ChatGPT自从2022年推出以来受到很多人的喜欢,此篇博客重点介绍如何修改Prompt来自动生成较理想的单元测试。如下图所示的一段代码,该class中有一个public方法toLocale(),其余都是private方法,toLocale()方法会调用private的方法。(备注:下面的方法特地写了比较多的分支逻辑,来验证chatGPT编写的单元测试的覆盖率情况)
package com.github.secondCourse;
import java.util.Locale;
public class LocaleUtils {
private static final String EMPTY = "";
public Locale toLocale(final String str) {
if (str == null) {
return null;
}
if (str.isEmpty()) { // LANG-941 - JDK 8 introduced an empty locale where all fields are blank
return new Locale(EMPTY, EMPTY);
}
if (str.contains("#")) { // LANG-879 - Cannot handle Java 7 script & extensions
throw new IllegalArgumentException("Invalid locale format: " + str);
}
final int len = str.length();
if (len < 2) {
throw new IllegalArgumentException("Invalid locale format: " + str);
}
final char ch0 = str.charAt(0);
if (ch0 == '_') {
if (len < 3) {
throw new IllegalArgumentException("Invalid locale format: " + str);
}
final char ch1 = str.charAt(1);
final char ch2 = str.charAt(2);
if (!Character.isUpperCase(ch1) || !Character.isUpperCase(ch2)) {
throw new IllegalArgumentException("Invalid locale format: " + str);
}
if (len == 3) {
return new Locale(EMPTY, str.substring(1, 3));
}
if (len < 5) {
throw new IllegalArgumentException("Invalid locale format: " + str);
}
if (str.charAt(3) != '_') {
throw new IllegalArgumentException("Invalid locale format: " + str);
}
return new Locale(EMPTY, str.substring(1, 3), str.substring(4));
}
return parseLocale(str);
}
private Locale parseLocale(final String str) {
if (isISO639LanguageCode(str)) {
return new Locale(str);
}
final String[] segments = str.split("_", -1);
final String language = segments[0];
if (segments.length == 2) {
final String country = segments[1];
if (isISO639LanguageCode(language) && isISO3166CountryCode(country) ||
isNumericAreaCode(country)) {
return new Locale(language, country);
}
} else if (segments.length == 3) {
final String country = segments[1];
final String variant = segments[2];
if (isISO639LanguageCode(language) &&
(country.length() == 0 || isISO3166CountryCode(country) || isNumericAreaCode(country)) &&
variant.length() > 0) {
return new Locale(language, country, variant);
}
}
throw new IllegalArgumentException("Invalid locale format: " + str);
}
private boolean isISO639LanguageCode(final String str) {
return isAllLowerCase(str) && (str.length() == 2 || str.length() == 3);
}
private boolean isISO3166CountryCode(final String str) {
return isAllUpperCase(str) && str.length() == 2;
}
private boolean isNumericAreaCode(final String str) {
return isNumeric(str) && str.length() == 3;
}
private boolean isAllLowerCase(final CharSequence cs) {
if (cs == null || isEmpty(cs)) {
return false;
}
final int sz = cs.length();
for (int i = 0; i < sz; i++) {
if (!Character.isLowerCase(cs.charAt(i))) {
return false;
}
}
return true;
}
private boolean isAllUpperCase(final CharSequence cs) {
if (cs == null || isEmpty(cs)) {
return false;
}
final int sz = cs.length();
for (int i = 0; i < sz; i++) {
if (!Character.isUpperCase(cs.charAt(i))) {
return false;
}
}
return true;
}
private boolean isEmpty(final CharSequence cs) {
return cs == null || cs.length() == 0;
}
private boolean isNumeric(final CharSequence cs) {
if (isEmpty(cs)) {
return false;
}
final int sz = cs.length();
for (int i = 0; i < sz; i++) {
if (!Character.isDigit(cs.charAt(i))) {
return false;
}
}
return true;
}
}
下面是原来为这个class编写的单元测试,运行测试,覆盖率在80%左右。

