目标检测模型中的Bells and wisthles
介绍常见的提升检测模型性能的技巧,它们常作为trick在比赛中应用。其实,这样的名称有失公允,部分工作反映了作者对检测模型有启发意义的观察,有些具有成为检测模型标准组件的潜力(如果在早期的工作中即被应用则可能成为通用做法)。读者将它们都看作学术界对解决这一问题的努力即可。对研究者,诚实地报告所引用的其他工作并添加有说服力的消融实验(ablation expriments)以支撑自己工作的原创性和贡献之处,则是值得倡导的行为。
1. Data augmentation 数据增强
数据增强是增加深度模型鲁棒性和泛化性能的常用手段,随机翻转、随机裁剪、添加噪声等也被引入到检测任务的训练中来,其信念是通过数据的一般性来迫使模型学习到诸如对称不变性、旋转不变性等更一般的表示。通常需要注意标注的相应变换,并且会大幅增加训练的时间。个人认为数据(监督信息)的适时传入可能是更有潜力的方向。
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15), # 数据增强
transforms.ToTensor(),
transforms.Normalize(mean, std)
])
# Augmenter()数据增强
dataset_train = CocoDataset(parser.dataset['coco'], set_name='train2017',
transform=transforms.Compose([Normalizer(), Augmenter(), Resizer()]))
dataset_val = CocoDataset(parser.dataset['coco'], set_name='val2017',
transform=transforms.Compose([Normalizer(), Resizer()]))
2. Multi-scale Training/Testing 多尺度训练/测试
输入图片的尺寸对检测模型的性能影响相当明显,事实上,多尺度是提升精度最明显的技巧之一。在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性,仅在测试阶段引入多尺度,也可享受大尺寸和多尺寸带来的增益。
Multi-scale Training/Testing最早见于[1],训练时,预先定义几个固定的尺度,每个epoch随机选择一个尺度进行训练。测试时,生成几个不同尺度的feature map,对每个Region Proposal,在不同的feature map上也有不同的尺度,我们选择最接近某一固定尺寸(即检测头部的输入尺寸)的Region Proposal作为后续的输入。在[2]中,选择单一尺度的方式被Maxout(element-wise max,逐元素取最大)取代:随机选两个相邻尺度,经过Pooling后使用Maxout进行合并,如下图所示。

近期的工作如FPN等已经尝试在不同尺度的特征图上进行检测,但多尺度训练/测试仍作为一种提升性能的有效技巧被应用在MS COCO等比赛中。
import torch
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader
# 定义多尺度训练的缩放因子列表
scale_factors = [0.5, 0.75, 1.0, 1.25, 1.5]
# 定义训练和测试函数
def train(model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item() # 将一批的损失相加
pred = output.argmax(dim=1, keepdim=True) # 找到概率最大的索引
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
# 定义训练和测试数据集
train_dataset = MyDataset(train=True)
test_dataset = MyDataset(train=False)
# 定义训练和测试数据集的DataLoader
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=4)
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义网络模型和优化器
model = MyModel().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
# 多尺度训练循环
for epoch in range(10):
for scale_factor in scale_factors:
# 对训练和测试数据集进行缩放
train_dataset.set_scale_factor(scale_factor)
test_dataset.set_scale_factor(scale_factor)
# 训练和测试
train(model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
"""
在上面的代码中,MyDataset和MyModel是用户定义的训练和测试数据集类和神经网络模型类。
train和test函数分别用于执行训练和测试。
scale_factors是一个缩放因子列表,用于对数据集进行多尺度训练和测试。
在多尺度训练循环中,对于每个缩放因子,都会对训练和测试数据集进行缩放,并执行训练和测试操作。
"""
3. Global Context 全局语境
把整张图片作为一个RoI,对其进行RoI Pooling并将得到的feature vector拼接于每个RoI的feature vector上,作为一种辅助信息传入之后的R-CNN子网络[3]。目前,也有把相邻尺度上的RoI互相作为context共同传入的做法。
4. Box Refinement/Voting 预测框微调/投票法
微调法和投票法由工作[4]提出,前者也被称为Iterative Localization。微调法最初是在SS算法得到的Region Proposal基础上用检测头部进行多次迭代得到一系列box,在ResNet的工作中,作者将输入R-CNN子网络的Region Proposal和R-CNN子网络得到的预测框共同进行NMS(见下面小节)后处理,最后,把跟NMS筛选所得预测框的IoU超过一定阈值的预测框进行按其分数加权的平均,得到最后的预测结果。投票法可以理解为以顶尖筛选出一流,再用一流的结果进行加权投票决策。
5. OHEM 在线难例挖掘
OHEM(Online Hard negative Example Mining,在线难例挖掘)见于[5]。两阶段检测模型中,提出的RoI Proposal在输入R-CNN子网络前,我们有机会对正负样本(背景类和前景类)的比例进行调整。通常,背景类的RoI Proposal个数要远远多于前景类,Fast R-CNN的处理方式是随机对两种样本进行上采样和下采样,以使每一batch的正负样本比例保持在1:3,这一做法缓解了类别比例不均衡的问题,是两阶段方法相比单阶段方法具有优势的地方,也被后来的大多数工作沿用。

