IK使用
IK有两种颗粒度的拆分:
-
ik_smart: 会做最粗粒度的拆分
-
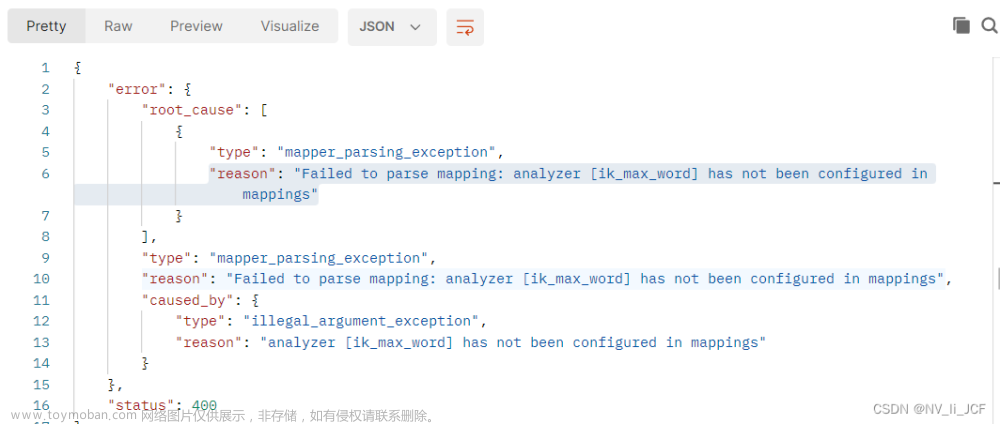
ik_max_word: 会将文本做最细粒度的拆分
GET /_analyze
{
"text":"中华人民共和国国徽",
"analyzer":"ik_smart"
}
ik_smart分词结果:
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "国徽",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 1
}
]
}
GET /_analyze文章来源:https://www.toymoban.com/news/detail-507799.html
{
"text":"中华人民共和国国徽",
"analyzer":"ik_max_word"
}
ik_max_word分词结果文章来源地址https://www.toymoban.com/news/detail-507799.html
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "国徽",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 9
}
]
}
到了这里,关于ES的ik分词器ik_smart和ik_max_word区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![[ES]mac安装es、kibana、ik分词器](https://imgs.yssmx.com/Uploads/2024/02/679665-1.png)




