事件起因
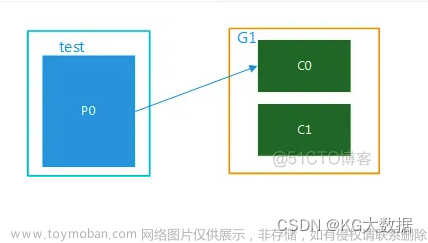
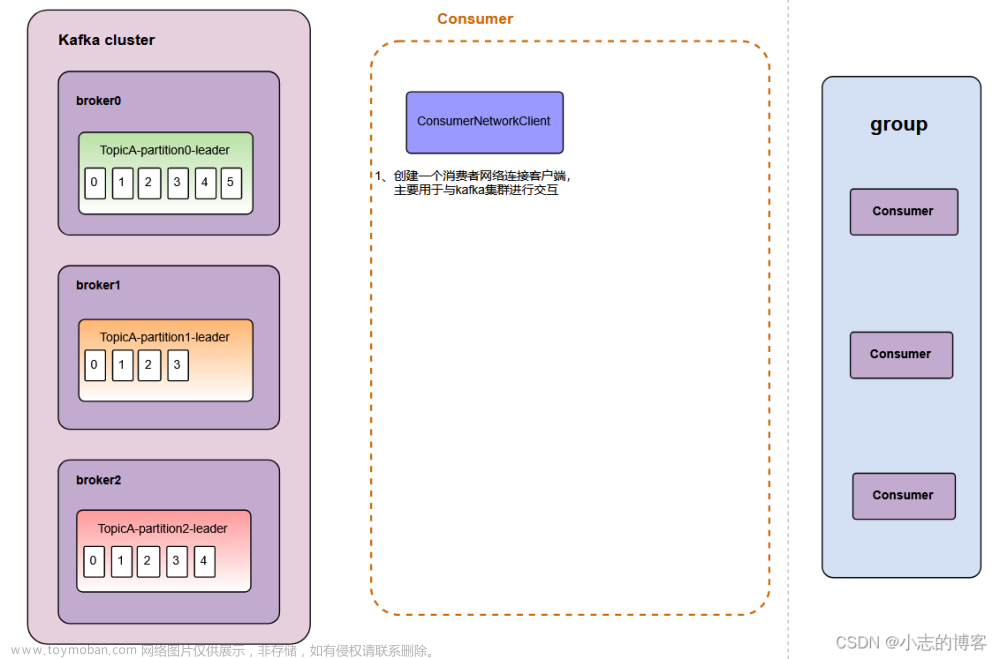
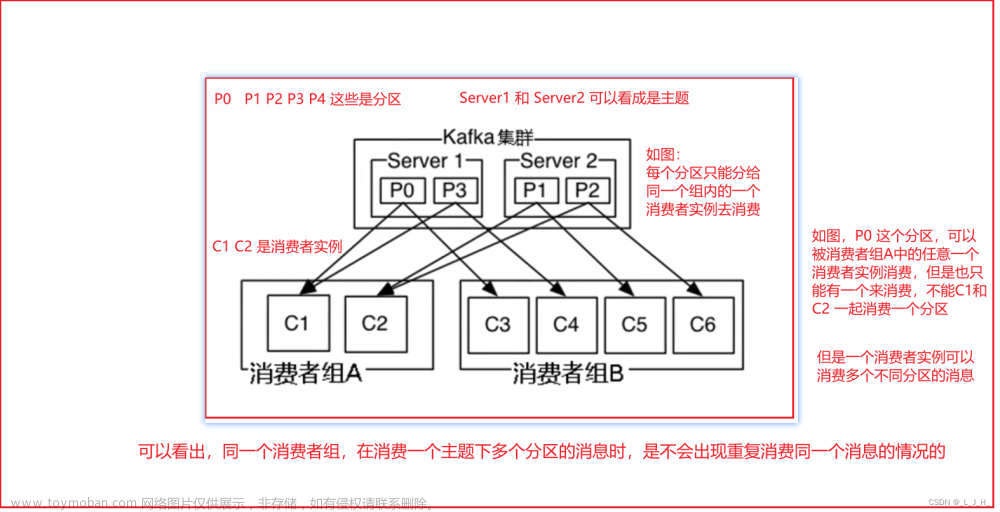
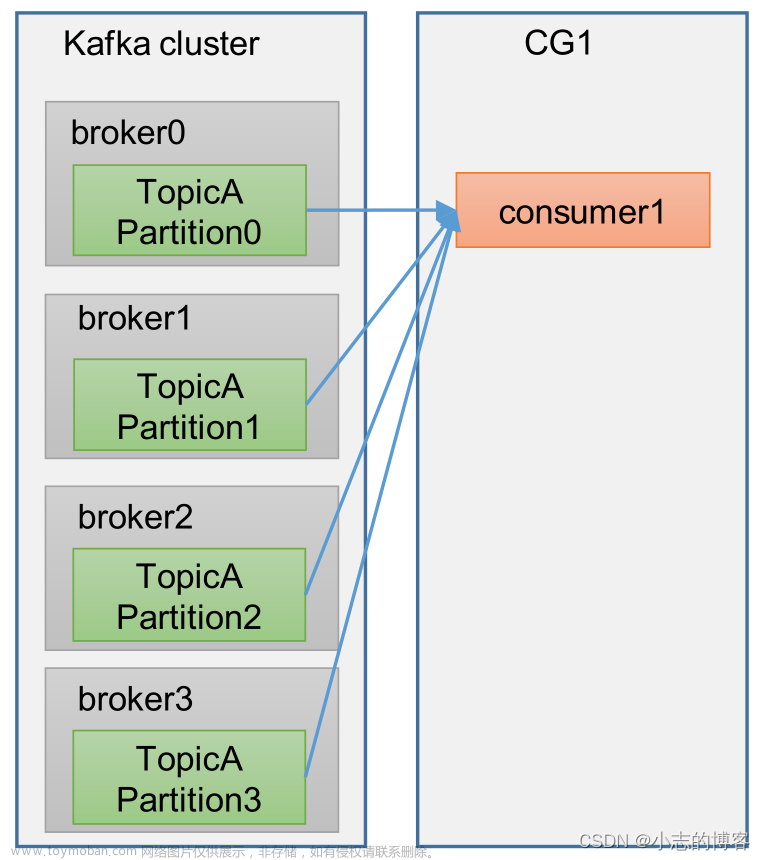
今天跑了一下kafka的示例demo,突然意识到一个问题。消费者拉取broker的消息时需要指定group id,而生产者将消息发送到broker的时候并不会指定group id,那么消费者的group id从哪里获取呢?
查询
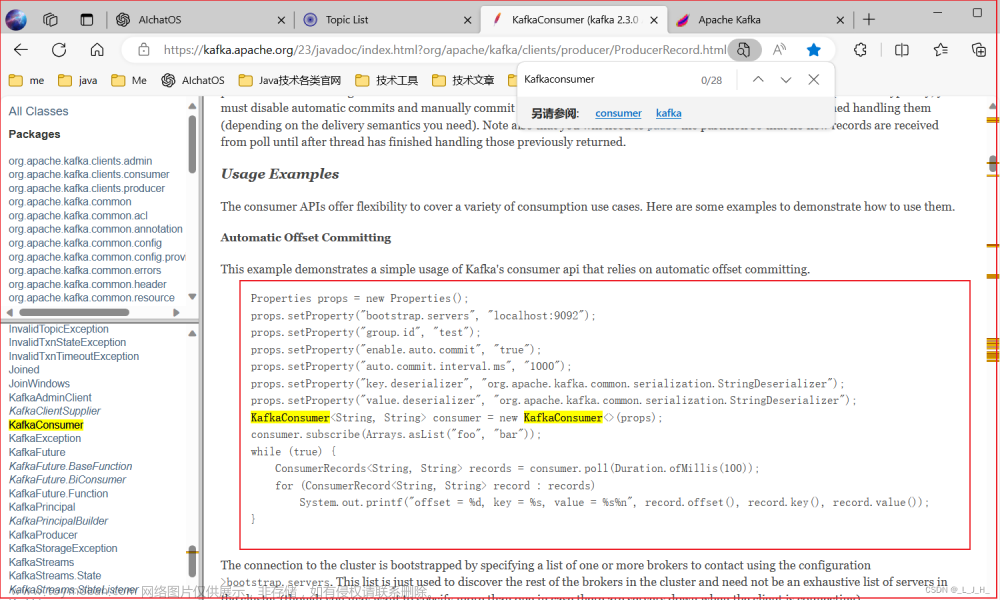
查阅我的这篇文章 kafka消费者 的3.1小节,

如果不配置该参数,则会抛出异常。为此,笔者验证了一下:

解决方案
去Kafka目录下的config目录,找到consumer.properties

打开该配置文件,赫然发现group id这个配置项。
 文章来源:https://www.toymoban.com/news/detail-505798.html
文章来源:https://www.toymoban.com/news/detail-505798.html
文章来源地址https://www.toymoban.com/news/detail-505798.html
到了这里,关于kafka消费者的group id从哪里获取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!