4 Stable Diffusion
Stable Diffusion 是由 Stability AI 开发的开源扩散模型。Stable Diffusion 可以完成多模态任务,包括:文字生成图像(text2img)、图像生成图像(img2img)等。
4.1 Stable Diffusion 的组成部分

Stable Diffusion 由两部分组成:
-
文本编码器:提取文本 prompt 的信息
-
图像生成器:根据文本 embedding 生成图像
- 图像信息创建器:多步扩散过程。步长是其中一个超参数
- 图像解码器:只在最后生成图像时运行一次
-
**文本编码器:**由一种特殊的 Transformer 编码器组成,例如:OpenAI 的 Clip。
-
图像信息创建器:由自编码器(通常是 U-Net)和噪音机制组成。
-
图像解码器:由自编码器的解码器组成。
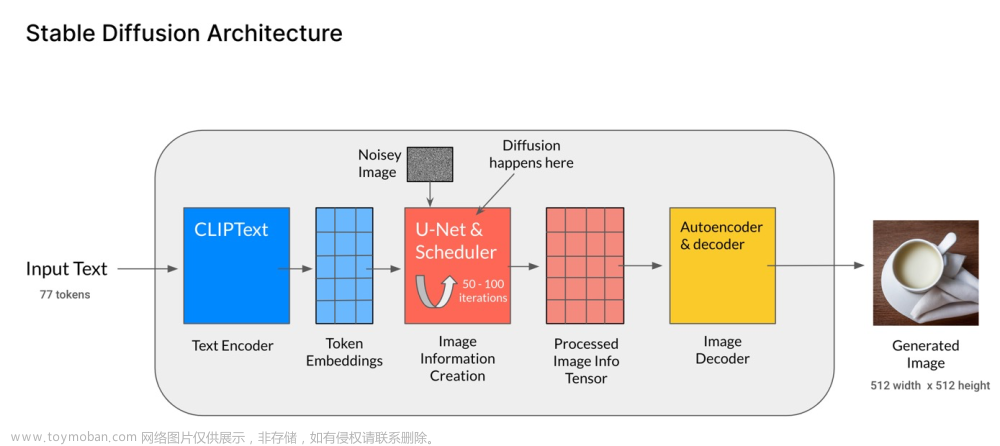
Stable Diffusion Pipeline:
-
Clip:文本信息编码
- 输入:文本
- 输出:77 token 的 embedding 向量,每个包含 768 维
-
U-Net + Noise Scheduler:逐渐把信息扩散至潜空间中
- 输入:文本 embedding 和由噪音组成的多维 tensor
- 输出:处理后的 tensor
- **自编码器的解码器:**使用扩散/处理后的信息生成图像
- 输入:经过处理的 tensor(shape: (4, 64, 64))
- 输出:生成图像(shape:(3, 512, 512))
4.2 扩散过程(图像信息创建器)
扩散过程发生在图像信息创建器中。该过程**一步步(step by step)**进行。初始的输入为文本 embedding 和一个随机的图像信息数组(也称为潜变量 latents)。每一步扩散的输入是潜变量,输出是信息进一步丰富的潜变量。最终的输出是一张图像。如图:

4.2.1 扩散过程的工作原理
扩散过程的原理其实是训练了一个基于 U-Net 和噪音等级机制(schedule)的噪音等级预测器。
扩散过程包含如下阶段:
- 数据集准备阶段:生成训练数据
- 输入:包含清晰图像的数据集、不同级别的噪音等级机制
- 流程:从数据集中抽样得到清晰图像,从噪音等级机制中抽样得到某种级别的噪音样本,把该噪音和图像融合
- 输出:带有某种等级的噪音图像
- 训练阶段:训练噪音等级预测器
- 输入:把上一阶段中的噪音图像和清晰图像作为输入数据,对应的噪音样本作为标签。
- 训练:采用 U-Net 作为神经网络,采用监督 loss 对输入进行学习
- 输出:某种等级的噪音样本
- 推断阶段:去噪并生成图像
- 输入:训练完成的 U-Net、某个噪音图像
- 推断:U-Net 输出该噪音图像的噪音等级(噪音样本)
- 输出:把噪音图像减去噪音样本,得到去噪图像。不断重复该过程,最终得到类似清晰图像的图像(并不一定完全相同)
生成图像的结果依赖于训练数据集。例如:Stable Diffusion 采用了带有艺术效果的 LAION Aesthetics 数据集,因此生成图像也具有艺术效果。
4.3 提速:在潜空间扩散
Stable Diffusion 的扩散过程是在潜空间中开展的,而不是整个图像像素,这样的压缩过程加速了图像生成的速度。
该压缩过程通过**自编码器(autoencoder)**实现。自编码器的编码器把图像压缩至潜空间,并用解码器根据压缩信息重建图像。因此,在前向扩散过程中,等级噪音应用于潜变量,而不是图像像素。所以 U-Net(噪音预测器)预测的噪音也是以潜变量的形式表示的。

