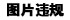一、Q-learning算法
Q-learning算法是强化学习算法中的一种,该算法主要包含:Agent、状态、动作、环境、回报和惩罚。Q-learning算法通过机器人与环境不断地交换信息,来实现自我学习。Q-learning算法中的Q表是机器人与环境交互后的结果,因此在Q-learning算法中更新Q表就是机器人与环境的交互过程。机器人在当前状态s(t)下,选择动作a,通过环境的作用,形成新的状态s(t+1),并产生回报或惩罚r(t+1),通过式(1)更新Q表后,若Q(s,a)值变小,则表明机器人处于当前位置时选择该动作不是最优的,当下次机器人再次处于该位置或状态时,机器人能够避免再次选择该动作action. 重复相同的步骤,机器人与环境之间不停地交互,就会获得到大量的数据,直至Q表收敛。QL算法使用得到的数据去修正自己的动作策略,然后继续同环境进行交互,进而获得新的数据并且使用该数据再次改良它的策略,在多次迭代后,Agent最终会获得最优动作。在一个时间步结束后,根据上个时间步的信息和产生的新信息更新Q表格,Q(s,a)更新方式如式(1):

式中:st为当前状态;r(t+1)为状态st的及时回报;a为状态st的动作空间;α为学习速率,α∈[0,1];γ为折扣速率,γ∈[0,1]。当α=0时,表明机器人只向过去状态学习,当α=1时,表明机器人只能学习接收到的信息。当γ=1时,机器人可以学习未来所有的奖励,当γ=0时,机器人只能接受当前的及时回报。
每个状态的最优动作通过式(2)产生:

Q-learning算法的搜索方向为上下左右四个方向,如下图所示:

Q-learning算法基本原理参考文献:
[1]王付宇,张康,谢昊轩等.基于改进Q-learning算法的移动机器人路径优化[J].系统工程,2022,40(04):100-109.
二、Q-learning求解移动机器人路径优化动态显示
基于强化学习(Reinforcement learning,RL)的移动机器人路径优化MATLAB
基于强化学习Qlearning的移动无人车路径规划MATLAB
基于MATLAB的移动扫地机器人路径规划之强化学习(Reinforcement learning,RL)
基于强化学习的移动无人车路径规划MATLAB文章来源:https://www.toymoban.com/news/detail-506122.html
基于强化学习(Reinforcement learning,RL)的扫地机器人路径规划MATLAB文章来源地址https://www.toymoban.com/news/detail-506122.html
到了这里,关于基于强化学习(Reinforcement learning,RL)的机器人路径规划MATLAB的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!