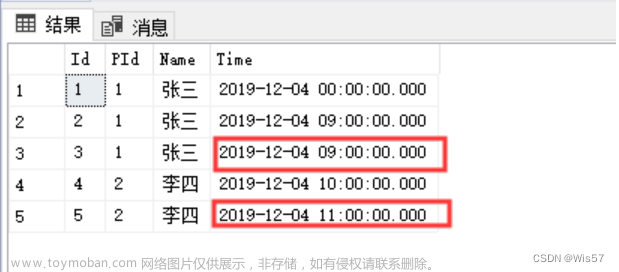
ES实现类似sql的group by后如何分页?
{
"query": {
...... //搜索条件
},
"aggs": {
"count": { // COUNT(*),统计GROUP BY后的总数
"cardinality": {
"field": "goods_id" // 因为我这里GROUP BY的字段是goods_id,所以就用goods_id来计数了
}
},
"goods_id": {
"terms": {
"field": "goods_id", // 选择GROUP BY的字段
"size": 20 // 取出20条GROUP BY的数据。数量应设置为sql中offset+limit的数量。注:其实es聚合操作不是很支持分页,于是只能先将数据取出,再对其做分页操作,可想而知页数越往后效率越低
},
"aggs": {
"group": {
"top_hits": {
"sort": [
{
"stock_num": {
"order": "desc" // GROUP BY的数据如何排序,这里是根据stock_num 降序排列
}
}
],
"_source": { // 对应SQL的SELECT
"includes": [
"goods_no" // SELECT的列
]
},
"size": 1 // es聚合时需要指定返回几条数据(即返回几条同一个goods_id的数据)我们做GROUP BY操作就只要写1就完事了
}
},
"r_bucket_sort": { // 分页操作
"bucket_sort": {
"sort": [],
"from": 0, // 对上面取出的20条数据分页,等价于SQL的OFFSET
"size": 10 // SQL的LIMIT
}
}
}
}
},
"size": 0, // 因为是做聚合操作,所以直接无视query筛选出的数据
"from": 0
}
案例:统计业务应用流量数据文章来源地址https://www.toymoban.com/news/detail-507284.html
curl -XGET /action*/_search
{
"from": 0,
"size": 0,
"query": {
"bool": {
"filter": [
{
"range": {
"occurredAt": {
"gte": "1659316790000",
"lt": "1659323990000"
}
}
}
],
"must": [
{
"term": {
"subtype.keyword": {
"value": "/datatrans/traffic"
}
}
}
]
}
},
"aggs": {
"count": {
"cardinality": {
"field": "applicationType.keyword"
}
},
"group_by_app_type": {
"terms": {
"field": "applicationType.keyword",
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"size": 40,
"order": [
{
"_count": "desc"
}
]
},
"aggs": {
"sum_bytes_sent": {
"sum": {
"field": "bytesSent"
}
},
"sum_bytes_received": {
"sum": {
"field": "bytesReceived"
}
},
"sum_total_flow": {
"sum": {
"script": {
"source": "(doc[\"bytesSent\"].value + doc[\"bytesReceived\"].value)"
}
}
},
"max_date": {
"max": {
"field": "occurredAt"
}
},
"min_date": {
"min": {
"field": "occurredAt"
}
},
"bucket_filed": {
"bucket_sort": {
"sort": [
{
"sum_bytes_sent": {
"order": "asc"
}
}
],
"from": 0,
"size": 40
}
}
}
}
}
}'
文章来源:https://www.toymoban.com/news/detail-507284.html
到了这里,关于ES聚合分页(group by分组后分页)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!