FrugalGPT: 如何使用大型语言模型,同时降低成本并提高性能
作者:Lingjiao Chen, Matei Zaharia, James Zou
引言
本文介绍了一种新颖的方法,旨在解决使用大型语言模型(LLM)时面临的成本和性能挑战。随着GPT-4和ChatGPT等LLM的日益流行,我们需要找到降低这些模型推理成本的策略。作者强调了LLM API的异构定价结构以及使用最大的LLM所带来的巨大财务、环境和能源影响。
问题陈述
使用LLM进行高吞吐量应用可能非常昂贵。例如,ChatGPT的运营成本估计每天超过70万美元,而使用GPT-4支持客户服务可能会给小型企业带来每月2.1万美元的费用。此外,使用最大的LLM还会带来可观的环境和能源影响。因此,我们需要一种方法来降低LLM的推理成本,同时保持良好的性能。
FrugalGPT的解决方案
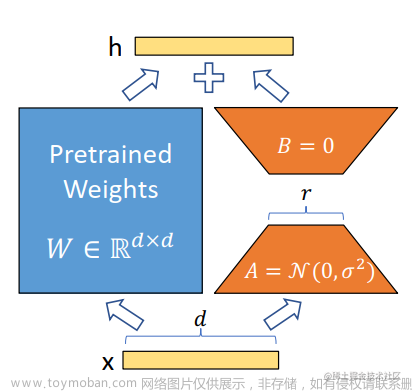
为了解决这个问题,作者提出了FrugalGPT,这是一种简单而灵活的LLM级联方法。FrugalGPT通过学习在不同查询中使用不同LLM组合的方式,以降低成本并提高准确性。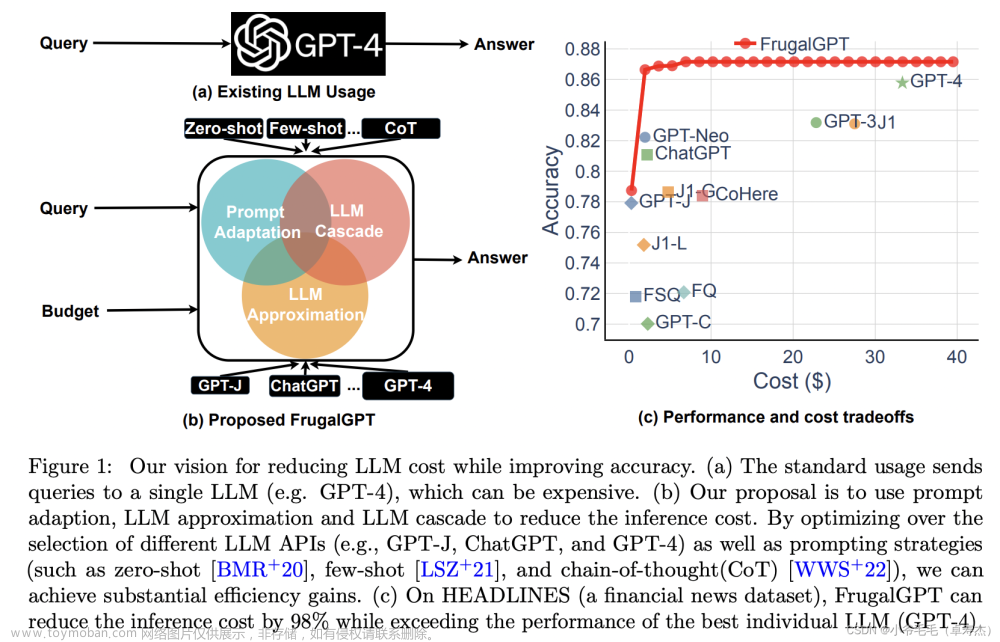
具体而言,FrugalGPT包括三种策略:提示适应、LLM近似和LLM级联。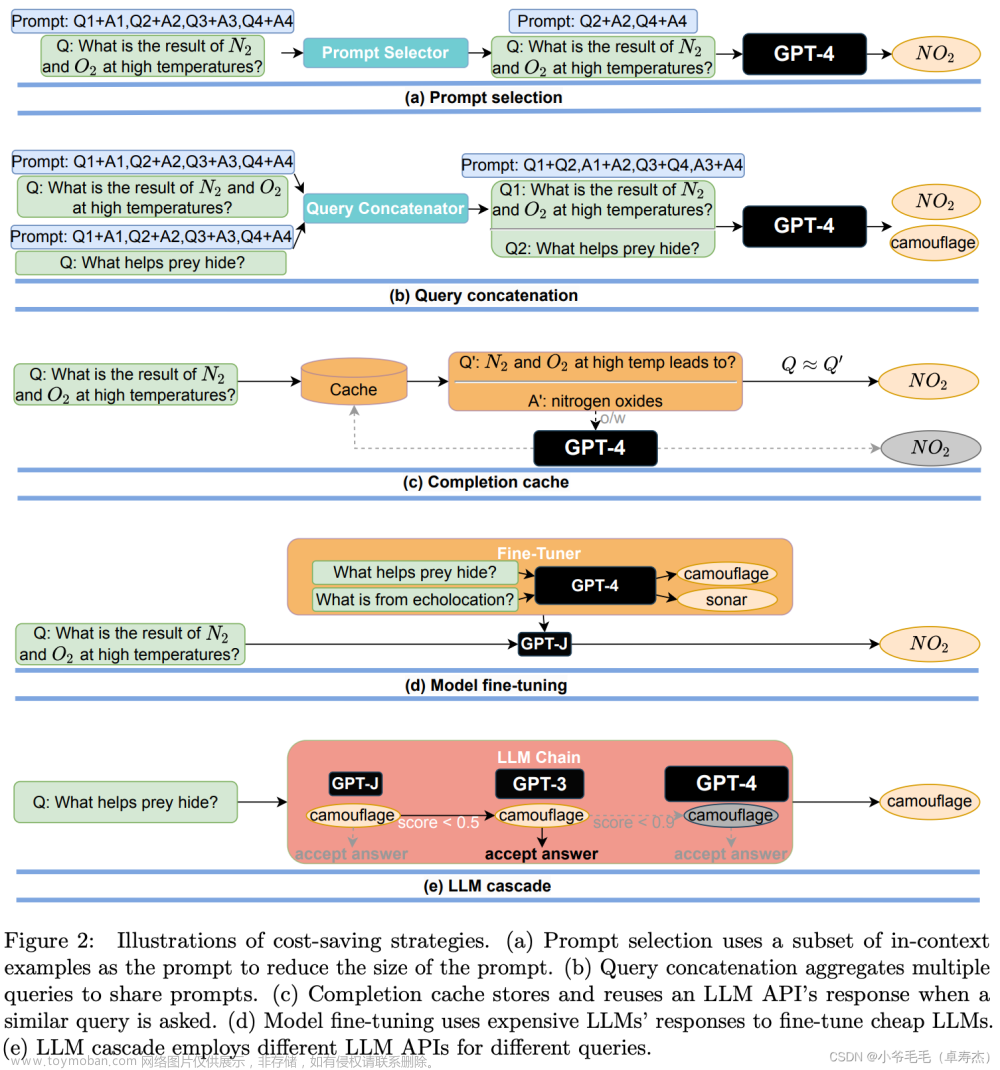
提示适应
提示适应是一种通过识别有效的提示来节省成本的方法。通过精心设计的提示,可以减少LLM的推理成本。例如,使用较短的提示可以降低成本,而不会显著影响性能。
LLM近似
LLM近似旨在创建更简单、更便宜的LLM,以在特定任务上与强大但昂贵的LLM相匹配。通过降低模型的复杂性和规模,可以降低成本,同时保持合理的性能。
LLM级联
LLM级联是一种自适应选择不同LLM API的方法,以适应不同查询。通过根据查询的特性选择合适的LLM组合,可以降低成本并提高准确性。文章来源:https://www.toymoban.com/news/detail-510887.html
实验结果
作者通过实验证明了FrugalGPT的有效性。实验结果显示,FrugalGPT可以在与最佳单个LLM相当的性能下,降低高达98%的推理成本。此外,FrugalGPT还可以在相同成本下提高4%的准确性。这些结果表明,FrugalGPT是一种可行的方法,可以在降低成本的同时提高性能。文章来源地址https://www.toymoban.com/news/detail-510887.html
到了这里,关于【斯坦福】FrugalGPT: 如何使用大型语言模型,同时降低成本并提高性能的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!