前向扩散过程就是给清晰图像不断添加噪音的过程,也是生成数据集训练噪音预测器的过程,当噪音预测器训练完毕后,就可以运行反向抽样过程来去噪并重建图像。
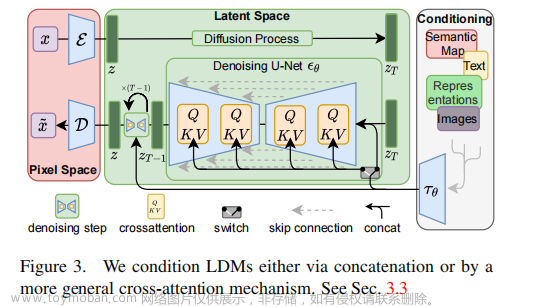
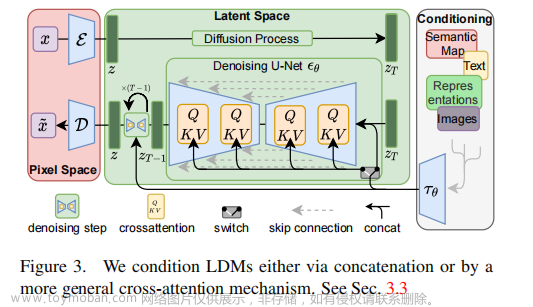
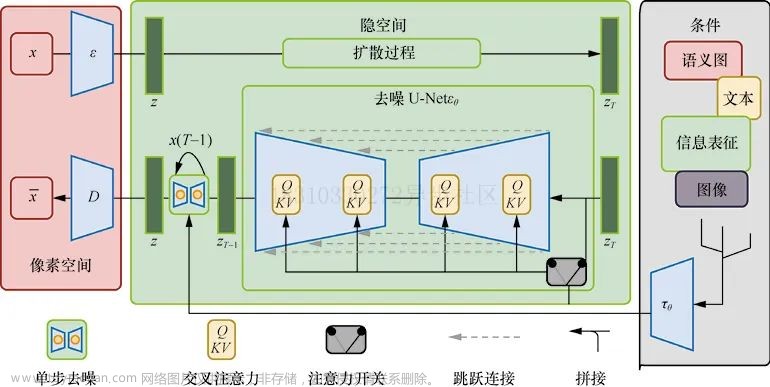
在 Stable Diffusion、LDM(潜变量扩散模型) 的论文中,该流程如下:

4.4 Transformer(文本编码器)
Transformer 模型根据文本输入生成 token embedding。
Stable Diffusion 的开源模型中使用的是 OpenAI 的 CLIP(基于 GPT),而其论文中使用的是 Google 的 BERT。两者都是 Transformer 的编码器(encoder)。
有工作指出:文本编码器的选择对于扩散模型的表现比图像生成器的选择更重要。
4.4.1 CLIP 的训练过程
CLIP 的训练流程为:
- 输入:训练数据为网页爬取的图像和其对应 HTML 标签属性 alt,也就是图像 + 注释(caption)
- 训练:CLIP 分别使用图像编码器和文本编码器把两种输入数据转化为图像 embedding 和文本 embedding,使用余弦相似度作为 loss 和标签 embeddings 进行比较并更新参数
- 输出:训练完毕的 CLIP 接收图像和文本描述并生成对应的 embeddings

4.5 加入文本数据
有了文本编码器后就要给扩散模型加入文本数据。
下面是有、无文本的扩散过程对比:

加入文本数据后,噪音预测器(U-Net)也要发生相应变化,主要是在每个 ResNet 块后添加注意力运算:文章来源:https://www.toymoban.com/news/detail-508406.html
 文章来源地址https://www.toymoban.com/news/detail-508406.html
文章来源地址https://www.toymoban.com/news/detail-508406.html
参考
- Ling Yang et al. “Diffusion Models: A Comprehensive Survey of Methods and Applications .” arXiv 2023.
- Jonathan Ho et al. “Denoising Diffusion Probabilistic Models”. NeurIPS 2020.
- Jiaming Song et al. “Denoising Diffusion Implicit Models”. ICLR 2021.
- Alex Nichol et al. “Improved Denoising Diffusion Probabilistic Models”. ICML 2021.
- Robin Rombach et al. “High-Resolution Image Synthesis with Latent Diffusion Models”. arXiv 2022.
- Prafulla Dhariwal et al. Diffusion “Models Beat GANs on Image Synthesis”. NeurIPS 2021.
- Jonathan Ho et al. “Classifier-Free Diffusion Guidance”. NeurIPS Workshop 2021.
- Tim Salimans et al. “Progressive Distillation for Fast Sampling of Diffusion Models”. ICLR 2022.
- Chenlin Meng et al. On Distillation of Guided Diffusion Models”. CVPR 2023.
到了这里,关于扩散模型 - Stable Diffusion的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!