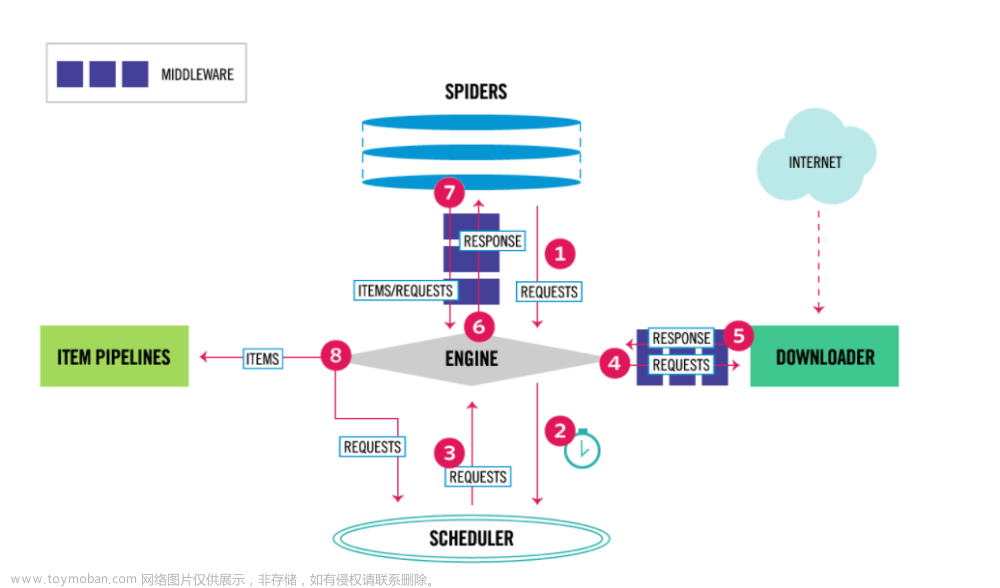
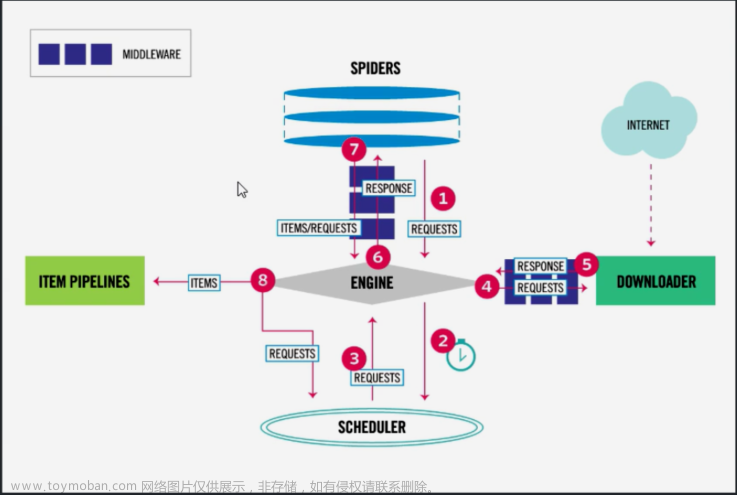
爬虫的反反爬策略
® 反反爬的总体思想
○ 将爬虫伪装成自然人的浏览行为
® 自然人浏览的特点
○ 访问频率不会太过于高
○ 使用浏览器进行访问
○ 网站设置登录要求后仍然能够正常访问
○ 可以完成验证操作
® scrapy的反反爬功能的实现
○ 爬虫配置文件setting.py
○ 爬虫框架的中间件
使用随机的ip
解决封锁IP的反爬机制
首先要在setting中设置代理IP池(要确保我们所使用代理IP可用有效!!!)
