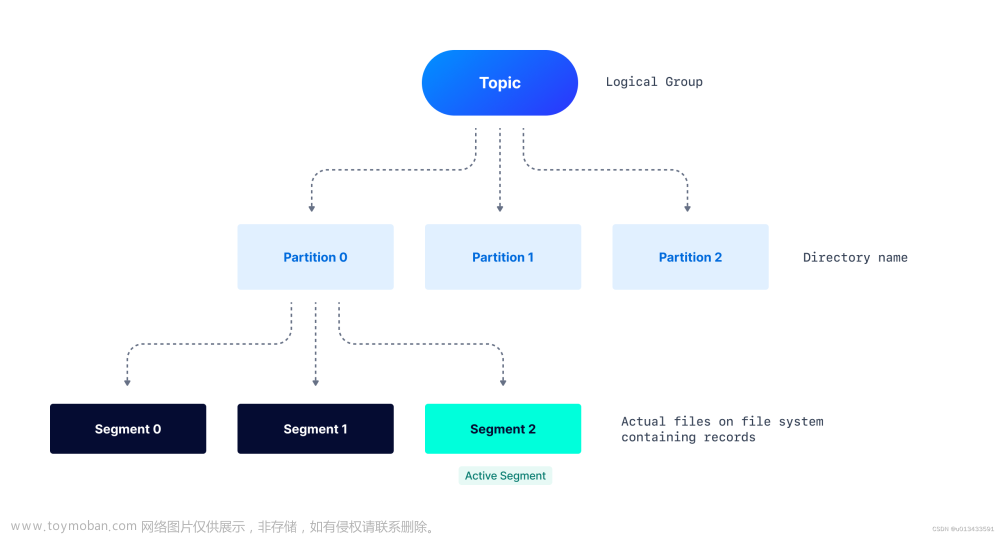
需求:
根据时间戳消费kafka topic数据并返回最近十条
思路:
通过时间戳获取各个分区的起始offset,每个分区都取10条,最后将所有分区的十条数据进行升序排序后,返回前十条
踩坑:
第一次写的时候,调用consumer.assign时,传参是所有的分区,consumer.seek也是设置的所有分区的起始offset,导致poll的时候,一直在拉一个分区的数据文章来源:https://www.toymoban.com/news/detail-508140.html
解决:
在同事的帮助下,每assign seek poll完一个分区需要的数据再继续下一个文章来源地址https://www.toymoban.com/news/detail-508140.html
代码:
public List<String> getTopicRecordWithTimestamp(String topic, Long startTimestamp, Integer size) {
long t0 = System.currentTimeMillis();
if (size == 0) {
size = 20;
}
Properties props = new Properties();
props.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, url);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "preview_topic_with_timestamp");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, STR_STRING_DESERIALIZER);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, STR_STRING_DESERIALIZER);
props.put(AdminClientConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);
props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, size);
List<String> kafkaRecords = Lists.newArrayList();
long t1 = System.currentTimeMillis();
try (final KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props)) {
long t2 = System.currentTimeMillis();
// 设置各个分区起始消费offset
List<PartitionInfo> partitionInfoList = consumer.partitionsFor(topic);
for(PartitionInfo partitionInfo : partitionInfoList) {
TopicPartition topicPartition = new TopicPartition(partitionInfo.topic(), partitionInfo.partition());
// assign partition
consumer.assign(Collections.singleton(topicPartition));
long offsetForTimestamp;
Map<TopicPartition, Long> timestampToSearch = Collections.singletonMap(topicPartition, startTimestamp);
Map<TopicPartition, OffsetAndTimestamp> offsetAndTimestamp = consumer.offsetsForTimes(timestampToSearch);
OffsetAndTimestamp result = offsetAndTimestamp.get(topicPartition);
if (result == null) {
offsetForTimestamp = consumer.endOffsets(Collections.singleton(topicPartition)).get(topicPartition);
} else {
offsetForTimestamp = result.offset();
}
consumer.seek(topicPartition, offsetForTimestamp);
// 若2s内无20条数据即可以返回
long start = System.currentTimeMillis();
long waitTime = 0L;
long allRecordsCount = 0L;
while (waitTime < Constant.NUM_3000 && allRecordsCount < size) {
waitTime = System.currentTimeMillis() - start;
ConsumerRecords<String, String> records = consumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
int recordPartition = record.partition();
if (allRecordsCount < size) {
allRecordsCount ++;
kafkaRecords.add(record.value());
}else {
break;
}
}
}
}
long t3 = System.currentTimeMillis();
//按时间戳升序返回
Collections.sort(kafkaRecords, new Comparator<KafkaRecordInfo>() {
@Override
public int compare(KafkaRecordInfo o1, KafkaRecordInfo o2) {
return (int)(o1.getTimestamp() - o2.getTimestamp());
}
});
if (kafkaRecords.size() > size) {
kafkaRecords = kafkaRecords.subList(0, size);
}
long t4 = System.currentTimeMillis();
log.info("total = {}, prepare = {}, create = {}, seek and poll = {}, sort = {}", t4 - t0, t1 - t0, t2 - t1,
t3 - t2, t4 - t3);
} catch (Exception e) {
log.warn("read message from kafka topic [{}] failed", topic, e);
}
return kafkaRecords;
}
到了这里,关于Kafka根据时间戳消费数据并返回最近的十条的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!