目录
💥1 概述
📚2 问题
🎉3 运行结果
👨💻4 Python代码
💥1 概述
校园供水系统是校园公用设施的重要组成部分,学校为了保障校园供水系统的正常运行需要投入大量的人力、物力和财力。随着科学技术的发展,校园内已经普遍使用了智能水表,从而可以获得大量的实时供水系统运行数据。后勤部门希望基于这些数据,通过数学建模和数据挖掘及时发现和解决供水系统中存在的问题,提高校园服务和管理水平。
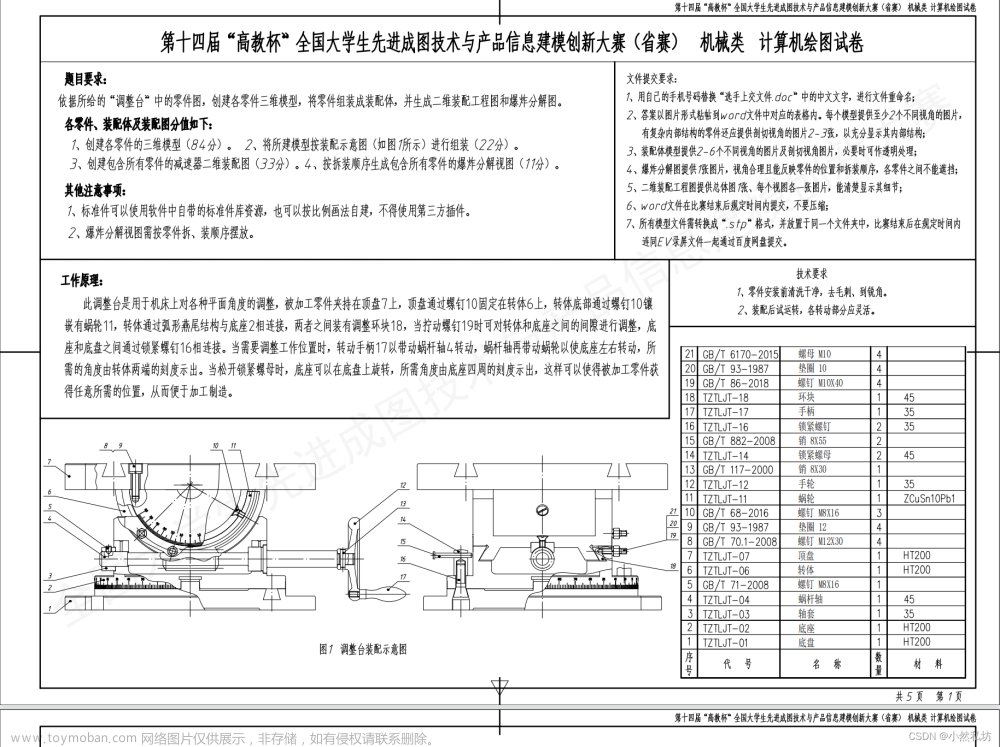
附件是某校区水表层级关系以及所有水表四个季度的读数(以一定时间为间隔,如15分钟)与相应的用水数据。请利用这些信息和数据,建立数学模型,讨论以下问题:
📚2 问题
1. 统计、分析各个水表数据的变化规律,并给出校园内不同功能区(宿舍、教学楼、办公楼、食堂等)的用水特征。
🎉3 运行结果


👨💻4 Python代码
'''1 读取四个季度数据:'''
import pandas as pd
shuju1=pd.read_excel('一季度.xlsx')
shuju2=pd.read_excel('二季度.xlsx')
shuju3=pd.read_excel('三季度.xlsx')
shuju4=pd.read_excel('四季度.xlsx')
print(shuju1)
#==查看一季度的统计描述:====
#可以得到一季度的最大值、最小值、平均值等信息
print(shuju1.describe())
#==为了快速浏览数据集,我们使用dataframe.info()功能===
print(shuju1.info())
#===查看缺失值======
print(shuju1.isnull().sum())
'''2 读取水表层:'''
shui_biao = pd.read_excel("水表层级.xlsx")
print(shui_biao)
#查看水表有哪些不同类型:
print(shui_biao['水表名'].unique())
#查看四个季度水表名数量:
print(len(shuju1['水表名'].unique()))
print(len(shuju2['水表名'].unique()))
print(len(shuju3['水表名'].unique()))
print(len(shuju4['水表名'].unique()))
#给数据表添加上具体季度更方便观察:
import numpy as np
# 合并数据
shuju1['季度'] = pd.Series(["一季度" for i in range(len(shuju1.index))])
shuju2['季度'] = pd.Series(["二季度" for i in range(len(shuju2.index))])
shuju3['季度'] = pd.Series(["三季度" for i in range(len(shuju3.index))])
shuju4['季度'] = pd.Series(["四季度" for i in range(len(shuju4.index))])
print(shuju1)
#添加合并:
shuju = shuju1.append([shuju2,shuju3,shuju4],ignore_index=True) # 添加合并
print(shuju)
#再查看表数量:
print(len(shuju['水表名'].unique()))
print(len(shui_biao['水表名'].unique()))
'''3 按照水表名分类,统计总用量'''
use_water = shuju.groupby(by='水表名')['用量'].sum() # 按照水表名分类,统计总用量
print(use_water)
#从高到低排序下:
use_water.sort_values(ascending=False)
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
#mpl.rcParams['font.sans-serif'] = ['Times New Roman'] #Times New Roman字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
import matplotlib; matplotlib.use('TkAgg')
#====根据使用绘制直方图:=====
use_water.plot.hist(histtype='bar', rwidth=0.5)
plt.savefig('可视化/0.1.png', dpi=300, bbox_inches="tight")
plt.show()
'''4 对这些功能区的类型进行分析:'''
# 全部水表
list_table_name = list(shuju['水表名'].unique()) #合并后的数据
'''4.1 功能区分类'''
#======4.1.1 找到所有宿舍的水表==========
list_home = [] #宿舍
list_teaching_build = [] #教学楼
list_teacher_build = [] #活动地方
for name in list_table_name.copy():
if name.find("学生宿舍") != -1 or name.find("留学生楼") != -1:
list_home.append(name)
list_table_name.remove(name)
print(list_home)
#=======4.1.2 同理,找到教学楼=========
for name in list_table_name.copy():
if name.find("XX") != -1 and name.find("楼") != -1:
print(name)
list_teaching_build.append(name)
list_table_name.remove(name)
print(list_teaching_build)
#======4.1.3 农业区=================
