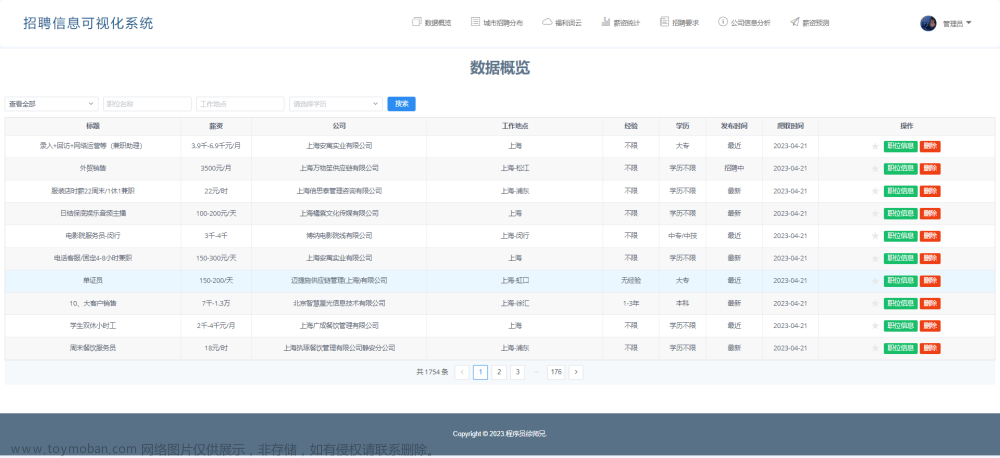
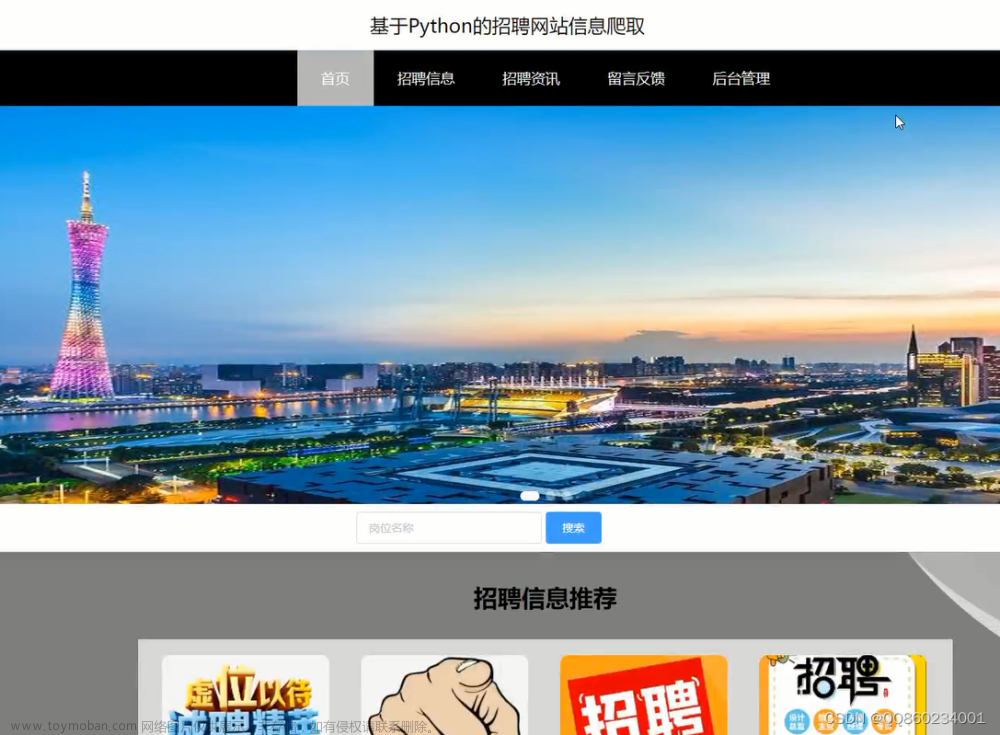
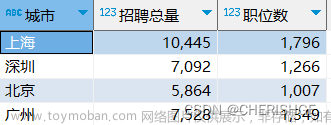
大数据项目实战
第二章 搭建大数据集群环境
学习目标
了解虚拟机的安装和克隆
熟悉虚拟机网络配置和 SSH 服务配置
掌握 Hadoop 集群的搭建
熟悉 Hive 的安装
掌握 Sqoop 的安装
搭建大数据集群环境是开发本项目的基础。本篇将通过在虚拟机中构建多个Linux操作系统的方式来搭建大数据集群环境。
一、安装准备
Hadoop本身可以运行在Linux,Windows 以及其他一些常见操作系统之上,但是 Hadoop官方真正支持的作业平台只有 Linux,这就导致其他平台在运行 Hadoop 时,需要安装其他的软件来提供一些 Liinux 操作系统的功能,以配合 Hadoop 的执行,鉴于 Hadoop、Hive、Sqoop 等大数据技术大多数都是运行在 Linux 系统上,因此本项目采用 Linux 操作系统作为数据集群环境的基础。
二、虚拟机安装与克隆
大数据集群环境的搭建需要设计多台机器,因此可以使用虚拟机软件(如 VMare Workstation )在同一台计算机上构建多个 Linux 虚拟机环境,从而进行大数据集群环境的学习和个人测试。
1.虚拟机的安装和设置
安装完VMware Workstation15后打开。按照以下图片进行操作即可。
























