持向量机(SVM)进行回归预测的Python代码示例,包含了源数据和注释的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!