list_agritural = []
for name in list_table_name.copy():
if name.find("养殖") != -1 or name.find("养鱼") != -1 or name.find("大棚")!=-1 or name.find("花")!=-1:
list_agritural.append(name)
list_table_name.remove(name)
print(list_agritural)
#=======4.1.4 后勤===============
for name in list_table_name.copy():
if name.find("楼")!= -1:
list_teaching_build.append(name)
list_table_name.remove(name)
print(list_table_name)
#========类型添加上去·:================
list_backup = list_table_name
name_list = shuju['水表名'].tolist() #.tolist:将数组转化为列表
type_list = []
for name in name_list:
if name in list_backup:
type_list.append("后勤")
elif name in list_agritural:
type_list.append("农业")
elif name in list_home:
type_list.append('宿舍')
elif name in list_teaching_build:
type_list.append("活动地方")
else:
type_list.append('教学楼')
shuju['类型'] = pd.Series(type_list)
print(shuju)
'''4.2 不同类型的用量:'''
type_sum = shuju.groupby(by='类型')['用量'].sum()
print(type_sum)
#===对不同类型可视化:=====
type_sum.plot.barh(alpha=0.7)
df_group_two = shuju.groupby(by=['类型'])
i = 0
colors=['r','g','b','m','c']
plt.figure(figsize=(35, 35), dpi=100)
for types ,group in df_group_two:
i += 1
plt.subplot(3,2,i)
group.groupby(by='水表名').sum()["用量"].plot.barh(title=types,color=colors[i-1],alpha=.5)
plt.savefig('可视化/1不同类型可视化.png', dpi=300, bbox_inches="tight")
plt.show()
#分析完把合并后的数据保存起来:
shuju.to_csv('data1.txt',index=False) #data1.csv容易数据缺失,所以考虑txt
#shuju.to_xlsx('total.xlsx',index=False)
#按照时间聚合:
shuju['timeStamp'] = pd.to_datetime(shuju['采集时间'])
shuju.set_index("timeStamp", inplace=True)
data_quarter = shuju.resample("Q") # 时间聚合采样。.resample:重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
'''4.3 接下来分析每个季度、月份、天数、24小时变化:'''
#===4.3.1 季度变化规律:===================
data_quarter.sum()["用量"].plot.line(style="m>-.",alpha=0.5,title="用水量随着季度变化趋势") #Q:季度
plt.savefig('可视化/0.2用水量随着季度变化趋势.png', dpi=300, bbox_inches="tight")
plt.show()
#===4.3.2 月份变化规律:===================
data_month = shuju.resample('M').sum()["用量"].plot.line(style="c*-.",alpha=0.5,title="用水量随着月份变化趋势") #M:月份
plt.savefig('可视化/0.3用水量随着月份变化趋势.png', dpi=300, bbox_inches="tight")
plt.show()
'''添加具体时间:'''
shuju['hour'] = pd.to_datetime(shuju['采集时间']).dt.hour
shuju['day'] = pd.to_datetime(shuju['采集时间']).dt.day
print(shuju)
#====4.3.3 用水量一天随着小时变化规律:=============
shuju.groupby(by='hour').sum()['用量'].plot.line(style="gh-.",alpha=0.5,title="用水量随着时间变化趋势")
plt.grid()
plt.savefig('可视化/0.4用水量一天随着小时变化规律.png', dpi=300, bbox_inches="tight")
plt.show()
#=====4.3.4 一个月内用水量随着天数变化:=======
shuju.groupby(by='day').sum()['用量'].plot.line(style="rd-.",alpha=0.5,title="用水量随着天变化趋势")
plt.grid()
plt.savefig('可视化/0.5一个月内用水量随着天数变化.png', dpi=300, bbox_inches="tight")
plt.show()
'''4.4 不同区域的特征:'''