这里设密码,两个都是你要设的密码,慎重设置



克隆虚拟机:右击Hadoop001,选择“管理”,选择“克隆”。
注意:至少克隆两台,名为 Hadoop002、Hadoop003,克隆步骤都是一样的,只展示克隆一台的过程。


2.虚拟机网络配置
(1)主机名和 IP 映射配置
打开 Hadoop002,输入 root 用户的用户名和密码后进入虚拟机系统,在终端窗口按照以下说明进行主机名和 IP 映射的配置。
(1)配置主机名。(三台虚拟机都需要)
vi /etc/sysconfig/network

执行上述命令,将 Hadoop002 虚拟机主机名配置为 hadoop002。如图所示。
注意:点击 i 进入输入模式,点击 esc 进入命令行模式,修改完后,esc 进入命令模式,输入 :wq 存盘退出。
将 Hadoop003 虚拟机主机名配置为 hadoop003,以上重复操作即可。
修改完后,用 reboot 重启虚拟机即可。
(2)配置IP映射
配置IP映射,要明确当前虚拟机的 IP 和 主机名可以参考前面已配置的主机名, 但 IP 地址必须在 VMware 虚拟网络 IP 地址范围内。随意,这里必须先清楚可选的 IP 地址范围,才可进行 IP 映射的配置。
这里IP因个人隐私我就马赛克一部分了,马赛克部分是自己的 IP ,不影响操作。
在三台虚拟机中执行相关指令对IP映射文件hosts进行编辑。三台虚拟机重复下面操作。
vi /etc/hosts

执行上述命令后,会打开一个 hosts 映射文件,为了保证后续相互关联的虚拟机能够通过主机名进行访问,根据实际需求配置对应的 IP 和主机名映射。如下图所示。

(2)网络参数配置
(1)修改虚拟机网卡配置文件,配置网卡设备的MAC地址。(Hadoop002、Hadoop003需要配置)
vi /etc/udev/rules.d/70-persistent-net.rules

执行上述命令,会打开当前虚拟机网卡设备的参数文件,如下图所示。
(2)由于虚拟机克隆原因,在 Hadoop002 虚拟机会有 eth0 和 eth1 两块网卡(Hadoop001 虚拟机只有一块 eth0 网卡),因此删除多余的 eth1 网卡配置,只保留 eth0 一块网卡,并且修改参数 ATTR{address} == “当前虚拟机的MAC地址”(另一种更简单的方式是:删除 eth0 网卡,将 eth1 网卡的参数 NAME = “eth1” 修改为 NAME = “eth0”),同为虚拟机克隆 Hadoop003 也要进行网卡配置操作。
首先看各机器的MAC地址。如图所示(每个机器的MAC是不同的)
上图可以看出,当前Hadoop002虚拟机的MAC地址为00:0C:29:22:9E:EF,而不同的虚拟机MAC地址是唯一的。也就是说不同虚拟机MAC地址可能和其他虚拟机MAC地址是不一样的。
记得 Hadoop003 也要重复此操作哦。
(3)配置网卡文件设置静态 IP ,具体指令如下。(三台机器都需要配置)
vi /etc/sysconfig/network-scripts/ifcfg-eth0

