一、实验目的
设计多周期非流水线MIPS处理器,包括:
-
完成多周期MIPS处理器的Verilog代码;
-
在Vivado软件上进行仿真;
-
编写MIPS代码验证MIPS处理器;
相关代码及资源的下载地址如下:
-
本实验的Vivado工程文件和实验文档:Multi-Cycle MIPS Processor.zip(272KB)
-
QtSpim 9.1.23和Vivado 2019.2的安装包:QtSpim & Vivado(184MB)
-
Vivado 2019.2安装教程:Vivado2019.2安装教程(2.9MB)
本文约54000字 (包括代码),创作不易,请不要白嫖 (doge),你的认可对我非常重要
如果你发现了错误,请在评论区留言,欢迎批评指正!
二、实验任务
(1)指令集
实验要求的多周期MIPS处理器应当包含的指令有:
add \ addi、sub、and、or \ ori、slt \ sltu、beq、bne、lw、sw、j;
在此基础上,补充设计的指令如下:
nor、nop、sll、srl、sra;
添加nor指令是因为“与”、“或”、“非”三个操作是一个完全集,而“非”操作可由nor指令完成(其中not为伪指令,用于增加程序可读性):
not ,$rd, $rs nor ,$rd, $rs, $0
添加三个移位指令是因为nop指令的十六进制表示是0x00000000,也是伪指令:
nop sll $0 $0 0
因此需要sll指令,那不妨把srl和sra指令也包括进来。
应当注意的是,MIPS指令集没有subi指令,因为它的功能可以由addi指令实现。
那么指令集为:
- R型指令:add、sub、and、or、nor、slt、sltu、sll、srl、sra、nop;
- I型指令:addi、ori、beq、bne、sw、lw;
- J型指令:j;
因此ALU需要实现add、sub、and、or、nor、slt、sltu、sll、srl、sra、addu、subu一共12种功能,所以ALUctr需要4位控制码;ALU需要能执行add、and、or、nor、slt、sll、srl、sra共8种操作,所以OPctr需要3位控制码;
(2)设计思路
多周期MIPS处理器由三个部分组成:存储器、控制器和数据通路
① 存储器
与单周期MIPS处理器不同,多周期MIPS处理器可以将指令存储器IM和数据存储器DM合并为一个存储器Memory。问题在于如何区分存储器中的指令和数据。
由于仿真测试时使用的测试代码条数较少(小于32条),进行的数据存储操作也较少,且数据存储的地址为80和84(分别是存储器的编号为20和21的存储单元,编号从0开始),我们可以设计64×32位的存储器,低32个存储单元用于存储数据,高32个存储单元用于存储指令。
同时我们可以将PC的初始值设为0x00400000,以避免指令存储地址与数据存储地址发生冲突。
如果传给存储器的地址MemAddr小于0x00000008=(32<<2)=128,说明要从存储器读出的是数据,存储单元编号为MemAddr[7:2];否则,说明要从存储器读出的是指令,存储单元编号为(MemAddr-0x00400000)[7:2]+32,也即MemAddr[7:2]+32。
写入时(即存储器写使能信号MemWriteEn=1时),存储单元编号为MemAddr[7:2]。
Memory.v 代码:
(约定:本文出现的所有代码均是Verilog或System Verilog,具体是哪种可由后缀确定)
`timescale 1ns / 1ps //Vivado默认的timescale
// Create Date: 2023/04/30 15:56:08
// Design Name: Memory
// Description: 存储器
//声明模块的输入和输出
module Memory(input clk,MemWriteEn,
input [31:0] MemAddr,MemWriteData,
output reg [31:0] MemReadData);
//定义一个64x32位的寄存器组memory,模拟RAM存储器
reg [31:0] memory[63:0];
//初始化指令,将十六进制指令文件ProgramFile1.dat中的指令存入memory,从第32号位置开始顺序存放
initial
begin
$readmemh("ProgramFile1.dat",memory,32);
end
//读
always @(*)
if(MemAddr[31:2] < 32)
MemReadData <= memory[MemAddr[7:2]];//读数据
else
MemReadData <= memory[((MemAddr - 32'h00400000)>>2)+32];//读指令
//写
always @(posedge clk)
if (MemWriteEn) memory[MemAddr[7:2]] <= MemWriteData;//写数据
endmodule
② 控制器 (译码器)
可以用微程序方式实现控制器。
其基本思想为:仿照程序设计的方法,将每条指令的执行过程用一个微程序表示,每个微程序由若干条微指令组成,每条微指令相当于有限状态机中的一个状态。有限状态机用于描述指令执行过程,由当前状态和操作码确定下一状态,每来一个时钟发生一次状态改变,不同状态输出不同的控制信号值,然后送到数据通路来控制指令的执行。
有限状态机如图所示:

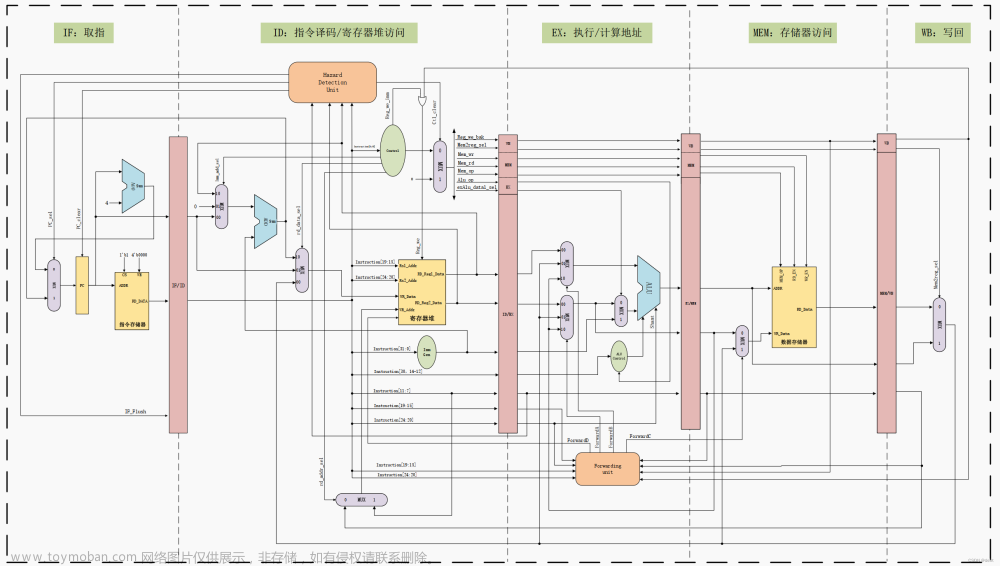
③ 数据通路
数据通路用于实现CPU内部的存储器、寄存器和运算部件之间的数据交换。
加入了控制信号的多周期数据通路如图所示:

Ⅰ. 数据通路中出现的控制信号的说明:
1. 写使能信号:MemWriteEn、PCWriteEn、IRWriteEn、RegWriteEn
存储器不属于数据通路,但需要写使能信号MemWriteEn控制;
因为程序计数寄存器PC、指令寄存器IR和寄存器文件RF只能在需要时写入新值,其他情况不能写入,故它们都需要由写使能信号控制,分别是PCWriteEn、IRWriteEn和RegWriteEn(寄存器文件的写入还需要OF标志信号:对需要判断溢出的算术运算类指令,当发生溢出时,禁止写结果到寄存器文件)
同时还要说明的是,我们只在IFetch和JumpFinish状态将PCWriteEn置为1,其中IFetch状态写入PC+4,使PC指向下一条指令;JumpFinish状态写入JumpPC,使PC指向跳转目标地址,再在下个IFetch状态 “+4” 使PC指向跳转目标地址的下一条指令;而对于分支指令的结束状态BeqFinish和BneFinish,只确定NextPC而不写入,留到下一个IFetch状态写入,并且 “+4” 指向该位置的下一条指令;其原因是(略陈固陋),在JumpFinish状态下,NextPC直接取JumpPC即可,得到的速度非常快,此周期NextPC几乎一直是正确的值,直接写入PC没问题;而BeqFinish和BneFinish状态下,NextPC需要等待ALU给出正确的ZF标志信号后才知道是取BranchPC还是PC,因此此周期NextPC需要等待一段时间才能取到正确的值,直接写入PC是不太妥当的。那么能否将JumpFinish的PCWriteEn也置为0,与BeqFinish和BneFinish统一起来呢?我觉得是可以,我尝试了一下(只需将Decoder.sv中JumpFinish的Controls从20'h4008f改成20'h0008f即可),结果几乎是一样的(存疑)
而存储器数据寄存器DR、寄存器A和B是临时寄存器,每来一个时钟信号都可改变它们的值,因此它们无须使用写使能信号。
2. 扩展器控制信号:ExtOp
ExtOp用于控制16位至32位扩展器Extender进行无符号扩展(0扩展)还是符号扩展。对于R型指令和进行逻辑运算的I型指令,16位立即数Imm16应进行无符号扩展,ExtOp应为0;对于进行算术运算的I型指令,则进行符号扩展,ExtOp为1;
3. 从存储器取指令还是取数据:IorD
IorD用于控制输入存储器的地址MemAddr的来源。MemAddr有两个来源:
- PC (用于取指令)
- 上一周期ALU的输出结果PreviousALUresult (即lw\sw指令的存储器地址,用于读写数据)
4. 是否是存储器数据写入寄存器文件:MemToReg
MemToReg用于控制寄存器文件写入数据RegWriteData的来源。RegWriteData有两个来源:
- 上一周期ALU的输出结果PreviousALUresult
- 从存储器读出的数据MemReadData
5. 目的寄存器是Rt还是Rd:RegDst
RegDst用于控制目的寄存器地址RegWriteAddr的来源。RegWriteAddr有两个来源:
- RtAddr (对于结果需要写入寄存器文件的I型指令,应选择RtAddr,RegDst应为0)
- RdAddr (对于R型指令,应选择RdAddr,RegDst应为1)
6. 控制SourceA来源:ALUsrcA
ALUsrcA用于控制ALU的A端输入数据SourceA的来源。SourceA有三个来源:
- PC (用于进行PC+4的计算,对应00)
- 上一周期从Rs寄存器读出的数据DataA (用于完成指令的ALU运算,对应01)
- 指令Instruction (用于提供shamt字段,供ALU执行移位操作,对应10)
7. 控制SourceB来源:ALUsrcB
ALUsrcB用于控制ALU的B端输入数据SourceB的来源。SourceB有四个来源:
- 上一周期从Rt寄存器读出的数据DataB (用于完成R型指令的ALU运算,对应00)
- 4 (用于进行PC+4的计算,对应01)
- 扩展得到的32位立即数Imm32 (用于完成非分支I型指令的ALU运算,对应10)
- {Imm32[29:0],00} (用于计算分支目标地址BranchPC,对应11)
8. 控制NextPC来源:PCsrc、PCWrCond
{PCsrc,Branch}联合控制新PC值NextPC的来源。NextPC有四个来源:
- PC+4 (对应{00,x}:IFetch状态)
- 分支目标地址BranchPC (对应{01,1}:分支且成功)
- 跳转目标地址JumpPC (对应{10,x}:跳转)
- PC (对应{01,0}:分支但失败;以及对应{11,x}:其他情况)
其中Branch = PCWrCond[1] & (PCWrCond[0] ^ ZF),用于表示分支成功与否。
这里用到了PCWrCond,用于区分非分支指令(对应00)、beq(对应10)和bne(对应11)。
9. ALU控制码:ALUctr
ALUctr用于控制ALU执行运算的类型,分别是add(0000)、sub(1000)、and(0001)、or(0010)、nor(0011)、slt(1101)、sltu(0101)、sll(0100)、srl(0110)、sra(0111)、addu(1111)、subu(1110);
要说明的是,虽然要设计的指令集里没有addu和subu指令,但有限状态机的某些状态需要ALU能够执行addu和subu操作:(并且对于其他一些不需要ALU操作的状态,默认ALU操作为addu)
- addu:IFetch、ID_RFetch、MemAddr
- 默认addu:MemFetch、LwFinish、SwFinish、RFinish
- subu:BeqFinsh、BneFinish
Ⅱ. 有限状态机各状态代表的指令执行过程:
约定控制信号的讨论顺序是:
- ExtOp、PCWriteEn、MemWriteEn、IRWriteEn、
- RegWriteEn、IorD、MemToReg、RegDst、
- ALUsrcA[1:0]、 ALUsrcB[1:0]、
- ALUctr[3:0]
约定字体颜色和标记的含义:
- 各状态的 "特征" 信号用红色标出;
- 顺延上一状态的信号,用下划线标出;
- 尽早稳定下一状态的信号,用红色字体和下划线标出;
-
取值任意的信号默认所有位均取为0;
1. (state 0、1) 取指令 (IFetch)、指令译码\取数 (ID\RFetch)
这两个状态是所有指令的公共操作,与指令类型无关。
0) 取指令状态 (IFetch)
- IRMemory[PC],PCPC+4
- ExtOp=1,PCWriteEn=1,MemWriteEn=0,IRWriteEn=1 //PC和IR都要发生写入
- RegWriteEn=0,IorD=0,MemToReg=0,RegDst=0 //从存储器取的是指令
- ALUsrcA=00,ALUsrcB=01 //SourceA=PC,SourceB=4
- PCsrc=00,PCWrCond=00 //NextPC=PC+4
- ALUctr=1111(addu) //执行addu操作,结果为PC+4
1) 指令译码\取数 (ID\RFetch)
- DataAR[IR[25:21]],DataBR[IR[20:16]]
- ALUresult = PC + {Imm32[29:0],00} (i.e. BranchPC)
- ExtOp=1,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0 //Imm16进行符号扩展
- RegWriteEn=0,IorD=0,MemToReg=0,RegDst=0
- ALUsrcA=00,ALUsrcB=11 //SourceA=PC,SourceB={Imm32[29:0],00}
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=1111(addu) //执行addu操作,进行“投机”计算得到分支目标地址