IPPools = [{'ipaddr': '120.55.241.70:80'},
{'ipaddr': '115.62.183.165:8118 '},
{'ipaddr': '183.154.208.229:8085 '},
{'ipaddr':'112.35.204.111:80'}
]
然后在middlewares.py文件中的process_request方法中是同random选取一个随机的IP,写入到request的meta属性
def process_request(self, request, spider):
thisip = random.choice(IPPools)
request.meta['proxy'] = "https://" + thisip['ipaddr']
print("this is ip:%s" % thisip['ipaddr'])
再次回到setting.py文件中注册并且设置优先级
DOWNLOADER_MIDDLEWARES = {
"ip_broker.middlewares.IpBrokerDownloaderMiddleware": 123,
}
最后打开spider的爬虫文件在response中获取到meta属性中的proxy的值
print(response.meta['proxy'])
最后一步是为了验证IP是不是真的转换为你写的代理IP
设置随机的user_agent
为了解决对user_agnet的封锁
创建一个类并且将user_agent的请求头都放到列表中
class UserAgentMiddleware(object):
def __init__(self):
self.user_agent_list = [
"Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/39.0.2171.95Safari/537.36OPR/26.0.1656.60"
"Opera/8.0(WindowsNT5.1;U;en)",
"Mozilla/5.0(WindowsNT5.1;U;en;rv:1.8.1)Gecko/20061208Firefox/2.0.0Opera9.50",
"Mozilla/4.0(compatible;MSIE6.0;WindowsNT5.1;en)Opera9.50",
"Mozilla/5.0(WindowsNT6.1;WOW64;rv:34.0)Gecko/20100101Firefox/34.0",
"Mozilla/5.0(X11;U;Linuxx86_64;zh-CN;rv:1.9.2.10)Gecko/20100922Ubuntu/10.10(maverick)Firefox/3.6.10",
"Mozilla/5.0(Macintosh;U;IntelMacOSX10_6_8;en-us)AppleWebKit/534.50(KHTML,likeGecko)Version/5.1Safari/534.50",
"Mozilla/5.0(Windows;U;WindowsNT6.1;en-us)AppleWebKit/534.50(KHTML,likeGecko)Version/5.1Safari/534.50",
"Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/534.57.2(KHTML,likeGecko)Version/5.1.7Safari/534.57.2",
"Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/39.0.2171.71Safari/537.36",
"Mozilla/5.0(X11;Linuxx86_64)AppleWebKit/537.11(KHTML,likeGecko)Chrome/23.0.1271.64Safari/537.11",
"Mozilla/5.0(Windows;U;WindowsNT6.1;en-US)AppleWebKit/534.16(KHTML,likeGecko)Chrome/10.0.648.133Safari/534.16",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Maxthon2.0)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;TencentTraveler4.0)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;TheWorld)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Trident/4.0;SE2.XMetaSr1.0;SE2.XMetaSr1.0;.NETCLR2.0.50727;SE2.XMetaSr1.0)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;360SE)",
"Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/30.0.1599.101Safari/537.36",
"Mozilla/5.0(WindowsNT6.1;WOW64;Trident/7.0;rv:11.0)likeGecko",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;AvantBrowser)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1)",
"Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;Trident/5.0;)",
"Mozilla/4.0(compatible;MSIE8.0;WindowsNT6.0;Trident/4.0)",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT6.0)",
"Mozilla/4.0(compatible;MSIE6.0;WindowsNT5.1)",
'Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/536.11(KHTML,likeGecko)Chrome/20.0.1132.11TaoBrowser/2.0Safari/536.11',
"Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.1(KHTML,likeGecko)Chrome/21.0.1180.71Safari/537.1LBBROWSER",
"Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;WOW64;Trident/5.0;SLCC2;.NETCLR2.0.50727;.NETCLR3.5.30729;.NETCLR3.0.30729;MediaCenterPC6.0;.NET4.0C;.NET4.0E;LBBROWSER)",
"Mozilla/4.0(compatible;MSIE6.0;WindowsNT5.1;SV1;QQDownload732;.NET4.0C;.NET4.0E;LBBROWSER)",
"Mozilla/5.0(compatible;MSIE9.0;WindowsNT6.1;WOW64;Trident/5.0;SLCC2;.NETCLR2.0.50727;.NETCLR3.5.30729;.NETCLR3.0.30729;MediaCenterPC6.0;.NET4.0C;.NET4.0E;QQBrowser/7.0.3698.400)",
"Mozilla/4.0(compatible;MSIE6.0;WindowsNT5.1;SV1;QQDownload732;.NET4.0C;.NET4.0E)",
"Mozilla/5.0(WindowsNT5.1)AppleWebKit/535.11(KHTML,likeGecko)Chrome/17.0.963.84Safari/535.11SE2.XMetaSr1.0",
"Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1;Trident/4.0;SV1;QQDownload732;.NET4.0C;.NET4.0E;SE2.XMetaSr1.0)",
"Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Maxthon/4.4.3.4000Chrome/30.0.1599.101Safari/537.36",
"Mozilla/5.0(WindowsNT6.1;WOW64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/38.0.2125.122UBrowser/4.0.3214.0Safari/537.36",
]
重写process_request方法
def process_request(self, request, spider):
user_agent = random.choice(self.user_agent_list)
request.headers['User-Agent'] = user_agent
print('user_agent:%s' % user_agent)
最后在setting.py文件中注册并且设置优先级文章来源:https://www.toymoban.com/news/detail-510680.html
"ip_broker.middlewares.UserAgentMiddleware": 123
这样可以解决对于封锁ip和封锁user_agent的反爬虫。文章来源地址https://www.toymoban.com/news/detail-510680.html
到了这里,关于scrapy的反反爬的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!