进入后,如图所示。
修改后如图所示。
三台机器根据自己的需求按照上述修改方式修改即可。然后 reboot 重启虚拟机
(3)配置效果验证
证明修改成功的方式,如图所示。
ping 成功就可以了,当然也可以用命令 ifconfig 查看网卡配置
(4)配置 yum 源文件,方便以后所需工具下载(三台机器都要配置)
(1)重命名 Centos6 默认的 yum 源文件 CentOS-Base.repo,具体命令如下。
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
(2)创建并编辑 yum 源文件 CentOS-Base.repo,具体命令如下。
vi /etc/yum.repos.d/CentOS-Base.repo
(3)将官方 yum 源更改为 vault 的 yum 源,在 yum 源文件 CentOS-Base.repo 中添加如下内容。
[centos-office]
name=centos-office
failovermethod=priority
baseurl=https://vault.centos.org/6.10/os/x86_64/
gpgcheck=1
gpgkey=https://vault.centos.org/6.10/os/x86_64/RPM-GPG-KEY-CentOS-6
上述内容添加完成后,保存退出 yum 源文件 CentOS-Base.repo 即可。
配置完 yum 源文件,执行以下命令。
yum install lrzsz -y

此命令用于将 Windows 上的文件上传到 Linux 虚拟机上!!!非常好用!!!
如果不能正常下载 lrzsz 的话,用 WinSCP 这个软件,他可以实现 Windows 和 Linux 之间的文件传输,绝对非常有用,不用配置yum这么麻烦!!!笨猫猫在配yum的时候,主要是没有选择好镜像导致出现好多报错问题,最后还是解决了,至于如何解决,以后会出详细过程。本篇不再述说报错问题,先用WinSCP解决文件传输即可。
3.SSH 服务配置
(1)SSH 远程登录功能配置
查看当前机器是否安装SSH服务
rpm -qa | grep ssh
查看SSH服务是否启动
ps -e | grep sshd

如果没有安装,执行以下命令进行安装
yum install openssh-server
为了操作方便,可以使用远程工具 SecureCRT 8.3 或者 Xshell5 远程登录虚拟机。笨猫猫使用的是Xshell5这个远程连接工具。
(2)SSH 免密登录功能配置
在需要进行统一管理的虚拟机上(Hadoop001)输入“ssh-keygen -t rsa”指令生成密钥,并根据提示,不用输入任何内容,连续按4次Enter键确认即可,如图所示。
运行完生成密钥操作后,在当前虚拟机的root目录下生成一个包含密钥文件的 .ssh 隐藏目录。进入 .ssh 隐藏目录,通过 “ll -a”指令查看当前目录的所有文件(包括隐藏文件),如图所示。
其中,id_rsa 是 Hadoop001 的私钥,id_rsa.pub 是公钥。
在生成密钥文件的虚拟机,Hadoop001上,执行命令 “ssh-copy-id hadoop002”,复制到需要关联的服务器上(注意:包括本机),通过修改服务器主机名来指定需要复制的服务器,例如,将命令中的“hadoop002”修改为“hadoop001”,如图所示。
注意:密码是原来主机的登录密码!
在生成密钥文件的虚拟机Hadoop001上,执行相关指令将 .ssh 目录下的文件复制到需要关联的服务器上,执行命令 “scp -r /root/.ssh/* root@hadoop002:/root/.ssh/” 复制文件到hadoop002服务器,通过修改服务器主机名指定其他服务器,如图所示。
通过上述步骤操作,在相关服务器的任一节点连接的到其他节点就不用再输入密码进行访问了。如图所示。
至此完成所有相关联节点的免密钥操作。
4.Hadoop 集群搭建
(1)JDK安装
这里下载的 jdk 版本是 jdk1.8 版本,即 jdk-8u161-linux-x64.tar.gz 安装包。
mkdir -p /export/software
上述代码是存放安装包的路径,以后的任何安装包都放在这个文件夹里统一管理。
使用 WinSCP 向 Hadoop001 上传安装包。
查看是否成功。用 ls 查看即可。
创建软件存放路径,然后解压后改名为 jdk
mkdir -p /export/servers
tar -zxvf /export/software/jdk-8u161-linux-x64.tar.gz -C /export/servers/
mv jdk1.8.0_161/ jdk
执行完后查看结果
配置 JDK 环境变量
使用 “vi /etc/profile” 指令打开 profile 文件,在文件底部添加以下内容。
# 配置JDK系统环境变量
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

配置完环境变量后,使用以下命令生效 profile 文件
source /etc/profile
检验JDK安装是否成功,出现以下的信息说明 JDK 安装和配置成功。
java -version

(2)Hadoop 安装
使用 WinSCP 向 Hadoop001 上传安装包。

解压
tar -zxvf /export/software/hadoop-2.7.4.tar.gz -C /export/servers/
执行完后查看结果
配置 Hadoop 的环境变量
使用 “vi /etc/profile” 指令打开 profile 文件,在文件底部添加以下内容。
# 配置Hadoop系统环境变量
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP/sbin