- //进行“投机”计算的想法是:反正译码时ALU是“空闲”的,不如拿来计算分支目标地址
- //使分支指令可以少一个“执行”状态,否则要在所谓的"BranchExecute"状态计算分支目标地址
- //结果为PC+{Imm32[29:0],00}=BranchPC
2. (state 2、3、4、5) lw\sw指令执行
2) 访存地址计算状态(MemAddr),lw\sw指令的公共状态
- MemAddr = DataA + SignExt(IR[15:0])
- ExtOp=1,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0 //Imm16进行符号扩展
- RegWriteEn=0,IorD=1,MemToReg=0,RegDst=0 //对存储器读\写的是数据
- ALUsrcA=01,ALUsrcB=10 //SourceA=DataA,SourceB=Imm32
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=1111(addu) //执行addu操作,结果为DataA + SignExt(IR[15:0]) = MemAddr
3) 存储器取数状态(MemFetch),lw指令特有
- RegWriteData = Memory[MemAddr]
- ExtOp=1,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- RegWriteEn=0,IorD=1,MemToReg=1,RegDst=0 //MemToReg置1,以便尽早稳定
- ALUsrcA=01,ALUsrcB=10
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=1111(addu) //ExtOp、IorD、ALUsrcA、ALUsrcB和ALUctr
- //顺延上一状态(state2 MemAddr),以继续保持访存地址信号的稳定
4) lw指令结束 --- 写入寄存器状态(LwFinish)
- R[IR[20:16]]RegWriteData
- ExtOp=1,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- RegWriteEn=1,IorD=1,MemToReg=1,RegDst=0
- ALUsrcA=01,ALUsrcB=10
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=1111(addu) //除RegWriteEn=1外,其他信号顺延上一状态(state3 MemFetch)
- lw指令执行结束
5) sw指令结束 --- 写入存储器状态(SwFinish)
- Memory[MemAddr]DataB
- ExtOp=1,PCWriteEn=0,MemWriteEn=1,IRWriteEn=0
- RegWriteEn=0,IorD=1,MemToReg=0,RegDst=0
- ALUsrcA=01,ALUsrcB=10
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=1111(addu) //除MemWriteEn=1外,其他信号顺延上一状态(state2 MemAddr)
- sw指令执行结束
3. (state 6、7) R型指令执行
6) R型指令运算 (RExecute)
- RegWriteData = (DataA \ Instruction) op DataB
- RegWriteAddr = RdAddr
- ExtOp=0,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- RegWriteEn=0,IorD=0,MemToReg=0,RegDst=1
- //寄存器文件写入数据为ALU结果,目的寄存器地址选择RdAddr
- ALUsrcA=??,ALUsrcB=00 //SourceA = (?) DataA\Instruction,SourceB=DataB
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=????(op) // " ? " 代表尚未确定
进一步,根据 funct 值确定ALUctr和ALUsrcA的值:
| funct |
100000 |
100010 |
100100 |
100101 |
100111 |
101010 |
101011 |
000000 |
000010 |
000011 |
| R型指令 |
add |
sub |
and |
or |
nor |
slt |
sltu |
sll |
srl |
sra |
| ALUctr |
0000 |
1000 |
0001 |
0010 |
0011 |
1101 |
0101 |
0100 |
0110 |
0111 |
| ALUsrcA |
01 |
10 |
||||||||
注:ALUsrcA=10时,SourceA=Instruction,执行移位操作,Instruction提供[10:6]的shamt字段
7) R型指令结束(RFinish)
- R[RegWriteAddr]RegWriteData
- ExtOp=0,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- RegWriteEn=1,IorD=0,MemToReg=0,RegDst=1
- ALUsrcA=??,ALUsrcB=00
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=????(op) //除RegWriteEn=1外,其他信号顺延上一状态(state6 RExecute)
- //为了简单起见,可以令RFinish状态的ALUsrcA=01,ALUctr=1111
- R型指令执行结束
4. (state 8、9、10) beq、bne和j指令执行
8) beq指令执行(BeqFinish)
- if(DataA - DataB = 0) then PCPreviousALUresult (i.e. BranchPC)
- ExtOp=1,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- //ExtOp顺延上一状态 (State1 ID\RFetch)
- RegWriteEn=0,IorD=0,MemToReg=0,RegDst=0
- ALUsrcA=01,ALUsrcB=00 //SourceA=DataA,SourceB=DataB
- PCsrc=01,PCWrCond=10 //如果DataA=DataB,分支成功,NextPC=BranchPC;
- //否则,NextPC=PC
- ALUctr=1110(subu) //执行subu操作,计算DataA - DataB,输出ZF标志信号
- beq指令执行结束
9) bne指令执行(BneFinish)
- if(DataA - DataB ≠ 0) then PCPreviousALUresult (i.e. BranchPC)
- //与BeqFinish状态相比只有PCWrCond=11一处不同
- ExtOp=1,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- //ExtOp顺延上一状态 (State1 ID\RFetch)
- RegWriteEn=0,IorD=0,MemToReg=0,RegDst=0
- ALUsrcA=01,ALUsrcB=00 //SourceA=DataA,SourceB=DataB
- PCsrc=01,PCWrCond=11 //如果DataA≠DataB,分支成功,NextPC=BranchPC;
- //否则,NextPC=PC
- ALUctr=1110(subu) //执行subu操作,计算DataA - DataB,输出ZF标志信号
- bne指令执行结束
10) j指令(JumpFinish)
- PCJumpPC = {PC[31:28],Target26,00}
- ExtOp=0,PCWriteEn=1,MemWriteEn=0,IRWriteEn=0
- RegWriteEn=0,IorD=0,MemToReg=0,RegDst=0
- ALUsrcA=00,ALUsrcB=00 //默认
- PCsrc=10,PCWrCond=00 //NextPC=JumpPC={PC[31:28],Target26,00}
- ALUctr=1111(addu) //默认
- j指令执行结束
5. (state 11、12、13、14)I型指令(addi、ori)执行
11) addi指令运算(AddiExecute)
- RegWriteData = DataA + SignExt(IR[15:0])
- RegWriteAddr = RtAddr
- ExtOp=1,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- //addi是算术运算,Imm16进行符号扩展
- RegWriteEn=0,IorD=0,MemToReg=0,RegDst=0
- //寄存器文件写入数据为ALU结果,目的寄存器地址选择RtAddr
- ALUsrcA=01,ALUsrcB=10 //SourceA=DataA,SourceB=SignExt(Imm16)
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=0000(add) //执行add操作,结果为DataA+SignExt(Imm16)
12) ori指令运算
- RegWriteData = DataA or UnsignExt(IR[15:0])
- RegWriteAddr = RtAddr
- //与AddiExecute状态的唯二区别是 ExtOp=0 和 ALUctr=0010
- ExtOp=0,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- //ori是逻辑运算,Imm16进行无符号扩展
- RegWriteEn=0,IorD=0,MemToReg=0,RegDst=0
- //寄存器文件写入数据为ALU结果,目的寄存器地址选择RtAddr
- ALUsrcA=01,ALUsrcB=10 //SourceA=DataA,SourceB=UnsignExt(Imm16)
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=0010(or) //执行or操作,结果为DataA or UnsignExt(Imm16)
13) addi指令结束(AddiFinish)
- R[RegWriteAddr]RegWriteData
- ExtOp=1,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- RegWriteEn=1,IorD=0,MemToReg=0,RegDst=0
- ALUsrcA=01,ALUsrcB=10
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=0000(add) //除RegWriteEn=1外,其他信号顺延上一状态(state11 AddiExecute)
- addi指令执行结束
14) ori指令结束(OriFinish)
- R[RegWriteAddr]RegWriteData
- ExtOp=0,PCWriteEn=0,MemWriteEn=0,IRWriteEn=0
- RegWriteEn=1,IorD=0,MemToReg=0,RegDst=0
- ALUsrcA=01,ALUsrcB=10
- PCsrc=11,PCWrCond=00 //NextPC=PC
- ALUctr=0010(or) //除RegWriteEn=1外,其他信号顺延上一状态(state12 OriExecute)
- ori指令执行结束
有限状态机各状态代表的指令执行过程讨论完毕。
三、具体设计及代码
(1) 存储器 (设计及Memory.v代码见“二、(2)设计思路 ①”部分)
(2) 控制器 (译码器)
Decoder.sv的代码:(注意后缀为sv,说明使用的是System Verilog)
(关于System Verilog与Verilog的区别,粗浅的理解是:System Verilog将Verilog里的wire和reg类型统一用logic类型表示,这样会方便一些;并且将Verilog的always语句细分成三种:
① 声明模块的输入和输出:
`timescale 1ns / 1ps
// Create Date: 2023/04/30 17:58:08
// Module Name: Decoder
// Description: 译码器
module Decoder(input logic clk ,Reset ,
input logic [5:0] op ,funct ,
output logic ExtOp ,PCWriteEn,MemWriteEn,IRWriteEn,
output logic RegWriteEn,IorD ,MemToReg ,RegDst ,
output logic [1:0] ALUsrcA,ALUsrcB ,PCsrc ,PCWrCond ,
output logic [3:0] ALUctr);② 首先定义一系列本地标识符(localparam),以增强代码可读性:
