不知道各位网购的时候,是否会去留意商品评价,有些小伙伴是很在意评价的,看到差评就不想买了,而有些小伙伴则是会对差评进行理性分析,而还有一类人不在乎这个。
当然这都是题外话,咱们今天主要的目的是使用Python来爬取某东商品的评价,并保存到CSV表格。
1、数据采集逻辑
在进行数据采集之前,明确哪些数据为所需,制定数据Schema为爬取工作做出要求,并根据数据Schema制定出有针对性的爬取方案和采集逻辑。

2、数据Schema

3、数据爬取
抓取平台任一商品的评论信息,此案例抓取的商品是某一店铺的车厘子评价信息。
评论信息是由JS动态加载的,所以直接抓取商品详情页的URL并不能获得商品评论信息。因此我们需要先找到存放商品评价信息的文件,通过使用浏览器的开发者工具进行查找。
目标URL地址:

通过发现可知,productId为当前商品的商品Id,page为页码(从0开始),爬取该商品的所有评价信息只需要改变page参数即可。(商品评价页只显示前100页,所以page最大值为99)
导入库
import random import requests import json import re import csv import time import pymysql
文章来源:https://www.toymoban.com/news/detail-505916.html
对爬虫程序进行伪装
header = { 'refer': 'https: // item.jd.com /', 'cookie': '', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.50' }
抓取商品评论信息
将python程序伪装成浏览器后,就可以对评论信息进行爬取,在前面的分析中,productId和page为重要参数,在本案例中爬取的商品为车厘子,productId已确定,只需要对page进行更改即可达到需要。通过parms提交参数,使代码更有逻辑感并方便更改两个重要参数。

防止反爬,每爬取一页数据后,设置程序休眠环节。
# 程序休眠 time.sleep(random.randint(40, 80) * 0.1) print('第%d页正在爬取' % (page + 1)) ''' 爬取完成后,需要对页面进行编码,不影响后期的数据提取和数据清洗工作。 使用正则对数据进行提取,返回字符串。 字符串转换为json格式数据。 ''' res.encoding = 'gb18030' html = res.text data = re.findall('fetchJSON_comment98\((.*?)\);', html) data = json.loads(data[0]) # 将处理的数据进行解析 comments = data['comments'] print(data['comments'])
4、数据存储
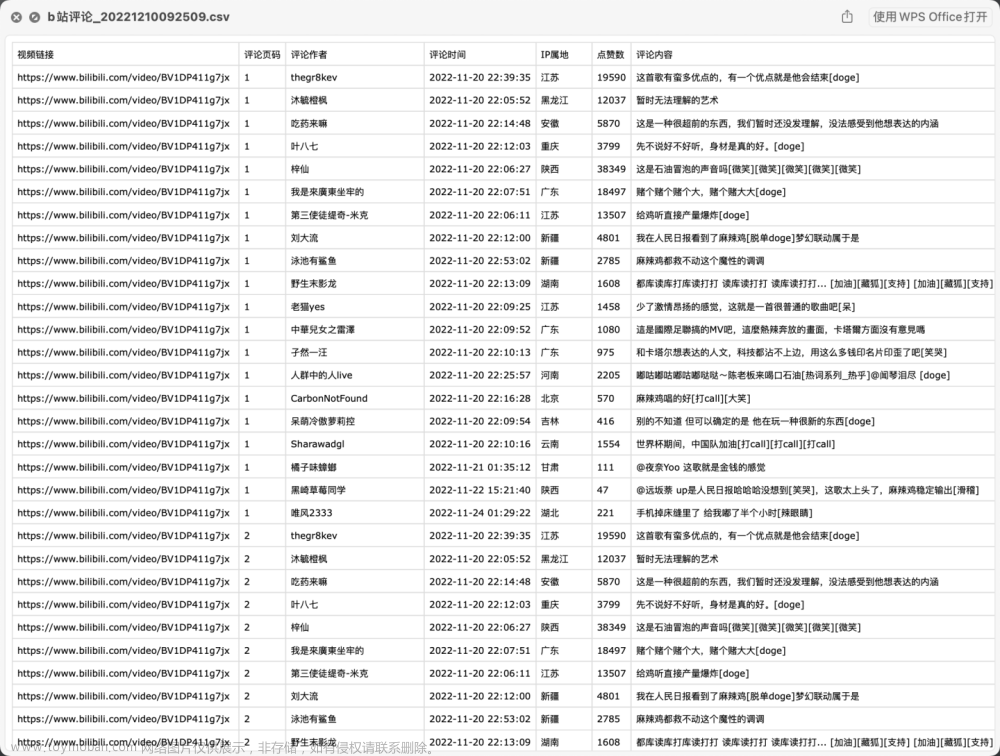
存储到csv
# 写入csv文件 f = open("evalution_data.csv", "a", newline='', encoding='gb18030') header = ["id", "content", "creationTime", "score", "productColor", "productSize"] # 创建一个DictWriter对象,第二个参数就是上面创建的表头 writer = csv.DictWriter(f, header) writer.writeheader() for i in comments: id = i['id'] content = i['content'] creationTime = i['creationTime'] score = i['score'] productColor = i['productColor'] productSize = i['productSize'] writer.writerow( {"id": id, "content": content, "creationTime": creationTime, "score": score, "productColor": productColor, "productSize": productSize}) f.close()
存储到数据库
# 写入数据库 conn = pymysql.connect(host='', user='', password='', port=, db='') cursor = conn.cursor() for i in comments: id = i['id'] content = i['content'] creationTime = i['creationTime'] score = i['score'] productColor = i['productColor'] productSize = i['productSize'] sql = "insert into evalution_data(id,content,creationTime,score,productColor,productSize) values('%d','%s','%s','%d','%s','%s')" cursor.execute(sql) conn.commit() # 我还专门录制了视频讲解,以及进行可视化分析,完整代码和视频讲解都在这个扣裙了:708525271 cursor.close() conn.close()
好了,今天的分享就到这里结束了,咱们下次见!文章来源地址https://www.toymoban.com/news/detail-505916.html
到了这里,关于当我用Python爬取了京东商品所有评论后发现....的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!