配置完环境变量后,使用以下命令生效 profile 文件
安装并配置好 Hadoop 后,可以查看当前 Hadoop 版本号

(3)Hadoop 集群配置
Hadoop 默认提供两种配置文件:一种是只读配置文件,包括 core-default.xml、hdfs-default.xml、mapred-default.xml 和 yarn-default.xml,这些文件包含 Hadoop 系统各种默认配置参数;另一种是 Hadoop 集群自定义配置时编辑的配置文件(这些文件多数没有任何配置内容,存在 Hadoop 安装目录下的 etc/hadoop/ 目录中),包括 core-site.xml、hdfs-site.xml、mapred-site.xml、和 yarn-site.xml 等,可以根据需求在这些配置文件中对上一种默认配置文件中的参数进行修改,Hadoop 会优先选择自定义配置文件中的参数。
hadoop-env.sh:配置 Hadoop 运行所需要的环境变量
yarn-env.sh:配置 YARN 运行所需要的环境变量
core-site.xml:集群全局参数,用于定义系统级别的参数,如 HDFS URL、Hadoop 的临时目录等
hdfs-site.xml:HDFS参数,如名称节点和数据节点的存放位置、文件副本的个数、文件读取的权限等
mapred-site.xml:MapReduce 参数,包括 Job History Server 和应用程序参数两部分,如 reduce 任务的默认个数、任务所能够使用内存的默认上下限等
yarn-site.xml:集群资源管理系统参数,配置 ResourceManager、NodeManager 的通信端口,Web 监控端口等
1.配置集群主节点
cd /export/servers/hadoop-2.7.4/etc/hadoop/
1)修改 hadoop-env.sh 文件,将文件内默认的 JAVA_HOME 参数修改为本地安装 JDK 的路径
vi hadoop-env.sh

2)修改 yarn-env.sh 文件,设置的是 Hadoop 运行时,需要的 JDK 环境变量,目的是让 Hadoop 启动时能够执行守护进程。
vi yarn-env.sh

3)修改 core-site.xml 文件,目的是配置 HDFS 地址、端口号,以及临时文件目录。
配置了 HDFS 的主进程 NameNode 运行主机,同时配置了 Hadoop 运行时生成数据的临时目录。
vi core-site.xml

4)修改 hdfs-site.xml 文件,设置 HDFS 的 NameNode 和 DataNode 两大进程。
配置了 HDFS 数据块的副本数量(默认值就为3,此处可以省略),并根据需要设置了 Secondary NameNode 所在服务的 HTTP 地址。
vi hdfs-site.xml

5)修改 mapred-site.xml 文件。指定 Hadoop 的 MapReduce 运行框架为 YARN
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml

6)修改 yarn-site.xml 文件,需要指定 YARN 集群的管理者。
配置了 YARN 的主进程 ResourceManager 运行主机为 hadoop001,同时配置了 NodeManager 运行时的复数服务,需要配置为 mapreduce_shuffle 才能正常运行 MapReduce 默认程序。
vi yarn-site.xml

7)修改 slaves 文件,用来配合一键启动脚本启动集群从节点。删除localhost,添加三台机器的主机名
vi slaves

2.将集群主节点的配置文件分到其他子节点
scp /etc/profile hadoop002:/etc/profile
scp /etc/profile hadoop003:/etc/profile
scp -r /export/servers/ hadoop002:/export/servers/
scp -r /export/servers/ hadoop003:/export/servers/
执行完后记得去另外两台机器上执行 “source /etc/profile”
3.Hadoop集群测试
1)格式化文件系统(主节点进行格式化即可)
hdfs namenode -format
或者
hadoop namenode -format
执行成功如图所示。
4.一键启动和关闭 Hadoop 集群
1)在主节点 hadoop001 上执行一下指令启动/关闭所有 HDFS 服务进程。
start-dfs.sh
stop-dfs.sh
2)在主节点 hadoop001 上执行一下指令启动/关闭所有 YARN 服务进程。
start-yarn.sh
stop-yarn.sh

jps 查看各节点的服务进程启动情况


5.通过UI界面查看 Hadoop 运行状态
1)必须在本地(Windows)主机的hosts文件中添加集群服务的IP映射。
2)关闭防火墙(三台机子都要执行)
service iptables stop
3)禁止防火墙开机启动(三台机子都要执行)
chkconfig iptables off

4)打开浏览器,输入(集群服务IP+端口号)查看界面
HDFS: 50070
YARN:8088
例如:hadoop001:50070、hadoop001:8088

5.Hive 的安装
(1)安装 MySQL 服务
1)在线安装 MySQL 方式。
yum install mysql mysql-server mysql-devel -y