# 不同区域用水特征
#=======4.4.1 不同区域随着季度用水变化=======================
i = 0
styles=['*-.','-.','1-.','2-.','3-.']
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.resample("Q").sum()['用量'].plot.line(style=styles[i-1],color=colors[i-1],alpha=0.5,title="{}用水量随着季度变化趋势".format(index)) #四个季度
plt.savefig('可视化/2 不同区域随着季度用水变化.png', dpi=300, bbox_inches="tight")
plt.show()
#======4.4.2 不同区域随着月份用水变化===============
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.resample("M").sum()['用量'].plot.line(style=styles[i-1],color=colors[i-1],alpha=0.5,title="{}用水量随着月份变化趋势".format(index))
plt.savefig('可视化/3不同区域随月份变化.png', dpi=300, bbox_inches="tight")
plt.show()
#=====4.4.3 不同区域随着每月的天数用水变化==============
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.groupby(by='day').sum()['用量'].plot.line(style=styles[i-1],color=colors[i-1],alpha=0.5,title="{}用水量随着天数变化趋势".format(index))
plt.grid()
plt.savefig('可视化/4不同区域随着每月的天数用水变化.png', dpi=300, bbox_inches="tight")
plt.show()
#=====4.4.4 不同区域随着每天的时辰用水变化==============
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.groupby(by='hour').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着时辰变化趋势".format(index))
plt.grid()
plt.savefig('5.png', dpi=300, bbox_inches="tight")
plt.show()
#分析完毕~把数据保存起来:
shuju.to_csv('data2.txt',index=False) #data2.csv容易装不下数据,照成数据缺失
#shuju.to_xlsx('all.xlsx',index=False)
'''1 读取四个季度数据:'''
import pandas as pd
shuju1=pd.read_excel('一季度.xlsx')
shuju2=pd.read_excel('二季度.xlsx')
shuju3=pd.read_excel('三季度.xlsx')
shuju4=pd.read_excel('四季度.xlsx')
print(shuju1)
#==查看一季度的统计描述:====
#可以得到一季度的最大值、最小值、平均值等信息
print(shuju1.describe())
#==为了快速浏览数据集,我们使用dataframe.info()功能===
print(shuju1.info())
#===查看缺失值======
print(shuju1.isnull().sum())
'''2 读取水表层:'''
shui_biao = pd.read_excel("水表层级.xlsx")
print(shui_biao)
#查看水表有哪些不同类型:
print(shui_biao['水表名'].unique())
#查看四个季度水表名数量:
print(len(shuju1['水表名'].unique()))
print(len(shuju2['水表名'].unique()))
print(len(shuju3['水表名'].unique()))
print(len(shuju4['水表名'].unique()))
#给数据表添加上具体季度更方便观察:
import numpy as np
# 合并数据
shuju1['季度'] = pd.Series(["一季度" for i in range(len(shuju1.index))])
shuju2['季度'] = pd.Series(["二季度" for i in range(len(shuju2.index))])
shuju3['季度'] = pd.Series(["三季度" for i in range(len(shuju3.index))])
shuju4['季度'] = pd.Series(["四季度" for i in range(len(shuju4.index))])
print(shuju1)
#添加合并:
shuju = shuju1.append([shuju2,shuju3,shuju4],ignore_index=True) # 添加合并
print(shuju)
#再查看表数量:
print(len(shuju['水表名'].unique()))
print(len(shui_biao['水表名'].unique()))
'''3 按照水表名分类,统计总用量'''
use_water = shuju.groupby(by='水表名')['用量'].sum() # 按照水表名分类,统计总用量
print(use_water)
#从高到低排序下:
use_water.sort_values(ascending=False)
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