localparam IFetch = 4'b0000; //State 0,取指令+PC
localparam ID_RFetch = 4'b0001; //State 1,译码
localparam MemAddr = 4'b0010; //State 2,求存储器地址
localparam MemFetch = 4'b0011; //State 3,读存储器
localparam LwFinish = 4'b0100; //State 4,写寄存器文件
localparam SwFinish = 4'b0101; //State 5,写存储器
localparam RExecute = 4'b0110; //State 6,R型计算
localparam RFinish = 4'b0111; //State 7,R型写寄存器文件
localparam BeqFinish = 4'b1000; //State 8,beq
localparam BneFinish = 4'b1001; //State 9,bne
localparam JumpFinish = 4'b1010; //State 10,jump
localparam AddiExecute = 4'b1011; //State 11,addi计算
localparam OriExecute = 4'b1100; //State 12,ori计算
localparam AddiFinish = 4'b1101; //State 13,addi写寄存器文件
localparam OriFinish = 4'b1110; //State 14,ori写寄存器文件
localparam lw = 6'b100011; //op code for lw
localparam sw = 6'b101011; //op code for sw
localparam R = 6'b000000; //op code for R-type
localparam beq = 6'b000100; //op code for beq
localparam bne = 6'b000101; //op code for bne
localparam j = 6'b000010; //op code for j
localparam addi = 6'b001000; //op code for addi
localparam ori = 6'b001101; //op code for ori③ 当前状态逻辑(Current State Logic):
时钟上升沿处,如果Reset信号为1,当前状态重新设置为IFetch;否则,置为下一状态。
logic [3:0] CurrentState,NextState;
//Current State Logic
always_ff @(posedge clk or posedge Reset)
if (Reset) CurrentState <= IFetch;
else CurrentState <= NextState;④ 下状态逻辑(Next State Logic):
代码基于“二、(2)设计思路 ②”部分的有限状态机示意图,为了方便查看,也附在这里:
功能是根据当前状态和指令的op字段,确定下一状态。
//Next State Logic
always_comb
case(CurrentState)
IFetch: NextState = ID_RFetch;
ID_RFetch: case(op)
lw: NextState = MemAddr;
sw: NextState = MemAddr;
R: NextState = RExecute;
beq: NextState = BeqFinish;
bne: NextState = BneFinish;
j: NextState = JumpFinish;
addi: NextState = AddiExecute;
ori: NextState = OriExecute;
default: NextState = 4'bxxxx;//Never happen
endcase
MemAddr: case(op)
lw: NextState = MemFetch;
sw: NextState = SwFinish;
default: NextState = 4'bxxxx;//Safty Measure
endcase
MemFetch: NextState = LwFinish;
LwFinish: NextState = IFetch;//Next loop
SwFinish: NextState = IFetch;//Next loop
RExecute: NextState = RFinish;
RFinish: NextState = IFetch;//Next loop
BeqFinish: NextState = IFetch;//Next loop
BneFinish: NextState = IFetch;//Next loop
JumpFinish: NextState = IFetch;//Next loop
AddiExecute: NextState = AddiFinish;
OriExecute: NextState = OriFinish;
AddiFinish: NextState = IFetch;//Next loop
OriFinish: NextState = IFetch;//Next loop
default: NextState = 4'bxxxx;//Safty Measure
endcase⑤ 控制码逻辑(Control Code Logic)
生成每个状态对应的控制信号。
其中由于RExecute状态比较特殊(其ALUsrcA和ALUctr信号无法由op字段确定),因此加入信号RExecuteState来表示当前状态是否为RExecute状态,以便后续根据funct字段对其ALUsrcA和ALUctr信号进行确定。我的策略是:
- 用ALUsrcA0和ALUctr0表示根据op字段确定的ALUsrcA和ALUctr值; (对于RExecute状态,ALUsrcA和ALUctr信号无法由op字段确定,不妨令ALUsrcA0=11和ALUctr0=0000,反正从结果来看不会取到)
- 用ALUsrcA1和ALUctr1表示根据funct字段确定的ALUsrcA和ALUctr的值; (从结果来看,只有是RExecute状态,这部分值才会被取到)
- 如果是RExecute状态(即RExecuteState=1),则ALUsrcA和ALUctr取ALUsrcA1和ALUctr1; 如果是其他状态(即RExecuteState=0),则ALUsrcA和ALUctr取ALUsrcA0和ALUctr0;
//Control Code Logic
//加入信号RExecuteState来表示当前状态是否为RExecute状态
//以便后续根据funct字段对其ALUsrcA和ALUctr信号进行确定
logic RExecuteState;
always_comb
case(CurrentState)
RExecute: RExecuteState = 1;
default: RExecuteState = 0;
endcase
//用ALUsrcA0和ALUctr0表示根据op字段确定的ALUsrcA和ALUctr值
logic [3:0] ALUctr0,ALUctr1;
//用ALUsrcA1和ALUctr1表示根据funct字段确定的ALUsrcA和ALUctr的值
logic [1:0] ALUsrcA0,ALUsrcA1;
//由于要使用组合逻辑,故将13个控制信号整合为一个20位的控制信号Controls
//整合顺序与"二、设计思路 (3)数据通路"中控制信号的讨论顺序一致
logic [19:0] Controls;
assign {ExtOp,PCWriteEn,MemWriteEn,IRWriteEn,
RegWriteEn,IorD,MemToReg,RegDst,
ALUsrcA0,ALUsrcB,
PCsrc,PCWrCond,
ALUctr0} = Controls;
//ControlsRenew的含义就是对Controls的某些值进行更新,不用我多说了吧()
logic [5:0] ControlsRenew,ControlsRenew1;
assign {ALUsrcA,ALUctr} = ControlsRenew;
assign {ALUsrcA1,ALUctr1} = ControlsRenew1;第一个always语句中,用ALUsrcA0和ALUctr0表示根据op字段确定的ALUsrcA和ALUctr值:
always_comb
case(CurrentState)
IFetch: Controls = 20'h5010f;
ID_RFetch: Controls = 20'h803cf;//投机计算分支目标地址,解释见“二(2)③Ⅱ1. 1)”
MemAddr: Controls = 20'h846cf;
MemFetch: Controls = 20'h866cf;
LwFinish: Controls = 20'h8e6cf;
SwFinish: Controls = 20'ha46cf;
RExecute: Controls = 20'h014c0;
RFinish: Controls = 20'h094cf;
BeqFinish: Controls = 20'h8046e;
BneFinish: Controls = 20'h8047e;
JumpFinish: Controls = 20'h4008f;
AddiExecute: Controls = 20'h806c0;
OriExecute: Controls = 20'h006c2;
AddiFinish: Controls = 20'h886c0;
OriFinish: Controls = 20'h086c2;
default: Controls = 20'hxxxxx; //Never happen
endcase第二个always语句中,用ALUsrcA1和ALUctr1表示根据funct字段确定的ALUsrcA和ALUctr的值:
always_comb
case(funct)
6'b100000: ControlsRenew1 = 6'b010000; //add
6'b100010: ControlsRenew1 = 6'b011000; //sub
6'b100100: ControlsRenew1 = 6'b010001; //and
6'b100101: ControlsRenew1 = 6'b010010; //or
6'b100111: ControlsRenew1 = 6'b010011; //nor
6'b101010: ControlsRenew1 = 6'b011101; //slt
6'b101011: ControlsRenew1 = 6'b010101; //sltu
6'b000000: ControlsRenew1 = 6'b100100; //sll//注意三条移位指令
6'b000010: ControlsRenew1 = 6'b100110; //srl//ALUsrcA = 10
6'b000011: ControlsRenew1 = 6'b100111; //sra
default: ControlsRenew1 = 6'bxxxxxx; //Never happen
endcase最后如果当前状态是RExecute,则ALUsrcA和ALUctr采用ALUsrcA1和ALUctr;
否则,采用ALUsrcA0和ALUctr。
MUX2X6 get_ALUctr({ALUsrcA0,ALUctr0},ControlsRenew1,RExecuteState,ControlsRenew);模型结束:
endmodule各状态对应控制信号取值:(为空代表可以取任意值,默认取0)
| ExtOp |
PCWE |
MemWE |
IRWE |
RegWE |
IorD |
MemToReg |
RegDst |
ALUsrcA |
ALUsrcB |
PCsrc |
PCWrCond |
ALUctr |
ALL |
|
| IFetch |
1 |
1 |
00 |
01 |
00 |
00 |
1111 |
5010f |
||||||
| ID_IFetch |
1 |
00 |
11 |
11 |
00 |
1111 |
803cf |
|||||||
| MemAddr |
1 |
1 |
01 |
10 |
11 |
00 |
1111 |
846cf |
||||||
| MemFetch |
1 |
1 |
1 |
01 |
10 |
11 |
00 |
1111 |
866cf |
|||||
| LwFinish |
1 |
1 |
1 |
1 |
01 |
10 |
11 |
00 |
1111 |
8e6cf |
||||
| SwFinish |
1 |
1 |
1 |
01 |
10 |
11 |
00 |
1111 |
a46cf |
|||||
| RExecute |
1 |
?? |
00 |
11 |
00 |
???? |
014c0 |
|||||||
| RFinish |
1 |
1 |
01 |
00 |
11 |
00 |
0000 |
094c0 |
||||||
| BeqFinish |
1 |
01 |
00 |
01 |
10 |
1110 |
8046e |
|||||||
| BneFinish |
1 |
01 |
00 |
01 |