2)启动 MySQL 服务
/etc/init.d/mysqld start

3)MySQL 连接并登录 MySQL 服务
mysql

4)修改登录 MySQL 用户名及密码
USE mysql;
UPDATE user SET Password=PASSWORD('123456') WHERE user='root';

5)设置允许远程登录
GRANT ALL PRIVILEGES ON * . * TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;

6)使更新的权限表加载到内存中
FLUSH PRIVILEGES;

7)验证上一步 MySQL 的用户密码是否设置成功。如图所示。
这里能进入 MySQL 服务证明成功。
(2)安装 Hive
1)使用 WinSCP 向 Hadoop001 上传安装包。
2)解压
tar -zxvf /export/software/apache-hive-1.2.1-bin.tar.gz -C /export/servers/
执行完后查看结果
3)配置 Hive 的环境变量
使用 “vi /etc/profile” 指令打开 profile 文件,在文件底部添加以下内容。
export HIVE_HOME=/export/servers/apache-hive-1.2.1-bin
export PATH=$PATH:$HIVE_HOME/bin

配置完环境变量后,使用以下命令生效 profile 文件
4)修改 hive-env.sh 配置文件,添加 Hadoop 环境变量。
将 hive-env.sh.template 文件进行复制,然后重命名为 hive-env.sh
cd /export/servers/apache-hive-1.2.1-bin/conf
cp hive-env.sh.template hive-env.sh

修改 hive-env.sh 配置文件,在最底部添加如下红框内容,如图所示。
vi hive-env.sh

5)添加 hive-site.sh 配置文件,配置 MySQL 相关信息。
vi hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>MySQL连接协议</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>JDBC连接驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>密码</description>
</property>
</configuration>

6)使用 WinSCP 上传 MySQL 驱动包(mysql-connector-java-5.1.32.jar)到 Hive 安装目录下的 lib 文件夹下。
7)初始化 MySQL 数据库
需要在Hive 安装目录的 bin 目录中,执行初始化 MySQL 数据库命令。命令如下。
cd /export/servers/apache-hive-1.2.1-bin/bin
./schematool -dbType mysql -initSchema

8)验证 Hive 是否将默认使用 Derby 数据库改为 MySQL 数据库
进入 MySQL 服务,执行 “show databases;” 查看是否有 hive 这个数据库,有的话证明成功。
6.Sqoop的安装
1)用 WinSCP 上传 Sqoop 安装包
2)解压并改名
tar -zxvf /export/software/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /export/servers/

mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop-1.4.6

3)检查是否安装成功
在 Sqoop 安装目录的 bin 目录下执行下列命令。
cd /export/servers/sqoop-1.4.6/bin/
./sqoop help

4)配置 Sqoop 的环境变量
使用 “vi /etc/profile” 指令打开 profile 文件,在文件底部添加以下内容。
export SQOOP_HOME=/export/servers/sqoop-1.4.6
export PATH=$PATH:$SQOOP_HOME/bin:

配置完环境变量后,使用以下命令生效 profile 文件
5)修改 sqoop-env.sh 配置文件,添加 Hadoop 环境变量。
将 sqoop-env.sh.template 文件进行复制,然后重命名为 sqoop-env.sh
cd /export/servers/sqoop-1.4.6/conf/
cp sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
修改完后,修改里面红框的内容即可。
export HADOOP_COMMON_HOME=/export/servers/hadoop-2.7.4
export HADOOP_MAPRED_HOME=/export/servers/hadoop-2.7.4
export HIVE_HOME=/export/servers/apache-hive-1.2.1-bin

6)使用 WinSCP 上传 MySQL 驱动包(mysql-connector-java-5.1.32.jar)到 Sqoop 安装目录下的 lib 文件夹下。
7)Sqoop 测试效果
执行 Sqoop 相关指令验证 Sqoop 的执行效果即可。(此次在 Sqoop 的解压包下执行,同时注意数据库密码)
sqoop list-databases \
-connect jdbc:mysql://localhost:3306/ \
--username root --password 123456
出现如下结果证明成功地安装和配置 Sqoop 。 文章来源:https://www.toymoban.com/news/detail-509854.html
文章来源:https://www.toymoban.com/news/detail-509854.html
总结
本篇主要讲解了大数据集群环境的搭建。搭建的过程中可能会出现粗心的错误,所以每一步的配置都要格外细心,避免出错。通过本篇学习,读者可以搭建起基本的大数据实验环境,为开展后续项目内容奠定基础。文章来源地址https://www.toymoban.com/news/detail-509854.html
到了这里,关于大数据项目实战——基于某招聘网站进行数据采集及数据分析(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!