爬取数据
import time
from datetime import datetime
import csv
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup as bs
from bs4 import BeautifulSoup
import re
# 驱动路径
driver_path = r'E:\Computer\notebook\TB_Reptile\chromedriver.exe'
browser = None
# 搜索关键词
search_key_words = "固态硬盘"
info_array = []
#爬取网站的页数
number = int(input('请输入爬取页数:'))
def init_driver():
# 浏览器选项
options = webdriver.ChromeOptions()
# 不自动关闭浏览器
options.add_experimental_option('detach', True)
# 最大化
options.add_argument('--start-maximized')
global browser
browser = webdriver.Chrome(service=Service(executable_path=driver_path), options=options)
def login():
# 进入登陆页面
browser.get('https://login.taobao.com/member/login.jhtml?spm=a21bo.jianhua.0.0.5af911d9mqkcEe&f=top&redirectURL=http%3A%2F%2Fwww.taobao.com%2F')
print("请在10秒内扫码登陆")
time.sleep(15)
now = datetime.now()
print("login success:", now.strftime("%Y-%m-%d %H:%M:%S"))
def search_info():
global array
array = []
browser.find_element_by_xpath('//*[@id="q"]').send_keys(search_key_words)
browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button').click()
divs = browser.find_elements_by_xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div')
global total_info
global test
total_info = []
count = 1
while True:
start = datetime.now()
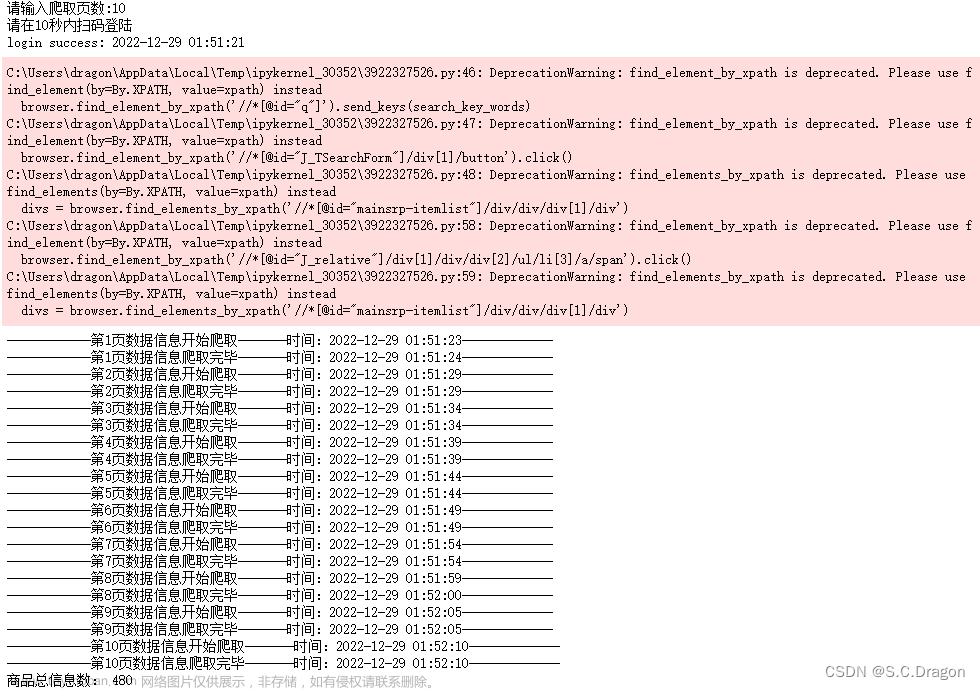
print('------------第{}页数据信息开始爬取-------时间:{}-------------'.format(count,start.strftime("%Y-%m-%d %H:%M:%S")))
browser.find_element_by_xpath('//*[@id="J_relative"]/div[1]/div/div[2]/ul/li[3]/a/span').click()
divs = browser.find_elements_by_xpath('//*[@id="mainsrp-itemlist"]/div/div/div[1]/div')
html = browser.page_source
test = re.findall(' g_page_config =(.*?);',html)[0]
title = re.findall('"raw_title":"(.*?)",',test) # 商品标题
price = re.findall('"view_price":"(.*?)",',test) # 价格
paynum = re.findall('"view_sales":"(\d+)',test) # 付款人数
location = re.findall('"item_loc":"(.*?)",',test) # 地点
name = re.findall('"nick":"(.*?)",',test) # 店铺名
comment = re.findall('"comment_count":"(.*?)","',test) # 评论数
delivery = []
description = []
service = []
d1 = re.findall('"delivery":(.*?),',test)
d2 = re.findall('"description":(.*?),',test)
s = re.findall('"service":(.*?),',test)
for j in range(len(d1)):
delivery.append(d1[j][1:]) # 物流
description.append(d2[j][1:]) # 描述
service.append(s[j][1:]) # 服务
for i in range(len(title)):
total_info.append([title[i],price[i],paynum[i],location[i],name[i],comment[i],delivery[i],description[i],service[i]])
endtime = datetime.now()
print('------------第{}页数据信息爬取完毕-------时间:{}-------------'.format(count,endtime.strftime("%Y-%m-%d %H:%M:%S")))
if count >= number:
break
count += 1
time.sleep(5)
def browser_quit():
browser.quit()
init_driver()
login()
search_info()
browser_quit()
print("商品总信息数:",len(total_info))运行结果:
数据保存
with open ('淘宝.csv',mode='a+',newline='',encoding='gbk') as f:
f = csv.writer(f)
f.writerow(['商品标题','价格','付款数','发货地','店铺','评论数','描述评分','物流评分','服务评分'])
for i in range(len(total_info)):
with open ('淘宝.csv',mode='a+',newline='',encoding='gbk') as f:
f = csv.writer(f)
f.writerow(total_info[i])
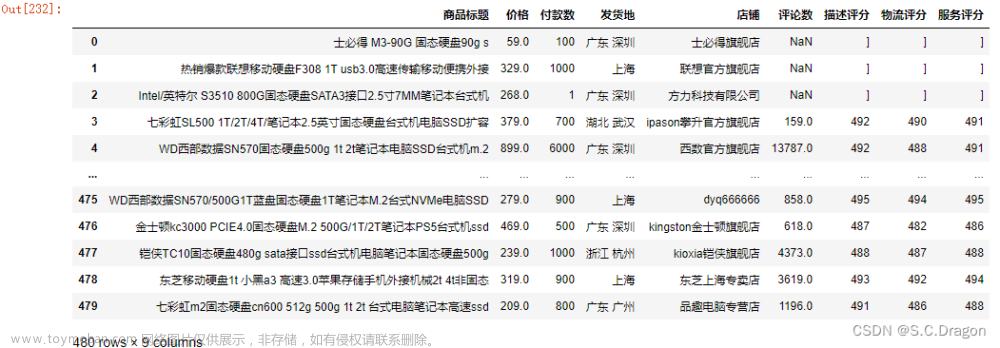
import pandas as pd
data = pd.read_csv('淘宝.csv',encoding='gbk')
data运行结果:
 文章来源:https://www.toymoban.com/news/detail-511476.html
文章来源:https://www.toymoban.com/news/detail-511476.html
文章来源地址https://www.toymoban.com/news/detail-511476.html
到了这里,关于selenium自动翻页爬取数据信息的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!