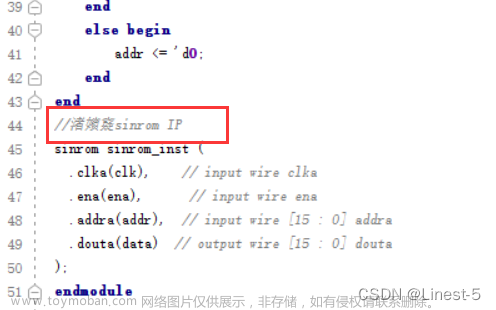
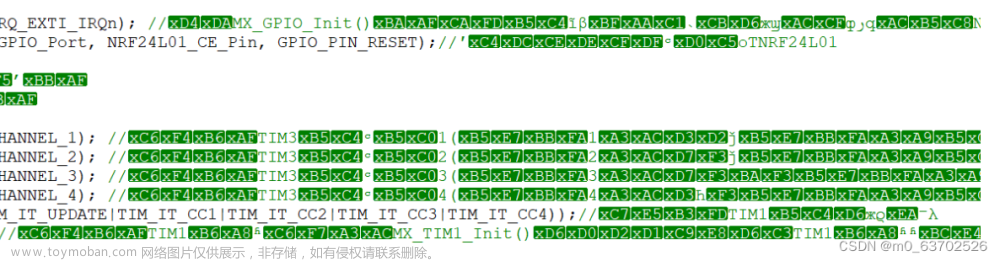
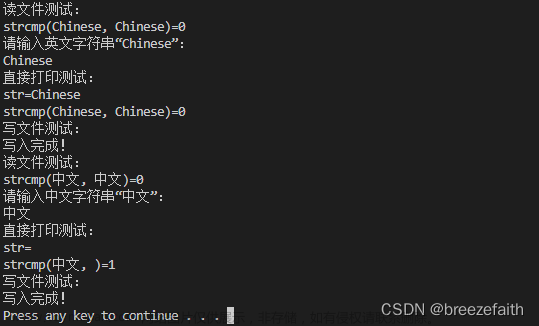
Vivado中文注释乱码,如下图。原因是Vivado 默认编辑器是ANSI编码 ,Notepad++中文编码一般是UTF-8,才会导致乱码。所以,写注释推荐用英文。

【解决办法】
方法一:用Windows自带的记事本打开,另存为,编码选择ANSI编码即可。

方法二:用SublimeText打开,File->Set File Encoding to -> Chinese Simplified(GBK)即可。
 文章来源:https://www.toymoban.com/news/detail-505715.html
文章来源:https://www.toymoban.com/news/detail-505715.html
【批量转换Verilog文件编码的Python脚本】文章来源地址https://www.toymoban.com/news/detail-505715.html
'''
遍历目录下所有文件,将UTF-8编码的verilog文件转换为GBK编码。
'''
import chardet
import os
import codecs
file_path = r'.\v_source_file\24_ddr3_test\ddr3_test\ddr3_test.srcs\sources_1\imports'
def findAllFile(base):
for root, ds, fs in os.walk(base):
for f in fs:
fullname = os.path.join(root, f)
yield fullname
def det_encoding(file_path):
with open(file_path, 'rb') as f:
s = f.read()
chatest = chardet.detect(s)
return chatest['encoding']
def convert(file, in_enc="GBK", out_enc="UTF-8"):
"""
该程序用于将目录下的文件从指定格式转换到指定格式,默认的是GBK转到utf-8
:param file: 文件路径
:param in_enc: 输入文件格式
:param out_enc: 输出文件格式
:return:
"""
in_enc = in_enc.upper()
out_enc = out_enc.upper()
try:
print("convert [ " + file.split('\\')[-1] + " ].....From " + in_enc + " --> " + out_enc )
f = codecs.open(file, 'r', in_enc)
new_content = f.read()
codecs.open(file, 'w', out_enc).write(new_content)
# print (f.read())
except IOError as err:
print("I/O error: {0}".format(err))
file_list = findAllFile(file_path)
for i in file_list:
if(i.split('.')[-1] == 'v'): # verilog file
file_encoding = det_encoding(i)
print('{}: {}'.format(file_encoding, i))
if(file_encoding=='utf-8'):
convert(i, in_enc='utf-8', out_enc='GBK')
到了这里,关于Vivado中文注释乱码的解决办法的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!