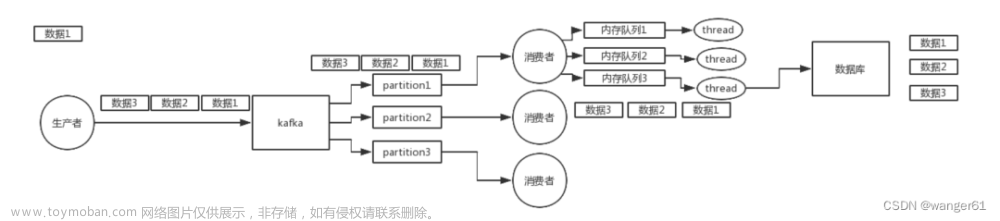
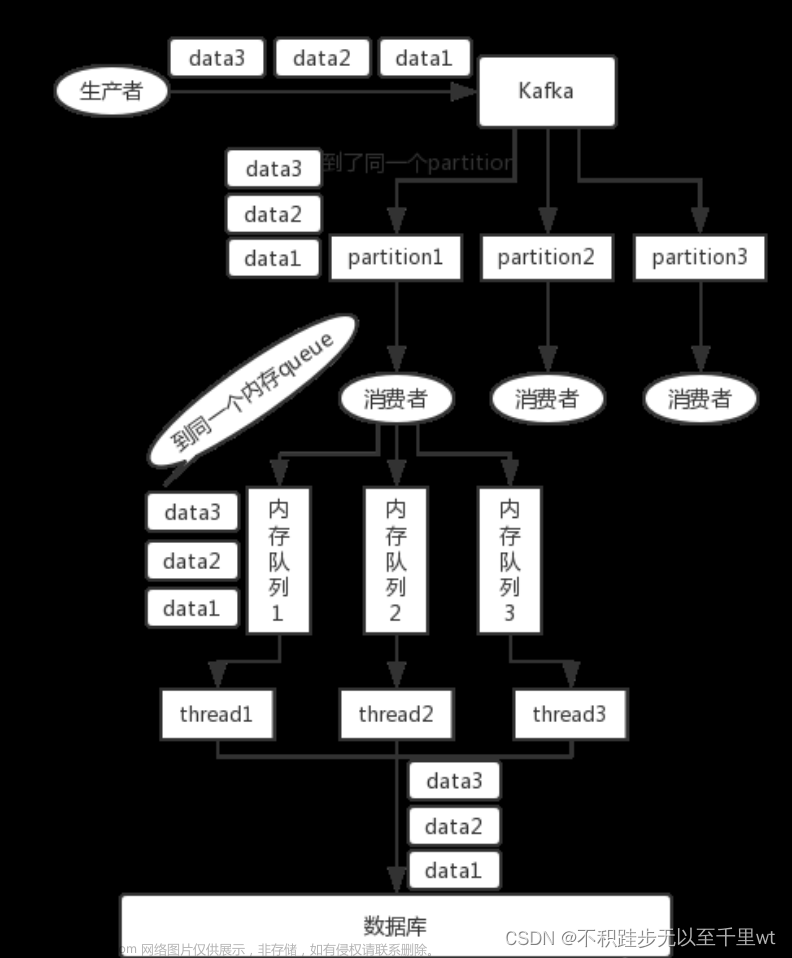
数据有序

数据乱序

max.in.flight.requests.per.connection指定了生产者在接收到服务器相应之前可以发送多个消息。文章来源:https://www.toymoban.com/news/detail-508611.html
kafka在1.x版本之前保证单分区有序,条件如下
max.in.flight.requests.per.connection=1
2) kafka在1.x及以后版本保证数据单区间分区有序,条件如下
未开启幂等性
max.in.flight.requests.per.connection需要设置为1
开启幂等性
max.in.flight.requests.per.connection需要设置小于等于5
原因说明:因为kafka1.x以后,启动幂等后,kafka会缓存producer发来最近的5个request源数据,故无论如何,都可以保证最近5个request数据是有序的文章来源地址https://www.toymoban.com/news/detail-508611.html
到了这里,关于kafka入门,数据有序、数据乱序(十)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!