#mpl.rcParams['font.sans-serif'] = ['Times New Roman'] #Times New Roman字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
import matplotlib; matplotlib.use('TkAgg')
#====根据使用绘制直方图:=====
use_water.plot.hist(histtype='bar', rwidth=0.5)
plt.savefig('可视化/0.1.png', dpi=300, bbox_inches="tight")
plt.show()
'''4 对这些功能区的类型进行分析:'''
# 全部水表
list_table_name = list(shuju['水表名'].unique()) #合并后的数据
'''4.1 功能区分类'''
#======4.1.1 找到所有宿舍的水表==========
list_home = [] #宿舍
list_teaching_build = [] #教学楼
list_teacher_build = [] #活动地方
for name in list_table_name.copy():
if name.find("学生宿舍") != -1 or name.find("留学生楼") != -1:
list_home.append(name)
list_table_name.remove(name)
print(list_home)
#=======4.1.2 同理,找到教学楼=========
for name in list_table_name.copy():
if name.find("XX") != -1 and name.find("楼") != -1:
print(name)
list_teaching_build.append(name)
list_table_name.remove(name)
print(list_teaching_build)
#======4.1.3 农业区=================
list_agritural = []
for name in list_table_name.copy():
if name.find("养殖") != -1 or name.find("养鱼") != -1 or name.find("大棚")!=-1 or name.find("花")!=-1:
list_agritural.append(name)
list_table_name.remove(name)
print(list_agritural)
#=======4.1.4 后勤===============
for name in list_table_name.copy():
if name.find("楼")!= -1:
list_teaching_build.append(name)
list_table_name.remove(name)
print(list_table_name)
#========类型添加上去·:================
list_backup = list_table_name
name_list = shuju['水表名'].tolist() #.tolist:将数组转化为列表
type_list = []
for name in name_list:
if name in list_backup:
type_list.append("后勤")
elif name in list_agritural:
type_list.append("农业")
elif name in list_home:
type_list.append('宿舍')
elif name in list_teaching_build:
type_list.append("活动地方")
else:
type_list.append('教学楼')
shuju['类型'] = pd.Series(type_list)
print(shuju)
'''4.2 不同类型的用量:'''
type_sum = shuju.groupby(by='类型')['用量'].sum()
print(type_sum)
#===对不同类型可视化:=====
type_sum.plot.barh(alpha=0.7)
df_group_two = shuju.groupby(by=['类型'])
i = 0
colors=['r','g','b','m','c']
plt.figure(figsize=(35, 35), dpi=100)
for types ,group in df_group_two:
i += 1
plt.subplot(3,2,i)
group.groupby(by='水表名').sum()["用量"].plot.barh(title=types,color=colors[i-1],alpha=.5)
plt.savefig('可视化/1不同类型可视化.png', dpi=300, bbox_inches="tight")
plt.show()
#分析完把合并后的数据保存起来:
shuju.to_csv('data1.txt',index=False) #data1.csv容易数据缺失,所以考虑txt
#shuju.to_xlsx('total.xlsx',index=False)
#按照时间聚合:
shuju['timeStamp'] = pd.to_datetime(shuju['采集时间'])
shuju.set_index("timeStamp", inplace=True)
data_quarter = shuju.resample("Q") # 时间聚合采样。.resample:重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法。
'''4.3 接下来分析每个季度、月份、天数、24小时变化:'''
#===4.3.1 季度变化规律:===================