11 |
1110 |
8047e |
|||||||
| JumpFinish |
1 |
00 |
00 |
10 |
00 |
1111 |
4008f |
|||||||
| AddiExecute |
1 |
01 |
10 |
11 |
00 |
0000 |
806c0 |
|||||||
| OriExecute |
0 |
01 |
10 |
11 |
00 |
0010 |
006c2 |
|||||||
| AddiFinish |
1 |
1 |
01 |
10 |
11 |
00 |
0000 |
886c0 |
||||||
| OriFinish |
0 |
1 |
01 |
10 |
11 |
00 |
0010 |
086c2 |
根据funct字段对RExecute的ALUsrcA和ALUctr进行确定: (此表在前文出现过)
| funct |
100000 |
100010 |
100100 |
100101 |
100111 |
101010 |
101011 |
000000 |
000010 |
000011 |
| R型指令 |
add |
sub |
and |
or |
nor |
slt |
sltu |
sll |
srl |
sra |
| ALUctr |
0000 |
1000 |
0001 |
0010 |
0011 |
1101 |
0101 |
100 |
110 |
111 |
| ALUsrcA |
01 |
10 |
||||||||
ALUsrcA和ALUsrcB各值对应的SourceA和SourceB的来源:
| ALUsrcA |
ALUsrcB |
SourceA |
SourceB |
| 00 |
PC |
DataB |
|
| 01 |
DataA |
4 |
|
| 10 |
Instruction |
Imm32 |
|
| 11 |
{Imm32[29:0],00} |
||
PCsrc、PCWrCond和ZF各值对应的NextPC的来源:
(其中Branch = PCWrCond[1] & (PCWrCond[0] ^ ZF),Branch=1代表分支成功)
| PCsrc |
PCWrCond |
ZF |
Branch |
NextPC |
| 00 |
00 |
x |
0 |
PC+4 |
| 10(Jump) |
JumpPC |
|||
| 11 |
PC |
|||
| 01 (Branch) |
10(beq) |
0 |
0 |
PC |
| 1 |
1 |
BranchPC |
||
| 11(bne) |
0 |
1 |
BranchPC |
|
| 1 |
0 |
PC |
(3) 数据通路
数据通路的示意图可参考"二、(2)设计思路 ③",为了方便查看,也附在这里:
DataPath.sv 代码:
① 声明模块的输入和输出:
`timescale 1ns / 1ps
// Create Date: 2023/05/05 19:28:17
// Module Name: DataPath
// Description: 数据通路
//声明模块的输入和输出
module DataPath(input logic clk, Reset,
//MemReadData是从存储器读出的数据
input logic [31:0] MemReadData,
input logic ExtOp,PCWriteEn,MemWriteEn,IRWriteEn,
input logic RegWriteEn,IorD,MemToReg ,RegDst ,
input logic [1:0] ALUsrcA,ALUsrcB,PCsrc ,PCWrCond ,
input logic [3:0] ALUctr,
//Decoder产生的控制码里,只有MemWriteEn不在DataPath中
output logic [5:0] op, funct,
//MemWriteData是写入存储器的数据、MemAddr是写入或读取存储器的地址
output logic [31:0] MemWriteData,MemAddr,PC);② 准备阶段(Preparation):
分离出指令的各个字段,并生成一些数据:
op、funct、Imm16(并生成Imm32和{Imm32[29:0],00})、Target26(并生成JumpPC)、RsAddr、RtAddr、RdAddr。
//Preparation
//Instruction是指令;MemReadData_0是MDR(Memory Data Register)的输出端
logic [31:0] Instruction,MemReadData_0;
//指令寄存器IR,写入MemReadData,输出Instruction
InstructionRegister IR(clk,Reset,IRWriteEn,MemReadData,Instruction);
//存储器数据寄存器MDR,写入MemReadData,输出MemReadData_0
DataRegister MDR(clk,Reset,MemReadData,MemReadData_0);
//从Instruction中分离出op和funct字段,它们属于模块的输出,不用再次声明
assign {op,funct} = {Instruction[31:26],Instruction[5:0]};
//分离出Imm16字段,并根据ExtOp扩展成Imm32
//因为设计的指令中有ori,故必须添加ExtOp控制码
logic [15:0] Imm16;
assign Imm16 = Instruction[15:0];
logic [31:0] Imm32;
Extender EXT(Imm16,ExtOp,Imm32);
//分离出Target26字段,并生成跳转目标地址JumpPC
logic [25:0] Target26;
assign Target26 = Instruction[25:0];
logic [31:0] JumpPC;
assign JumpPC = {PC[31:28],Target26,2'b00};
//分离出RsAddr、RtAddr和RdAddr字段
logic [4:0] RsAddr,RtAddr,RdAddr;
assign {RsAddr,RtAddr,RdAddr} =
{Instruction[25:21],Instruction[20:16],Instruction[15:11]};
//不需要分离出移位位数shamt字段,执行移位指令时,只需将Instruction整体作为A端输入即可
//分离shamt字段的任务就交由ALU去做了③ 下址逻辑(Next PC Logic):
PC寄存器仅当PCWriteEn=1时写入(也即处于IFetch、JumpFinish状态时)其中IFetch状态写入PC+4,使PC指向下一条指令;JumpFinish状态写入JumpPC,使PC指向跳转目标地址,再在下个IFetch状态 “+4” 使PC指向跳转目标地址的下一条指令;而对于分支指令的结束状态BeqFinish和BneFinish,只确定NextPC而不写入(选择NextPC为BranchPC还是PC,送到PC寄存器的输入端),留到下一个IFetch状态写入,并且 “+4” 指向该位置的下一条指令;
//Next PC Logic
//NextPC是下条指令的地址,ALUresult是当前周期的ALU结果,PreviousALUresult是上周期的ALU结果
logic [31:0] NextPC,ALUresult,PreviousALUresult;
//程序计数寄存器(PC),PCWriteEn=1时,PC更新为NextPC
ProgramCounter PC_(clk,Reset,PCWriteEn,NextPC,PC);
//定义Branch(判断分支成功与否)、ZF(用于得到Branch)和3位联合控制码CombinedPCsrc
logic Branch, ZF;
logic [2:0] CombinedPCsrc;
//通过PCWrCond和ZF得到Branch
assign Branch = PCWrCond[1] & (PCWrCond[0] ^ ZF);
//将Branch和PCsrc联合成CombinedPCsrc
assign CombinedPCsrc = {Branch,PCsrc};
//根据3位联合控制码CombinedPCsrc选择NextPC的来源; 此模型为32位4路选择器
MUX4X32 NextPCsource(ALUresult,PreviousALUresult,JumpPC,PC,CombinedPCsrc,NextPC);④ 寄存器文件逻辑(Register File Logic):
寄存器文件的写入条件是(RegWriteEn & (!OF) ==1),即写使能为1且未发生溢出;
寄存器文件的写入地址RegWriteAddr根据RegDst选择是RtAddr还是RdAddr;(目的寄存器地址)
寄存器文件的写入数据RegWriteData根据MemToReg选择是PreviousALUresult还是MemReadData;
存储器的写入数据MemWriteData是DataB,即上一周期的RtData。
//Register File Logic
//RsData和RtData是寄存器文件中Rs和Rt寄存器的数据
//DataA和DataB相当于上一周期的RsData和RtData,是两个数据寄存器(DR)的输出端
//SourceA和SourceB是ALU的A端和B端输入数据
//OF是溢出标志信号,由ALU给出
logic [31:0] RsData,RtData,DataA,DataB,SourceA,SourceB;
logic OF;
//根据RegDst选择寄存器写入地址RegWriteAddr的来源(目的寄存器地址) (目的寄存器是Rt还是Rd)
logic [4:0] RegWriteAddr;
MUX2X5 get_RegWriteAddr(RtAddr,RdAddr,RegDst,RegWriteAddr);
//根据MemToReg选择寄存器写入数据RegWriteData的来源是PreviousALUresult还是MemReadData
logic [31:0] RegWriteData;
MUX2X32 get_RegWriteData(PreviousALUresult,MemReadData_0,MemToReg,RegWriteData);
//寄存器文件模块,写入条件是RegWriteEn & (!OF) == 1
RegisterFile RF(clk,RegWriteEn & (!OF),RegWriteAddr,RegWriteData,RsAddr,RtAddr,
RsData,RtData);
//两个数据寄存器,输入端分别为RsData和RtData,输出端分别为DataA和DataB
DataRegister Data_A(clk,Reset,RsData,DataA);
DataRegister Data_B(clk,Reset,RtData,DataB);
//存储器写入数据MemWriteData为DataB,即上周期的RtData;它是本模块的输出,不需要重复声明
assign MemWriteData = DataB;⑤ ALU逻辑(ALU Logic):
ALU的A端输入数据SourceA根据ALUsrcA选择是PC、DataA还是Instruction;
ALU的B端输入数据SourceB根据ALUsrcB选择是DataB、4、Imm32还是{Imm32[29:0],00};
再根据ALUctr,对SourceA和SourceB进行运算,得到ALUresult,并写入ALU结果寄存器;
存储器地址MemAddr根据IorD选择是PC还是PreviousALUresult。
//ALU Logic
//根据ALUsrcAALU的A端输入数据SourceA是PC、DataA还是Instruction
MUX4X32 get_SourceA(PC,DataA,Instruction,0,{1'b1,ALUsrcA},SourceA);
//根据ALUsrcB选择ALU的B端输入数据SourceB的来源是DataB、4、Imm32还是{Imm32[29:0],00}
MUX4X32 get_SourceB(DataB,4,Imm32,{Imm32[29:0],2'b0},{1'b1,ALUsrcB},SourceB);
//再根据ALUctr,对SourceA和SourceB进行运算,得到ALUresult,并写入ALU结果寄存器
ALU ArithLogicUnit(SourceA,SourceB,ALUctr,ALUresult,OF,ZF);
DataRegister get_PreviousALUresult(clk,Reset,ALUresult,PreviousALUresult);
//根据IorD选择存储器地址MemAddr的来源是PC还是PreviousALUresult,它是本模块的输出,不需重复声明
MUX2X32 get_MemAddr(PC,PreviousALUresult,IorD,MemAddr);endmodule(4) 数据通路中各组件的设计
① 寄存器
(i) 程序计数寄存器(PC)
Reset信号为1时,PC重置为0x00400000;
PCWriteEn信号为1时,用NextPC的值覆盖PC;
ProgramCounter.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/26 11:33:27
// Module Name: ProgramCounter