public class LocalUtilsTest {
private LocaleUtils localeUtils;
@Rule
public ExpectedException exception = ExpectedException.none();
@Before
public void setUp() {
localeUtils= new LocaleUtils();
}
@Test()
public void should_return_null_when_str_is_null() {
assertThat(localeUtils.toLocale(null)).isEqualTo(null);
}
@Test()
public void should_call_isEmpty_when_str_is_empty() {
assertThat(localeUtils.toLocale("").getLanguage().isEmpty());
assertThat(localeUtils.toLocale("").getCountry().isEmpty());
}
@Test
public void should_throw_exception_when_str_is_not_valid() {
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: #");
localeUtils.toLocale("#");
}
@Test
public void should_throw_exception_when_strLength_is_less_2(){
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: a");
localeUtils.toLocale("a");
}
@Test
public void should_throw_exception_when_strLength_is_less_3() {
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: _a");
localeUtils.toLocale("_a");
}
@Test
public void should_throw_exception_when_strLength_is_3_and_is_lowercase() {
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: _Aa");
localeUtils.toLocale("_Aa");
}
@Test
public void should_return_locale_when_strLength_is_3() {
assertThat(localeUtils.toLocale("_AB").getCountry()).isEqualTo("AB");
}
@Test
public void should_throw_exception_when_strLength_is_4() {
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: _ABC");
localeUtils.toLocale("_ABC");
}
@Test
public void should_throw_exception_when_str_3_is_not_valid(){
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: _ABC_");
localeUtils.toLocale("_ABC_");
}
@Test
public void should_return_locale_when_strLength_is_5() {
assertThat(localeUtils.toLocale("_AB_DE").getCountry()).isEqualTo("AB");
}
@Test
public void should_return_locale_when_str_is_ISO639LanguageCode_and_length_is_2() {
assertThat(localeUtils.toLocale("ab").getLanguage()).isEqualTo("ab");
}
@Test
public void should_return_locale_when_str_is_ISO639LanguageCode_and_length_is_3() {
assertThat(localeUtils.toLocale("abc").getLanguage()).isEqualTo("abc");
}
@Test
public void should_return_locale_include_language_country_when_str_is_abc_AB() {
assertThat(localeUtils.toLocale("abc_AB").getLanguage()).isEqualTo("abc");
assertThat(localeUtils.toLocale("abc_AB").getCountry()).isEqualTo("AB");
}
@Test
public void should_return_locale_include_language_country_when_str_is_abc_123() {
assertThat(localeUtils.toLocale("abc_123").getLanguage()).isEqualTo("abc");
assertThat(localeUtils.toLocale("abc_123").getCountry()).isEqualTo("123");
}
@Test
public void should_return_locale_include_language_country_variant_when_str_is_abc_123_ef() {
assertThat(localeUtils.toLocale("abc_123_ab").getLanguage()).isEqualTo("abc");
assertThat(localeUtils.toLocale("abc_123_ab").getCountry()).isEqualTo("123");
assertThat(localeUtils.toLocale("abc_123_ef").getVariant()).isEqualTo("ef");
}
@Test
public void should_throw_exception_when_str_is_abc_123_ef_d() {
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: abc_123_ef_d");
localeUtils.toLocale("abc_123_ef_d");
}
@Test
public void should_throw_exception_when_str_substring_is_not_ISO3166CountryCode() {
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: abc_aB");
localeUtils.toLocale("abc_aB");
}
@Test
public void should_throw_exception_when_str_is_not_ISO639LanguageCode() {
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: abC");
localeUtils.toLocale("abC");
}
@Test
public void should_throw_exception_when_str_substring_is_not_NumericAreaCode() {
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: abc_");
localeUtils.toLocale("abc_");
}
@Test
public void should_throw_exception_when_parsed_variant_length_is_0() {
exception.expect(IllegalArgumentException.class);
exception.expectMessage("Invalid locale format: abc_AB_");
localeUtils.toLocale("abc_AB_");
}
}删除上面的单元测试,尝试用ChatGPT来自动化为上面的class编写单元测试,如下图所示:左边是输入的prompt,右边是ChatGPT生成的代码。