data_quarter.sum()["用量"].plot.line(style="m>-.",alpha=0.5,title="用水量随着季度变化趋势") #Q:季度
plt.savefig('可视化/0.2用水量随着季度变化趋势.png', dpi=300, bbox_inches="tight")
plt.show()
#===4.3.2 月份变化规律:===================
data_month = shuju.resample('M').sum()["用量"].plot.line(style="c*-.",alpha=0.5,title="用水量随着月份变化趋势") #M:月份
plt.savefig('可视化/0.3用水量随着月份变化趋势.png', dpi=300, bbox_inches="tight")
plt.show()
'''添加具体时间:'''
shuju['hour'] = pd.to_datetime(shuju['采集时间']).dt.hour
shuju['day'] = pd.to_datetime(shuju['采集时间']).dt.day
print(shuju)
#====4.3.3 用水量一天随着小时变化规律:=============
shuju.groupby(by='hour').sum()['用量'].plot.line(style="gh-.",alpha=0.5,title="用水量随着时间变化趋势")
plt.grid()
plt.savefig('可视化/0.4用水量一天随着小时变化规律.png', dpi=300, bbox_inches="tight")
plt.show()
#=====4.3.4 一个月内用水量随着天数变化:=======
shuju.groupby(by='day').sum()['用量'].plot.line(style="rd-.",alpha=0.5,title="用水量随着天变化趋势")
plt.grid()
plt.savefig('可视化/0.5一个月内用水量随着天数变化.png', dpi=300, bbox_inches="tight")
plt.show()
'''4.4 不同区域的特征:'''
# 不同区域用水特征
#=======4.4.1 不同区域随着季度用水变化=======================
i = 0
styles=['*-.','-.','1-.','2-.','3-.']
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.resample("Q").sum()['用量'].plot.line(style=styles[i-1],color=colors[i-1],alpha=0.5,title="{}用水量随着季度变化趋势".format(index)) #四个季度
plt.savefig('可视化/2 不同区域随着季度用水变化.png', dpi=300, bbox_inches="tight")
plt.show()
#======4.4.2 不同区域随着月份用水变化===============
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.resample("M").sum()['用量'].plot.line(style=styles[i-1],color=colors[i-1],alpha=0.5,title="{}用水量随着月份变化趋势".format(index))
plt.savefig('可视化/3不同区域随月份变化.png', dpi=300, bbox_inches="tight")
plt.show()
#=====4.4.3 不同区域随着每月的天数用水变化==============
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.groupby(by='day').sum()['用量'].plot.line(style=styles[i-1],color=colors[i-1],alpha=0.5,title="{}用水量随着天数变化趋势".format(index))
plt.grid()
plt.savefig('可视化/4不同区域随着每月的天数用水变化.png', dpi=300, bbox_inches="tight")
plt.show()
#=====4.4.4 不同区域随着每天的时辰用水变化==============
i = 0
plt.figure(figsize=(20, 20), dpi=100)
for index,group in shuju.groupby(by='类型'):
i += 1
plt.subplot(3,2,i)
group.groupby(by='hour').sum()['用量'].plot.line(style="r*-.",alpha=0.5,title="{}用水量随着时辰变化趋势".format(index))
plt.grid()
plt.savefig('5.png', dpi=300, bbox_inches="tight")
plt.show()
完整数据分享:
链接:https://pan.baidu.com/s/1SI8MZZy48e0f2Km3n7gatg
提取码:vquz
--来自百度网盘超级会员V2的分享文章来源:https://www.toymoban.com/news/detail-507803.html
#分析完毕~把数据保存起来:
shuju.to_csv('data2.txt',index=False) #data2.csv容易装不下数据,照成数据缺失
#shuju.to_xlsx('all.xlsx',index=False)文章来源地址https://www.toymoban.com/news/detail-507803.html
到了这里,关于2020年高教社杯全国大学生数学建模竞赛---校园供水系统智能管理(Python代码实现)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!