// Description: 程序计数器
//声明模块的输入和输出
module ProgramCounter (input clk,Reset,PCWriteEn,
input [31:0] NextPC,
output reg [31:0] PC);
//表达时序逻辑的always语句
always @(posedge clk, posedge Reset, posedge PCWriteEn)
//Reset信号为1时,PC重置为0x00400000;
if (Reset) PC <= 32'h00400000;
//PCWriteEn信号为1时,用NextPC的值覆盖PC;
else if (PCWriteEn) PC <= NextPC;
endmodule(ii) 指令寄存器(IR)
Reset信号为1时,CurrentInstruction重置为0x00000000;
IRWriteEn信号为1时,用NextInstruction的值覆盖CurrentInstruction;
InstructionRegister.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/26 10:53:34
// Module Name: InstructionRegister
// Description: 指令寄存器IR
//声明模块的输入和输出
module InstructionRegister (input clk,Reset,
input IRWriteEn,
input [31:0] NextInstruction,
output reg [31:0] CurrentInstruction);
//表达时序逻辑的always语句
always @(posedge clk,posedge Reset)
//Reset信号为1时,CurrentInstruction重置为0x00000000;
if (Reset) CurrentInstruction <= 32'h00000000;
//IRWriteEn信号为1时,用NextInstruction的值覆盖CurrentInstruction;
else if (IRWriteEn) CurrentInstruction <= NextInstruction;
endmodule(iii) 数据寄存器(MDR、DataA、DataB、PreviousALUresult)
Reset信号为1时,CurrentData重置为0x00000000;
没有写使能控制信号,每个时钟上升沿都用NextData的值覆盖CurrentData;
DataRegister.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/30 10:53:34
// Module Name: DataRegister
// Description: 数据寄存器MDR\A\B\PreviousALUresult
//声明模块的输入和输出
module DataRegister (input clk,Reset,
input [31:0] NextData,
output reg [31:0] CurrentData);
//表达时序逻辑的always表达式
always @(posedge clk,posedge Reset)
//Reset信号为1时,CurrentData重置为0x00000000;
if (Reset) CurrentData <= 32'h0;
//没有写使能控制信号,每个时钟上升沿都用NextData的值覆盖CurrentData;
else CurrentData <= NextData;
endmodule② 寄存器文件
写使能RegWriteEn为1时,向目的寄存器(由RegWriteAddr给定)写入RegWriteData,注意写使能信号在外部是(RegWriteEn & (!OF));(这样设计的RF原则上可向0号寄存器写入,但这并不重要)
从寄存器文件读数据时,如果寄存器地址不为0,则读出寄存器中的数据;否则,读出0;
RegisterFile.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/30 14:03:42
// Module Name: RegisterFile
// Description: 寄存器文件
//声明模块的输入和输出
module RegisterFile(input clk,
input RegWriteEn,
input [4:0] RegWriteAddr,
input [31:0] RegWriteData,
input [4:0] RsAddr,
input [4:0] RtAddr,
output [31:0] RsData,
output [31:0] RtData);
//定义32x32位寄存器组 (32个32位寄存器)
reg [31:0] RegFile[31:0];
//表达时序逻辑的always语句
always @(posedge clk)
//写使能RegWriteEn为1时,向目的寄存器(由RegWriteAddr给定)写入RegWriteData
//注意写使能信号在RF外部是(RegWriteEn & (!OF))
//这样设计的RF原则上可向0号寄存器写入,但这并不重要
if (RegWriteEn) RegFile[RegWriteAddr] <= RegWriteData;
//从寄存器文件读数据时,如果寄存器地址不为0,则读出寄存器中的数据;否则,读出0;
//问号表达式的顺序是先真后假:(condition) ? (ture) : (false),问号表达式也可以改写成always语句
assign RsData = (RsAddr != 0) ? RegFile[RsAddr] : 32'h0;
assign RtData = (RtAddr != 0) ? RegFile[RtAddr] : 32'h0;
endmodule
③ 运算逻辑部件(Arithmetric Logical Unit,ALU)
首先根据ALUctr,由ALU控制器ALUCONTROL生成SUBctr、OFctr、SIGctr、OPctr;
- SUBctr控制是加是减;
- OFctr控制是否判断溢出;
- SIGctr控制slt执行 "带符号整数比较小于" ,还是 "无符号整数比较小于";SLTresult是比较小于的1位结果,需要扩展成32位结果Y_slt
- OPctr用于控制最终结果取六个结果的哪一个;
SUBctr作为第0位进位进入32位并行进位加法器CLA32,计算出加减运算结果Y_addsub,并得到4个标志信号:Add_Overflow、Add_Sign、ZF和Add_Carry;OFctr表示是否进行溢出判断,OF=OFctr & Add_Overflow;
Y_and、Y_or和Y_nor由Vivado自带的与、或、非操作得到 (与门阵列、或门阵列和非门阵列);
SIGctr表示进行“无符号整数比较小于”还是“带符号整数比较小于”,得到1位比较结果SLTresult,再扩展成32位结果Y_slt;
取A[10:6]作为5位shamt进入移位器SHIFTER,得到移位结果Y_shift;
最后使用32位6路选择器MUX6X32,根据OPctr,对6个结果进行选择,得到ALUresult;
ALU.v的代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/12 11:07:52
// Module Name: ALU
// Description: ALU运算器
//声明模块的输入和输出
module ALU(input [31:0] A,B,
input [3:0] ALUctr,
output [31:0] ALUresult,
output OF,ZF);
//六类ALU运算的结果:加减、与、或、或非、整数比较小于、移位
wire [31:0] Y_addsub,Y_and,Y_or,Y_nor,Y_slt,Y_shift;
//需要根据ALUctr生成的控制码,SUBctr控制是加是减,OFctr控制是否判断溢出
//SIGctr控制slt执行带符号整数比较小于,还是无符号整数比较小于
//SLTresult是比较小于的1位结果,需要扩展成32位结果Y_slt
wire SUBctr,OFctr,SIGctr,SLTresult;
//OPctr用于控制最终结果取六个结果的哪一个
wire [2:0] OPctr;
//首先根据ALUctr,由ALU控制器ALUCONTROL生成SUBctr、OFctr、SIGctr、OPctr;
ALUCONTROL ALUcontrol(ALUctr,SUBctr,OFctr,SIGctr,OPctr);//ALU操作控制器
//SUBctr作为第0位进位进入32位并行进位加法器CLA32
//计算出加减运算结果Y_addsub
//并得到4个标志信号:Add_Overflow、Add_Sign、ZF和Add_Carry
//OFctr表示是否进行溢出判断,OF=OFctr & Add_Overflow;
CLA32 getY_addsub(A,B,SUBctr,Y_addsub,Add_Overflow,Add_Sign,ZF,Add_Carry);
assign OF = OFctr & Add_Overflow;
//Y_and、Y_or和Y_nor由Vivado自带的与、或、非操作得到(与门阵列、或门阵列和非门阵列)
assign Y_and = A & B;
assign Y_or = A | B;
assign Y_nor = ~(Y_or);
//SIGctr表示进行“无符号整数比较小于”还是“带符号整数比较小于”,得到1位比较结果SLTresult
MUX2X1 SetLessThan(SUBctr ^ Add_Carry,Add_Overflow ^ Add_Sign,SIGctr,SLTresult);
//1位结果SLTresult扩展成32位结果Y_slt
assign Y_slt = (SLTresult) ? 1 : 0;
//取A[10:6]作为5位shamt进入移位器SHIFTER,得到移位结果Y_shift;
SHIFTER getY_shift(B,A[10:6],OPctr[1],OPctr[0],Y_shift);
//最后使用32位6路选择器MUX6X32,根据OPctr,对6个结果进行选择,得到ALUresult;
MUX6X32 getALUresult(Y_addsub,Y_and,Y_or,Y_nor,Y_slt,Y_shift,OPctr,ALUresult);
endmodule(i) ALU控制器(ALUCONTROL)
根据ALUctr值生成相应的SUBctr、OFctr、SIGctr和OPctr信号。
ALUctr对应的SUBctr、OFctr、SIGctr和OPctr信号表:(空值默认为0)
| ALUctr |
对应操作 |
SUBctr |
OFctr |
SIGctr |
OPctr |
| 0000 |
add\addi |
1 |
000 |
||
| 1000 |
sub |
1 |
1 |
||
| 0001 |
and\andi |
001 |
|||
| 0010 |
or\ori |
010 |
|||
| 0011 |
nor\nori |
011 |
|||
| 0101 |
sltu |
1 |
0 |
101 |
|
| 1101 |
slt\slti |
1 |
1 |
||
| 0100 |
sll |
100 |
|||
| 0110 |
srl |
110 |
|||
| 0111 |
sra |
111 |
|||
| 1110 |
subu(beq\bne) |
1 |
000 |
||
| 1111 |
addu(lw\sw) |
ALUCONTROL.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/19 10:05:09
// Module Name: ALUCONTROL
// Description: ALU控制器
//声明模块的输入和输出
module ALUCONTROL(input [3:0] ALUctr,
output SUBctr,OFctr,SIGctr,
output [2:0] OPctr);
//由于要使用组合逻辑,故将4个控制信号整合为一个6位的控制信号Controls
reg [5:0] Controls;
assign {SUBctr,OFctr,SIGctr,OPctr} = Controls;
//表示组合逻辑的always语句
always @(*)
case(ALUctr)
4'b0000:Controls <= 6'b010000; //add\addi
4'b1000:Controls <= 6'b110000; //sub\subi
4'b0001:Controls <= 6'b000001; //and\andi
4'b0010:Controls <= 6'b000010; //or\ori
4'b0011:Controls <= 6'b000011; //nor\nori
4'b0101:Controls <= 6'b100101; //sltu
4'b1101:Controls <= 6'b101101; //slt\slti
4'b0100:Controls <= 6'b000100; //sll
4'b0110:Controls <= 6'b000110; //srl
4'b0111:Controls <= 6'b000111; //sra
