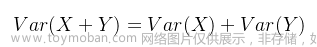refer:
-
【Pytorch】各网络层的默认初始化方法
https://blog.csdn.net/guofei_fly/article/details/105109883
20230625
其实Pytorch初始化方法就在各自的层的def reset_parameters(self) -> None:方法中。
有人可能会问为什么这个方法和Pytorch直接出来的权重初始值不一样?单步调试会发现其实这个方法运行了至少两次,而每次出来的结果都是不同的,说明初始化结果可能还和函数调用次数有关,但是不论调用多少次还是符合基本的分布情况的。请参考python/pytorch random_seed随机种子 https://blog.csdn.net/qq_43369406/article/details/131342983
"""init param"""
# !!write above on the first line!!
import random, numpy as np, torch
# set random seed
seed = 416
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
def _weights_init(m):
"""
intro:
weights init.
finish these:
- torch.nn.Linear
>>> version 1.0.0
if type(m) == nn.Linear:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][0]) # linear - param - weight
nn.init.trunc_normal_(m.weight, std=.01)
if m.bias is not None:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][1]) # linear - param - bias
nn.init.zeros_(m.bias)
elif classname.startswith('Conv'):
m.weight.data.normal_(0.0, 0.02)
>>> version 1.0.1
refer https://blog.csdn.net/guofei_fly/article/details/105109883
finish nn.Linear, nn.Conv
args:
:param torch.parameters m: nn.Module
"""
classname = m.__class__.__name__
if type(m) == nn.Linear or classname.startswith("Conv"):
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][0]) # linear - param - weight
nn.init.kaiming_uniform_(m.weight, a=math.sqrt(5), nonlinearity='leaky_relu')
if m.bias is not None:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][1]) # linear - param - bias
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(m.weight)
bound = 1 / math.sqrt(fan_in)
nn.init.uniform_(m.bias, -bound, bound)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
net = nn.Sequential(nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=1), nn.LazyLinear(8), nn.ReLU(), nn.LazyLinear(1))
X = torch.rand(size=(1, 3, 224, 224)) # [ batch_size, channel, height, width ]
Y = net(X)
net.apply(_weights_init)
# check param
print(net[0].weight, '\n', net[0].bias)
20230622
# !!write above on the first line!!
import random, numpy as np, torch
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
def _weights_init(m):
"""
intro:
weights init.
finish these:
- torch.nn.Linear
>>> version 1.0.0
if type(m) == nn.Linear:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][0]) # linear - param - weight
nn.init.trunc_normal_(m.weight, std=.01)
if m.bias is not None:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][1]) # linear - param - bias
nn.init.zeros_(m.bias)
args:
:param torch.parameters m: nn.Module
"""
classname = m.__class__.__name__
if type(m) == nn.Linear:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][0]) # linear - param - weight
nn.init.trunc_normal_(m.weight, std=.01)
if m.bias is not None:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][1]) # linear - param - bias
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
elif classname.startswith('Conv'):
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
net = nn.Sequential(nn.LazyLinear(8), nn.ReLU(), nn.LazyLinear(1))
X = torch.rand(size=(2, 4))
net.apply(_weights_init)
x.1 指定随机性
正态分布仍然是一个分布,这会使得你的实验结果无法完全复现,要让实验结果完全复现则需要指定seed,如下:
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed(args.seed)
x.2 参数初始化
参数初始化是很重要的工作,数据决定了梯度下降的山脉长什么样,而参数初始化决定了你从这个山的哪个合适的地方开始出发。Pytorch提供了多种初始化方法,可以搭配nn.Module.apply和你自己写的初始化方法函数,来将nn.Module中所有继承自nn.Module子类中的children对象的参数初始化,如下:
常见的bulit-in初始化方法,
"""
6.3.1. Built-in Initialization
using built-in func to init.
- `nn.init.normal_(module.weight, mean=0, std=0.01)`
- `nn.init.zeros_(module.bias)`
- `nn.init.constant_(module.weight, 1)`
- `nn.init.zeros_(module.bias)`
- `nn.init.xavier_uniform_(module.weight)`
- `nn.init.kaiming_uniform_(module.weight)` # default one for Linear, and the type is Leaky_ReLU
- `nn.init.uniform_(module.weight, -10, 10)`
"""
进行初始化,文章来源:https://www.toymoban.com/news/detail-510069.html
def init_normal(module):
if type(module) == nn.Linear:
nn.init.normal_(module.weight, mean=0, std=0.01)
nn.init.zeros_(module.bias)
net.apply(init_normal)
print(net[0].weight.data[0])
print(net[0].bias.data[0])
使用自己的初始化方法进行初始化,文章来源地址https://www.toymoban.com/news/detail-510069.html
def _weights_init(m):
"""
intro:
weights init.
finish these:
- torch.nn.Linear
>>> version 1.0.0
if type(m) == nn.Linear:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][0]) # linear - param - weight
nn.init.trunc_normal_(m.weight, std=.01)
if m.bias is not None:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][1]) # linear - param - bias
nn.init.zeros_(m.bias)
args:
:param torch.parameters m: nn.Module
"""
classname = m.__class__.__name__
if type(m) == nn.Linear:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][0]) # linear - param - weight
nn.init.trunc_normal_(m.weight, std=.01)
if m.bias is not None:
print("Init", *[(name, param.shape) for name, param in m.named_parameters()][1]) # linear - param - bias
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.LayerNorm):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
elif classname.startswith('Conv'):
m.weight.data.normal_(0.0, 0.02)
elif classname.find('BatchNorm') != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
net = nn.Sequential(nn.LazyLinear(8), nn.ReLU(), nn.LazyLinear(1))
X = torch.rand(size=(2, 4))
net.apply(_weights_init)
到了这里,关于Pytorch权重初始化/参数初始化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!