生成的单元测试的名称不是用下滑线分割,但是我更喜欢用下滑线来分割单元测试名称,另外,默认是用Assert来进行断言,我更希望用AssertJ来作为断言库,那么可以在上面的promp的基础上进行修改,结果如下所示:除了修改单元测试名称和断言库外,上一版本生成的单元测试中对于异常的验证使用了assertThrows方法,实际该方法不存在,所以再次修改promp,让chatGPT用ExpectedException来编写异常情况的case。

经过上面的修改后,编写全新的prompt,让chatGPT再次生成新的单元测试,修改后的Prompt如下所示:,copy单元测试到IDE工具上,虽然得到的覆盖率有点低(如下所示),但可直接运行,无任何报错:


此时,再修改prompt添加了覆盖率的要求,此时,chatGPT对私有方法编写了单元测试,但同时也给出了提示信息“不建议对私有方法编写单元测试,应该直接调用公有方法进行覆盖”,具体如下所示:

另外,因为ChatGPT默认返回的tokens数量是4096,这包括输入的prompt的tokens个数和返回的response的tokens个数,所以,对于很长的代码,一次性生成完整的单元测试有难度,针对这种情况,建议在生成的基础版本上有针对的添加剩余的单元测试,即给ChatGPT更多的上下文信息来驱动生成单元测试。以下图为例,查看未覆盖的代码,针对性的给出prompt,让单元测试进一步完善。


修改Prompt,针对性的补充未覆盖的单元测试,修改后的prompt和自动生产的单元测试结果如下所示:可以看到单元测试中生成了len==3的case,另外还生成了len大于4的case,而对于边界值校验来说,真正需要的len是等于5和小于5且不等于3的情况,例如len==4的case,所以,在自动生成的基础上稍微修改下input就可以达到这个效果。

总结而言,在prompt中基础的输入信息是"用junit,assertjs编写单元测试,且单元测试方法名称用下划线分割,方法名称以should开头,异常验证部分使用Junit中的ExpectedException",在基础prompt上,再结合实际情况输入针对性信息,即可借助chatGPT编写单元测试。文章来源:https://www.toymoban.com/news/detail-509803.html
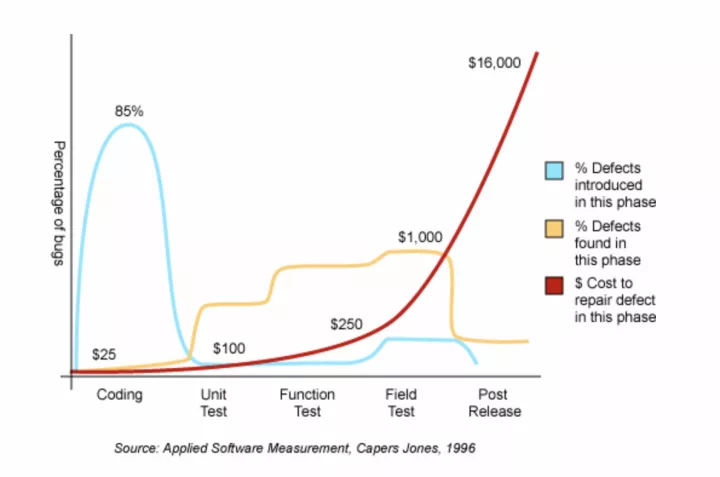
另外,需要注意一点:chatGPT有tokens的限制,所以,对于比较大的class,需要分段输入给chatGPT,否则返回的response结果有限。文章来源地址https://www.toymoban.com/news/detail-509803.html
到了这里,关于利用ChatGPT协助编写单元测试的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!