4'b1110:Controls <= 6'b100000; //beq\bne(subu)
4'b1111:Controls <= 6'b000000; //lw\sw(addu)
endcase
endmodule(ii) 32位并行进位加法器(CLA32)
4位并行加法器CLA4的设计,参考《计算机组成与体系结构》(袁春风,第二版P72):


其中X和Y是加数,C代表进位,下标代表位号,则(X add Y) = X + Y + C;(" + "表示异或)
这里定义了两个辅助量P和G,其中P是X和Y的异或(P = X + Y),G是X和Y的与(G = XY);
X,Y分别代表ALU的A端输入和B端输入;
CLA4.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/12 10:12:06
// Module Name: CLA4
// Description: 4位并行进位加法器
//声明模块的输入和输出
module CLA4(input [3:0] A,B,
input Cin,
output Cout,
output [3:0] Y);
wire [3:0] p,g;//关于为什么要定义p,g两个辅助函数,参见课本第72页
assign p = A ^ B;//异或
assign g = A & B;//与
wire [3:0] P,G;//P[i]为p[0]到p[i]的连乘,G[i]=g[i]+ p[i]G[i-1]
//定义P和G是为了减少计算量,上一次计算的结果直接作为下一次计算的输入
//就跟秦九韶算法的想法类似
assign {P[0],G[0]} = {p[0],g[0]};//这部分代码就是实现前文的公式,注意区别p和P,以及g和G
assign {P[1],G[1]} = {p[1] & P[0],g[1] | (p[1] & G[0])};
assign {P[2],G[2]} = {p[2] & P[1],g[2] | (p[2] & G[1])};
assign {P[3],G[3]} = {p[3] & P[2],g[3] | (p[3] & G[2])};
wire [4:0] C;//各位进位
assign C[0] = Cin;
assign C[4:1] = G | (P & {4{Cin}});//公式参见课本第72页
assign Cout = C[4];//最高进位
assign Y = p ^ C[3:0];//结果
endmodule
带标志的4位并行加法器CLA4_Marked相较于CLA4,只需将最高两位进位异或得到OF并输出即可
增加的语句为:(当然,CLA4_Marked模块相较于CLA4还会增加一个输出OF)
assign OF = C[4] ^ C[3];串联7个CLA4和1个CLA4_Marked,就可以得到32位并行加法器CLA32。
(设计CLA_Marked的原因是:如果CLA32仅由8个CLA4构成,则CLA32获取的只有第4、8、12、16、20、24、28、32位的进位。因为OF是由最高两位进位异或得到的,所以应当由第8个CLA4运算得到OF并传给CLA32,因此要设计带标志的4位并行加法器CLA4_Marked,其相较于CLA4增加了OF输出)
CLA4_Marked.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/12 11:31:35
// Module Name: CLA4_Marked
// Description: 带溢出标志的4位并行进位加法器
//声明模块的输入和输出
module CLA4_Marked(input [3:0] A,B,
input Cin,
output Cout,
output [3:0] Y,
output OF); //相较于CLA4.v增加了输出OF
wire [3:0] p,g;//关于为什么要定义p,g两个辅助函数,参见课本第72页
assign p = A ^ B;//异或
assign g = A & B;//与
wire [3:0] P,G;//P[i]为p[0]到p[i]的连乘,G[i]=g[i]+ p[i]G[i-1]
//定义P和G是为了减少计算量,上一次计算的结果直接作为下一次计算的输入
//就跟秦九韶算法的想法类似
assign {P[0],G[0]} = {p[0],g[0]};//这部分代码就是实现前文的公式,注意区别p和P,以及g和G
assign {P[1],G[1]} = {p[1] & P[0],g[1] | (p[1] & G[0])};
assign {P[2],G[2]} = {p[2] & P[1],g[2] | (p[2] & G[1])};
assign {P[3],G[3]} = {p[3] & P[2],g[3] | (p[3] & G[2])};
wire [4:0] C;//各位进位
assign C[0] = Cin;
assign C[4:1] = G | (P & {4{Cin}});//公式参见课本第72页
assign Cout = C[4];//最高进位
assign Y = p ^ C[3:0];//结果
//溢出标志OF = Cn异或Cn-1
assign OF = C[4] ^ C[3];
endmodule
CLA32.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/12 10:11:39
// Module Name: CLA32
// Description: 32位并行进位加法器
//声明模块的输入和输出
module CLA32(input [31:0] A,B,
input Cin,
output [31:0] Y,
output OF,SF,ZF,CF);
//CLA32由7个CLA4和1个CLA4_Marked串联而成
//调用8次CLA4产生的8个进位存于Cout_set
wire [7:0] Cout_set;
//Cin即SUBctr, 当SUBctr = 1时执行减法, B需要与32‘hffffffff异或后再与A做加法
//为与SUBctr = 0时执行加法的情况统一起来, 定义Bxor = B ^ (32{SUBctr})
//这样SUBctr = 0时, Bxor = B; SUBctr = 1时,Bxor = B ^ 32'hffffffff;
wire [31:0] Bxor;
assign Bxor = B ^ {32{Cin}};
//串联! 前一个CLA4输出的进位作为下一个CLA4输入的进位
CLA4 add0(A[3:0],Bxor[3:0],Cin,Cout_set[0],Y[3:0]);
CLA4 add1(A[7:4],Bxor[7:4],Cout_set[0],Cout_set[1],Y[7:4]);
CLA4 add2(A[11:8],Bxor[11:8],Cout_set[1],Cout_set[2],Y[11:8]);
CLA4 add3(A[15:12],Bxor[15:12],Cout_set[2],Cout_set[3],Y[15:12]);
CLA4 add4(A[19:16],Bxor[19:16],Cout_set[3],Cout_set[4],Y[19:16]);
CLA4 add5(A[23:20],Bxor[23:20],Cout_set[4],Cout_set[5],Y[23:20]);
CLA4 add6(A[27:24],Bxor[27:24],Cout_set[5],Cout_set[6],Y[27:24]);
CLA4_Marked add7(A[31:28],Bxor[31:28],Cout_set[6],Cout_set[7],Y[31:28],OF);
//OF将由CLA4_Marked给出, CLA32只负责把OF传递给ALU
wire Cout = Cout_set[7];//最高进位
assign SF = Y[31];//符号标志
assign ZF = (Y) ? 0 : 1;//零标志(问号表达式先真后假)
assign CF = Cout;//进位标志
endmodule
(iii) 移位器(SHIFTER)
其实现思路为:
根据SA[4:0] (Shift Amount,i.e. shamt,移位位数)各位上的值来决定是否进行局部移位,一共5次,跨度分别为16、8、4、2、1位。SA[4:0]即32位指令的shamt字段,即Instruction[10:6]。
例如,对于SA[4],先根据Right和Arith计算出16位局部移位结果。当SA[4]=1时中间结果取16位局部移位结果;否则,中间结果为本次局部移位前的值;这轮中间结果再进行下一次局部移位(步长变为8),以此类推,5次后得到最终结果Y。
当然,从编程的角度来说,其实可以一次移位就到位,但从硬件实现的角度应该这样设计。
SHIFTER.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/12 08:55:39
// Module Name: SHIFTER
// Description: 32位移位器
//声明模块的输入和输出
module SHIFTER(input [31:0] A,
input [4:0] SA,//SA for Shift Amount,5位移位数
input Right,Arith,
//Right用于判别是右移还是左移;Arith用于判别是算术移位还是逻辑移位
output [31:0] Y);
//临时变量, 用于存储各次局部移位的中间结果
wire [31:0] t0,t1,t2,t3,t4,s0,s1,s2,s3,s4;
wire [31:0] l0,l1,l2,l3,l4,r0,r1,r2,r3,r4;
//生成16位的左移拼接量和右移拼接量
//左移拼接量left_shift为16位0
wire [15:0] left_shift = 16'b0;
//indicator是根据最高位(符号位)和Arith的值生成的指示值
//右移拼接量right_shift = 16{indicator};
wire indicator = A[31] & Arith;
wire [15:0] right_shift = {16{indicator}};
//4th 根据移位数的第四位SA[4]对A进行移位
assign l4 = {A[15:0],left_shift[15:0]};
assign r4 = {right_shift[15:0],A[15:0]};
MUX2X32 Mux4LandR(l4,r4,Right,t4);//根据Right选择左移还是右移,存入t4
MUX2X32 shift_on_4th(A,t4,SA[4],s4);//根据移位数的第四位SA[4]对A进行移位
//3rd 根据移位数的第三位SA[3]对s4进行移位
assign l3 = {s4[23:0],left_shift[7:0]};
assign r3 = {right_shift[7:0],s4[31:8]};
MUX2X32 Mux3LandR(l3,r3,Right,t3);//根据Right选择左移还是右移,存入t3
MUX2X32 shift_on_3rd(s4,t3,SA[3],s3);//根据移位数的第三位SA[3]对s4进行移位
//2nd 根据移位数的第二位SA[2]对s3进行移位
assign l2 = {s3[27:0],left_shift[3:0]};
assign r2 = {right_shift[3:0],s3[31:4]};
MUX2X32 Mux2LandR(l2,r2,Right,t2);//根据Right选择左移还是右移,存入t2
MUX2X32 shift_on_2nd(s3,t2,SA[2],s2);//根据移位数的第二位SA[2]对s3进行移位
//1st 根据移位数的第一位SA[1]对s2进行移位
assign l1 = {s2[29:0],left_shift[1:0]};
assign r1 = {right_shift[1:0],s2[31:2]};
MUX2X32 Mux1LandR(l1,r1,Right,t1);//根据Right选择左移还是右移,存入t1
MUX2X32 shift_on_1st(s2,t1,SA[1],s1);//根据移位数的第一位SA[1]对s2进行移位
//0th 根据移位数的第0位SA[0]对s1进行移位
assign l0 = {s1[30:0],left_shift[0]};
assign r0 = {right_shift[0],s1[31:1]};
MUX2X32 Mux0LandR(l0,r0,Right,t0);//根据Right选择左移还是右移,存入t0
MUX2X32 shift_on_0th(s1,t0,SA[0],s0);//根据移位数的第0位SA[1]对s1进行移位
//s0即为最终的移位结果;
assign Y = s0;
endmodule
(iv) 32位6路选择器(MUX6X32)
根据OPctr的值从6个运算结果中选取一个作为ALUresult。
MUX6X32.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/12 12:31:41
// Module Name: MUX6X32
// Description: 32位6路选择器
//声明模块的输入和输出
module MUX6X32(input [31:0] Y_addsub,Y_and,Y_or,Y_nor,Y_slt,Y_shift,
input [2:0] OPctr,
output reg [31:0] Y);
//表示组合逻辑的always表达式
//根据OPctr的值从6个运算结果中选取一个作为ALUresult