但在OHEM的工作中,作者提出用R-CNN子网络对RoI Proposal预测的分数来决定每个batch选用的样本,这样,输入R-CNN子网络的RoI Proposal总为其表现不好的样本,提高了监督学习的效率。实际操作中,维护两个完全相同的R-CNN子网络,其中一个只进行前向传播来为RoI Proposal的选择提供指导,另一个则为正常的R-CNN,参与损失的计算并更新权重,并且将权重复制到前者以使两个分支权重同步。
OHEM以额外的R-CNN子网络的开销来改善RoI Proposal的质量,更有效地利用数据的监督信息,成为两阶段模型提升性能的常用部件之一。
6. Soft NMS 软化非极大抑制

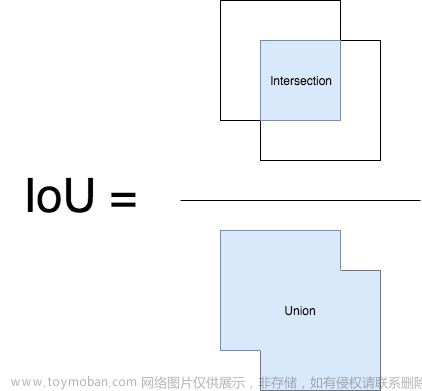
NMS(Non-Maximum Suppression,非极大抑制)是检测模型的标准后处理操作,用于去除重合度(IoU)较高的预测框,只保留预测分数最高的预测框作为检测输出。Soft NMS由[6]提出。在传统的NMS中,跟最高预测分数预测框重合度超出一定阈值的预测框会被直接舍弃,作者认为这样不利于相邻物体的检测。提出的改进方法是根据IoU将预测框的预测分数进行惩罚,最后再按分数过滤。配合Deformable Convnets,Soft NMS在MS COCO上取得了当时最佳的表现。算法改进如下:

上图中的 f f f 即为软化函数,通常取线性或高斯函数,后者效果稍好一些。当然,在享受这一增益的同时,Soft-NMS也引入了一些超参,对不同的数据集需要试探以确定最佳配置。
7. RoIAlign RoI对齐
RoIAlign是Mask R-CNN([7])的工作中提出的,针对的问题是 R o I RoI RoI 在进行 P o o l i n g Pooling Pooling 时有不同程度的取整,这影响了实例分割中 mask 损失的计算。文章采用双线性插值的方法将 R o I RoI RoI 的表示精细化,并带来了较为明显的性能提升。这一技巧也被后来的一些工作(如light-head R-CNN)沿用。
拾遗
除去上面所列的技巧外,还有一些做法也值得注意:文章来源:https://www.toymoban.com/news/detail-509226.html
- 更好的先验(YOLOv2):使用聚类方法统计数据中box标注的大小和长宽比,以更好的设置anchor box的生成配置
- 更好的pre-train模型:检测模型的基础网络通常使用ImageNet(通常是ImageNet-1k)上训练好的模型进行初始化,使用更大的数据集(ImageNet-5k)预训练基础网络对精度的提升亦有帮助
- 超参数的调整:部分工作也发现如NMS中IoU阈值的调整(从0.3到0.5)也有利于精度的提升,但这一方面尚无最佳配置参照
最后,集成(Ensemble)作为通用的手段也被应用在比赛中。文章来源地址https://www.toymoban.com/news/detail-509226.html
References
- [1]: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
[2]: Object Detection Networks on Convolutional Feature Maps
[3]: Deep Residual Learning for Image Classification
[4]: Object Detection via a Multi-region & Semantic Segmentatio-aware CNN Model
[5]: Training Region-based Object Detectors with Online Hard Example Mining
[6]: Improving Object Detection With One Line of Code
[7]: Mask R-CNN
到了这里,关于目标检测模型中的Bells and wisthles的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!