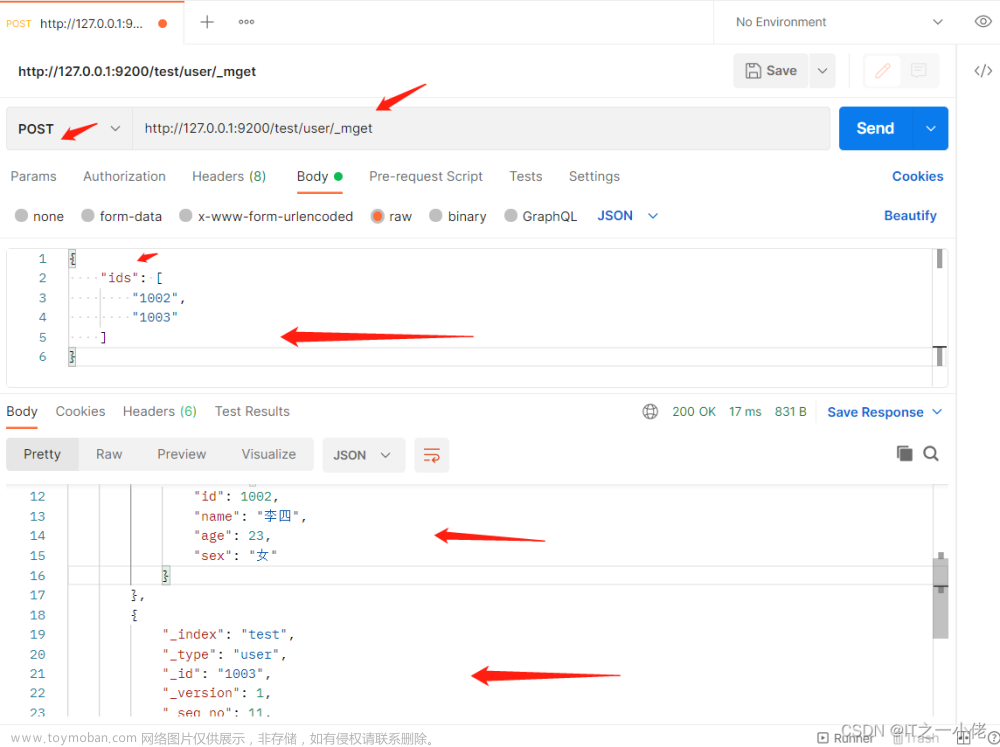
本文介绍工作中Python版常用的高效ES批量插入、更新数据方式
1. 批量插入
import pandas as pd
from elasticsearch import helpers
actions = list()
count = 0
for index, item in merged_df.iterrows():
// 过滤nan值
filted_item = dict(filter(lambda x: pd.notna(x[1]),item.items()))
action = {
"_op_type": "index", // index update
"_index": "community_summary", // 索引名
"_id": item['id'], // 文档ID
"_source": filted_item // 文档值
}
actions.append(action)
if len(actions) == 1000:
// 批量写入
helpers.bulk(es12_client.elastic_client, actions)
count += len(actions)
print(count)
actions.clear()
if len(actions) > 0:
helpers.bulk(es12_client.elastic_client, actions)
count += len(actions)
print(count)
actions.clear()
2.批量更新
批量更新只需要改动action的以下内容即可文章来源:https://www.toymoban.com/news/detail-509534.html
action = {
'_op_type': 'update', // 此处改为update
'_index': item['index'],
'_id': item_['_id'],
'doc': {'estate_type': item['映射物业类型']} // key值改为doc即可
}
欢迎关注公众号算法小生或沈健的技术博客文章来源地址https://www.toymoban.com/news/detail-509534.html
到了这里,关于18. ElasticSearch系列之批量插入与更新的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!