always @(*)
case(OPctr)
3'b000:Y <= Y_addsub; //add\addi\sub\subi\lw\sw\beq\bne\slt
3'b001:Y <= Y_and; //and\andi
3'b010:Y <= Y_or; //or\ori
3'b011:Y <= Y_nor; //nor\nori
3'b101:Y <= Y_slt; //slt\slti、sltu
3'b100:Y <= Y_shift; //逻辑左移sll
3'b110:Y <= Y_shift; //逻辑右移srl
3'b111:Y <= Y_shift; //算术右移sra
endcase
endmodule④ 其他
(i) 32位2路选择器MUX2X32
MUX2X32.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/12 08:26:05
// Module Name: MUX2X32
// Description: 32位2路选择器
//声明模块的输入和输出
module MUX2X32(input [31:0] A0,A1,
input S,
output reg [31:0] Y);
//表达组合逻辑的always表达式
//实现的功能其实是Y = (S) ? A1 : A0, 注意问号表达式是先真后假
always @(*)
case(S)
1'b0: Y <= A0;
1'b1: Y <= A1;
endcase
endmodule(1、5、6位2路选择器同理,我本该设计一个含参(使用parameter)的2路选择器,使用时设定选择器的参数,这是设计的失误,造成了代码的冗余)
含参的2路选择器MUX2.v代码:(参数为WIDTH,默认值为32)
`timescale 1ns / 1ps
// Create Date: 2023/05/17 13:17:23
// Module Name: MUX2
// Description: 使用参数的待定位2路选择器
//声明模块的输入和输出以及参数
module MUX2 #(parameter WIDTH = 32)
(input [WIDTH-1:0] A0,A1,
input S,
output reg [WIDTH-1:0] Y);
//表达组合逻辑的always表达式
//实现的功能其实是Y = (S) ? A1 : A0, 注意问号表达式是先真后假
always @(*)
case(S)
1'b0:Y <= A0;
1'b1:Y <= A1;
endcase
endmodule此含参模块的调用示例:
MUX2 (#32) (A0,A1,S,Y);
MUX2 (#5) (A0,A1,S,Y);
可以代替分别代替:
MUX2X32 (A0,A1,S,Y);
MUX2X5 (A0,A1,S,Y);
(ii) 16位扩展器Extender
首先生成无符号扩展和符号扩展的结果A0、A1,再根据ExtOp对它们进行2路选择。
Extender.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/26 11:12:35:
// Module Name: Extender
// Description:扩展器
//声明模块的输入和输出
module Extender(input [15:0] Imm16,
input ExtOp,
output [31:0] Imm32);
//首先生成无符号扩展和符号扩展的结果A0、A1,再根据ExtOp对它们进行2路选择
wire [31:0] A0,A1;
//无符号拓展结果
assign A0 = {16'b0,Imm16};
//符号拓展结果
assign A1 = {{16{Imm16[15]}},Imm16};
//根据ExtOp选择无符号拓展还是符号拓展, 即对上述两个结果进行2路选择
MUX2X32 MuxExtentionType(A0,A1,ExtOp,Imm32);
endmodule(iii) 32位4路选择器MUX4X32
得到SourceA需要3路选择,得到SourceB和NextPC需要4路选择。但前两者(SourceA和SourceB)由两位控制码ALUsrcA和ALUsrcB控制,后者(NextPC)用两位控制码PCsrc联合上一位控制码Branch进行控制。不妨统一用一个3位控制码的32位4路选择器MUX4X32完成。
模块MUX4X32的调用格式为:
MUX4X32 module_name(Data0,Data1,Data2,Data3,SourceControl,Data);SourceA、SourceB和NextPC的3位控制码分别为{1,ALUsrcA}、{1,ALUsrcB}和{Branch,PCsrc};
调用语句分别为:(位于DataPath.sv中)
MUX4X32 get_SourceA(PC,DataA,Instruction,0,{1'b1,ALUsrcA},SourceA);MUX4X32 get_SourceB(DataB,4,Imm32,{Imm32[29:0],2'b0},{1'b1,ALUsrcB},SourceB);MUX4X32 NextPCsource(ALUresult,PreviousALUresult,JumpPC,PC,{Branch,PCsrc},NextPC);MUX4X32.v代码:
`timescale 1ns / 1ps
// Create Date: 2023/04/30 12:31:41
// Module Name: MUX4X32
// Description: 32位4路选择器
//声明模块的输入和输出
module MUX4X32(input [31:0] Data0,Data1,Data2,Data3,
input [2:0] SourceControl,
output reg [31:0] Data);
//表示组合逻辑的always语句
//SourceA、SourceB和NextPC的3位控制码分别为{1,ALUsrcA}、{1,ALUsrcB}和{Branch,PCsrc};
//也即SourceA和SourceB的选择实际只使用前4个case;
//而NextPC的选择用到全部的8个case, 其中第2个和第6个比较特殊, 对应分支指令成功和失败两种情况
//对于非分支指令, 前一位控制码Branch是没有影响的, 因此第1、5,第3、7,第4、8的case都是两两相等的
always @(*)
case(SourceControl)
3'b100:Data <= Data0;
3'b101:Data <= Data1;//对于NextPC,这里是分支成功的情况
3'b110:Data <= Data2;
3'b111:Data <= Data3;
3'b000:Data <= Data0;
3'b001:Data <= Data3;//attention!这里是分支失败的情况
3'b010:Data <= Data2;
3'b011:Data <= Data3;
endcase
endmodule(5) 最终设计文件集(Design Sources)是这样的:
说明如下:
Top是终端,由处理器(MIPS_)和存储器(Memory)构成,最终仿真测试就是在Top层面上进行的
MIPS_是处理器,由控制器(Decoder)和数据通路(DataPath)构成;
数据通路DataPath的组成单元就很多了:
- 寄存器:程序计数寄存器(PC_)、指令寄存器(IR)、数据寄存器(MDR、Data_A、Data_B);
- 寄存器文件(RF);
- 算术逻辑部件(ALU);
- 其他:几种不同位数的2路选择器、扩展器(Extender)、32位4路选择器;

Decoder.sv和DataPath.sv的代码已分别在"三、(2)" 和 "三、(3)"给出了。
下面给出MIPS处理器的代码,实际上就是构建Decoder和DataPath的信息交换。
MIPS.sv代码:
`timescale 1ns / 1ps
// Create Date: 2023/05/06 14:39:09
// Module Name: MIPS
// Description: 多周期非流水线MIPS处理器
//声明模块的输入和输出
module MIPS(input logic clk,Reset,
input logic [31:0] MemReadData,
output logic MemWriteEn,
output logic [31:0] MemAddr,MemWriteData,PC);
//声明对应Decoder.sv和DataPath.sv的输入和输出的一些量, 诸如控制信号之类的;
//MemWriteEn是本模块的输出, 无需重复声明
logic ExtOp,PCWriteEn,IRWriteEn,RegWriteEn,IorD,MemToReg,RegDst;
logic [1:0] ALUsrcA,ALUsrcB,PCsrc,PCWrCond;
logic [3:0] ALUctr;
logic [5:0] op,funct;
//MIPS处理器由控制器(Decoder)和数据通路(DataPath)构成
//本模块的作用是构建Decoder和DataPath的数据交换
//控制器Decoder
Decoder DEC(clk,Reset,op,funct, //input
ExtOp,PCWriteEn,MemWriteEn,IRWriteEn, //output
RegWriteEn,IorD,MemToReg,RegDst,
ALUsrcA,ALUsrcB,
PCsrc,PCWrCond,
ALUctr);
//数据通路DataPath
DataPath DP(clk,Reset,MemReadData, //input
ExtOp,PCWriteEn,MemWriteEn,IRWriteEn,
RegWriteEn,IorD,MemToReg,RegDst,
ALUsrcA,ALUsrcB,
PCsrc,PCWrCond,
ALUctr,
op,funct,MemWriteData,MemAddr,PC); //output
endmodule
下面将MIPS处理器和存储器Memory封装成终端Top。
终端Top.sv的代码:
`timescale 1ns / 1ps
// Create Date: 2023/05/06 14:59:30
// Module Name: Top
// Description: CPU封装
//模块的输入和输出
module Top(input logic clk,Reset,
output logic MemWriteEn,//输出的量用于仿真测试
output logic [31:0] MemAddr,MemWriteData,PC,MemReadData);
//CPU终端由MIPS处理器(MIPS)和存储器(Memory)构成
//本模块的作用是构建MIPS处理器和Memory的数据交换
//MIPS处理器
MIPS MIPS_(clk,Reset,MemReadData, //input
MemWriteEn,MemAddr,MemWriteData,PC); //output
//存储器Memory
Memory Memory_(clk,MemWriteEn,MemAddr,MemWriteData, //input
MemReadData); //output
endmodule
最后,展示一下ALU的组成:(代码部分见 "三、(4)③" )
- ALU控制器(ALUCONTROL),用于生成4个ALU控制码(SUBctr、OFctr、SIGctr、OPctr);
- 32位并行加法器(CLA32),用于得到加减运算结果;
- 1位2路选择器(MUX2X1),用于整数 "比较小于" 操作(set less than,slt);
- 32位移位器(SHIFTER),用于得到移位结果;
- 32位6路选择器(MUX6X32),用于从六个结果中选出最终的ALU结果;

四、仿真测试
Finally,Part 4! 我们的任务是编写MIPS汇编代码来测试设计的MIPS处理器
(1)如何使用Vivado进行仿真测试





注意,引入.dat文件时,应选择"Add or create simulation sources",文件类型选择"All Files"(否则将看不到.dat文件),并勾选"Copy sources into project"(复制文件到项目目录)



(2) MIPS代码:
① ProgramFile1.asm(MIPS汇编语言,18条指令):
Assembly是汇编代码,Description、Machine和Address三列是注释(MIPS汇编用 "#" 注释)
Description描述指令实现的功能,Machine是指令的机器码,Address是指令地址
# Test the MIPS processor
# add、sub、and、or、nor、slt、addi、lw、sw、beq、j
# If successful, it should write the value 7 to address 84
# Assembly Description Machine Address
main: addi $2, $0, 5 # initialize $2 = 5 20020005 00400000
addi $3, $0, 12 # initialize $3 = 12 2003000c 00400004
addi $7, $3, -9 # initialize $7 = 3 2067fff7 00400008
or $4, $7, $2 # $4 = (3 OR 5) = 7 00e22025 0040000c
