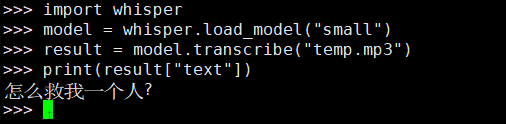
openai开源的语音转文字支持多语言在huggingface中使用例子。
目前发现多语言模型large-v2支持中文是繁体,因此需要繁体转简体。
后续编写微调训练例子
GitHub地址:
https://github.com/openai/whisper文章来源:https://www.toymoban.com/news/detail-505214.html
!pip install zhconv
!pip install whisper
!pip install tqdm
!pip install ffmpeg-python
!pip install transformers
!pip install librosa
from transformers import WhisperProcessor, WhisperForConditionalGeneration
import librosa
import torch
from zhconv import convert
import warnings
warnings.filterwarnings("ignore")
audio_file = f"test.wav"
#load audio file
audio, sampling_rate = librosa.load(audio_file, sr=16_000)
# # audio
# display.Audio(audio_file, autoplay=True)
# load model and processor
processor = WhisperProcessor.from_pretrained("openai/whisper-large-v2")
model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-large-v2")
tokenizer = WhisperProcessor.from_pretrained("openai/whisper-large-v2")
processor.save_pretrained("openai/model/whisper-large-v2")
model.save_pretrained("openai/model/whisper-large-v2")
tokenizer.save_pretrained("openai/model/whisper-large-v2")
processor = WhisperProcessor.from_pretrained("openai/model/whisper-large-v2")
model = WhisperForConditionalGeneration.from_pretrained("openai/model/whisper-large-v2")
tokenizer = WhisperProcessor.from_pretrained("openai/model/whisper-large-v2")
# load dummy dataset and read soundfiles
# ds = load_dataset("common_voice", "fr", split="test", streaming=True)
# ds = ds.cast_column("audio", datasets.Audio(sampling_rate=16_000))
# input_speech = next(iter(ds))["audio"]["array"]
model.config.forced_decoder_ids = processor.get_decoder_prompt_ids(language="zh", task="transcribe")
input_features = processor(audio, return_tensors="pt").input_features
predicted_ids = model.generate(input_features)
# transcription = processor.batch_decode(predicted_ids)
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
print(transcription)
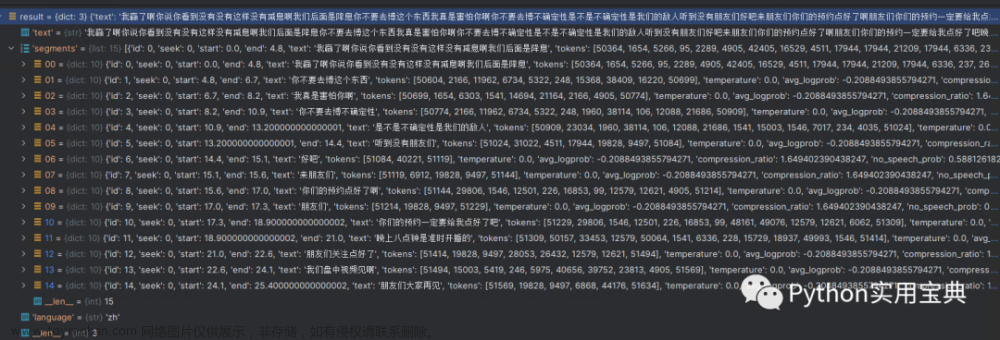
print('转化为简体结果:', convert(transcription, 'zh-cn'))
It is strongly recommended to pass the `sampling_rate` argument to this function. Failing to do so can result in silent errors that might be hard to debug.
['启动开始录音']
转化为简体结果: 启动开始录音
input_features = processor(audio, return_tensors="pt").input_features
predicted_ids = model.generate(input_features)
# transcription = processor.batch_decode(predicted_ids)
transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
print(transcription)
print('转化为简体结果:', convert(transcription, 'zh-cn'))
It is strongly recommended to pass the `sampling_rate` argument to this function. Failing to do so can result in silent errors that might be hard to debug.
['启动开始录音']
转化为简体结果: 启动开始录音
#长文本如下
#使用参考网站:https://huggingface.co/openai/whisper-large-v2
 文章来源地址https://www.toymoban.com/news/detail-505214.html
文章来源地址https://www.toymoban.com/news/detail-505214.html
到了这里,关于openai开源的whisper在huggingface中使用例子(语音转文字中文)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!