and $5, $3, $4 # $5 = (12 AND 7) = 4 00642824 00400010
add $5, $5, $4 # $5 = 4 + 7 = 11 00a42820 00400014
beq $5, $7, end # shouldn't be taken 10a7000a 00400018
slt $4, $3, $4 # $4 = 12 < 7 = 0 0064202a 0040001c
beq $4, $0, around # should be taken 10800001 00400020
addi $5, $0, 0 # shouldn't happen 20050000 00400024
around: slt $4, $7, $2 # $4 = 3 < 5 = 1 00e2202a 00400028
add $7, $4, $5 # $7 = 1 + 11 = 12 00853820 0040002c
sub $7, $7, $2 # $7 = 12 - 5 = 7 00e23822 00400030
sw $7, 68($3) # [80] = mem[20] = 7 ac670044 00400034
lw $2, 80($0) # $2 = [80] = mem[20] = 7 8c020050 00400038
j end # should be taken 08100011 0040003c
addi $2, $0, 1 # shouldn't happen 20020001 00400040
end: sw $2, 84($0) # [84] = mem[21] = 7 ac020054 00400044那么我们装进存储器Memory中的ProgramFile1.dat怎么得到呢?(参见"二、(2)①" memory.v)
只要将ProgramFile1.asm中Machine那一列单独拿出来,做成ProgramFile1.txt文件,再另存为ProgramFile1.dat文件即可;
ProgramFile1.txt:(程序的机器码)
20020005
2003000c
2067fff7
00e22025
00642824
00a42820
10a7000a
0064202a
10800001
20050000
00e2202a
00853820
00e23822
ac670044
8c020050
08100011
20020001
ac020054② ProgramFile2.asm(MIPS汇编语言,31条指令):
ProgramFile1.asm并没有测试全部的指令,如bne、ori、nop、sltu等指令,故需对其修改,添加缺少的指令。增加了sltu、sll、srl、sra、nop、ori、bne指令:
# Test the MIPS processor
# add、sub、and、or、nor、slt、sltu、sll、srl、sra、nop、
# addi、ori、beq、bne、sw、lw、j
# If successful, it should write the value 7 to address 84
# Assembly Description Machine Address
main: addi $2, $0, 5 # initialize $2 = 5 20020005 00400000
addi $3, $0, 12 # initialize $3 = 12 2003000c 00400004
addi $7, $3, -9 # initialize $7 = 3 2067fff7 00400008
or $4, $7, $2 # $4 = (3 OR 5) = 7 00e22025 0040000c
ori $4, $7, 5 # $4 = (3 OR 5) = 7 34e40005 00400010
and $5, $3, $4 # $5 = (12 AND 7) = 4 00642824 00400014
nor $6, $2, $3 # $6 = (5 NOR 12) = fffffff2 00433027 00400018
add $5, $5, $4 # $5 = 4 + 7 = 11 00a42820 0040001c
sub $6, $5, $3 # $6 = 11 - 12 = -1 00a33022 00400020
slt $4, $3, $4 # $4 = 12 < 7 = 0 0064202a 00400024
beq $4, $6, end # shouldn't be taken 10860014 00400028
bne $5, $7, around # should be taken 14a70003 0040002c
addi $2, $0, 0 # shouldn't happen 20020000 00400030
addi $2, $0, 1 # 20020001 00400034
addi $2, $0, 2 # 20020002 00400038
around: sltu $4, $6, $7 # $4 = ffffffff < 3 = 0 00c7202b 0040003c
slt $4, $6, $7 # $4 = -1 < 3 = 1 00c7202a 00400040
add $7, $4, $5 # $7 = 1 + 11 = 12 00853820 00400044
sub $7, $7, $2 # $7 = 12 - 5 = 7 00e23822 00400048
sll $9, $6, 3 # $9 = ffffffff << 3 = fffffff8 000648c0 0040004c
srl $10,$6, 6 # $10= ffffffff >> 6 = 03ffffff 00065182 00400050
sra $11,$6, 9 # $11= ffffffff >> 9 = ffffffff 00065a43 00400054
sw $7, 68($3) # [80] = mem[20] = 7 ac670044 00400058
lw $2, 80($0) # $2 = [80] = mem[20] = 7 8c020050 0040005c
nop # 00000000 00400060
j end # should be taken 0810001e 00400064
addi $2, $0, 0 # shouldn't happen 20020000 00400068
addi $2, $0, 1 # 20020001 0040006c
addi $2, $0, 2 # 20020002 00400070
addi $2, $0, 3 # 20020003 00400074
end: sw $2, 84($0) # [84] = mem[21] = 7 ac020054 00400078与①同理可得到ProgramFile2.dat
而ProgramFile2.txt为:
20020005
2003000c
2067fff7
00e22025
34e40005
00642824
00433027
00a42820
00a33022
0064202a
10860014
14a70003
20020000
20020001
20020002
00c7202b
00c7202a
00853820
00e23822
000648c0
00065182
00065a43
ac670044
8c020050
00000000
0810001e
20020000
20020001
20020002
20020003
ac020054③ 如何方便地得到MIPS汇编指令序列的机器码:
可以使用QtSpim软件完成这一任务:

QtSpim软件在将beq指令和bne指令翻译成机器码时,16立即数字段会比通常意义下的多1,即QtSpim计算分支指令的Imm16时,是直接用分支目标地址减去当前指令地址,再除以4,也就是说多算了1个间隔的指令条数。
以测试代码1中的第2条beq指令为例:
beq $4 $0 around; #[0x00400020]
addi $5 $0 0; #[0x00400024]
around: slt $4 $3 $4; #[0x00400028]
# beq指令实际机器码:10800001, QtSpim翻译的机器码:10800002
# 标准意义下的分支指令的16位立即数字段是指分支目标地址与当前指令地址之间间隔的指令的条数
# 显然, 按照标准意义, beq和around只间隔了一条指令, 因此16位立即数字段应为0x0001
# QtSpim在标准意义下多加了1, 也就是把around处的指令也算了进去, 为0x0002对于 j 指令,由于QtSpim会有一段初始的汇编代码,用户代码的指令地址将从0x00400024开始,因此我们设计的PC和QtSpim的PC很可能不一样,所以还是建议手动生成 j 指令的机器码。
至于用什么生成汇编代码的.asm文件,可以先在记事本中编写MIPS代码(此时是.txt文件),然后另存为.asm文件即可。
(3) 测试台TestBench.sv代码:(解释见注释)
`timescale 1ns / 1ps
// Create Date: 2023/05/06 15:10:49
// Module Name: TestBench
// Description: 仿真测试台
//声明输入和输出, 然而TestBench不需要输入和输出, 时钟信号等可以由它自己产生
module TestBench();
//声明对应Top输入和输出的一些量
logic clk,Reset,MemWriteEn;
logic [31:0] MemAddr,MemWriteData,PC,MemReadData;
//CPU终端Top
Top top(clk,Reset,MemWriteEn,MemAddr,MemWriteData,PC,MemReadData);
//Initiate test!
//生成Reset信号:最开始的两个门延迟内, Reset = 1; 剩下的时间里, Reset = 0;
initial begin
Reset <= 1;
# 2;
Reset <= 0;
end
//生成时钟信号clk:设0时刻clk = 1, 从0时刻开始, 每5个门延迟, clk发生一次0\1跳变
always begin
clk <= 1;
# 5;
clk <= 0;
# 5;
end
//检验指令序列执行是否正确
//设计的两个指令序列, 可用同一个TestBench.sv进行测试, 只需要对Memory.v中的文件名做更改即可
//TestBench.sv也可自行设计, 只用检验某条指令执行中各值是否为正确的值即可
//这里我只对两条sw指令做检验
//设计的用于测试的指令序列(both of them)里有两条sw指令, 分别实现:
//[80] = mem[20] = 7 和 [84] = mem[21] = 7, 且后者是指令序列的最后一条指令
//如果是sw指令(MemWriteEn == 1), 则看MemAddr和MemWriteData
//若MemAddr === 84且MemWriteData === 7(也就是到了最后一条指令),
//则结束always语句, 并说明仿真测试成功;
//对于其他情况, 如果MemAddr !== 80(即不是另外一条sw指令),
//则也结束always语句, 并说明仿真测试失败;
//若以上两种情况都没有发生, 则继续循环;
//表达时序&组合逻辑的always语句
//总是在clk信号的下降沿判断组合逻辑
always @(negedge clk)
begin
if(MemWriteEn)
begin
if(MemAddr === 84 & MemWriteData === 7)
begin
$display("Simulation succeeded");
$stop;
end
else if(MemAddr !== 80)
begin
$display("Simulation failed");
$stop;
end
end
end
endmodule
(4) TestBench_behav.wcfg波形文件:(建议在Vivado中生成并观看)
波形文件中我只添加了MIPS.sv、DataPath.sv和Memory.v的信号,查看其他信号请自行添加
① ProgramFile1.dat:



② ProgramFile2.dat:
(由于修改后的测试程序判断成功的条件仍可以是“将值7写到地址84”,故可以直接使用上次测试的TestBench.sv,只需将Memory中 "$readmemh("ProgramFile1.dat",memory,32);" 语句中的ProgramFile1.dat改成ProgramFile2.dat,这在前文也有提到)




既然大家都知道了,这戏我就不演了——我就是大名鼎鼎的重庆军统,和小日本双料高级特工,代号(摘帽),"穿山甲"——杜孝先是我放的,这鸡汤里边的毒我也放了,不过这鸡汤我喝了,我肯定得死,你们不喝,也别想活着!!! 龟先生,天皇毙下,我滴任务完成啦!!! (催笑瓦斯) Haha↓HAHAHAHA——
凭什么《激战江南》剧照被认为违规了?! (恼)文章来源:https://www.toymoban.com/news/detail-508413.html
Thanks for reading! 文章来源地址https://www.toymoban.com/news/detail-508413.html
到了这里,关于【计组实验】基于Verilog的多周期非流水线MIPS处理器设计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!