前言
在当今计算机编程领域中,Python语言以其简洁、优雅和易读的特性,成为了最受欢迎的编程语言之一。其中的字符串处理是Python编程中不可或缺的技术之一。本篇博客将介绍Python字符串的基本概念,包括字符串的定义、索引和切片操作。我们将深入探讨字符串的常用方法,如查找、替换、拆分和连接。
通过本篇博客,我们将一同探索Python字符串的奥秘,解密其在Python编程中的秘密武器地位。让我们一起开启这段精彩的Python字符串之旅吧!🚗🚗🚗
什么是 python 字符串
在 python 中,字符串是指用 ’ ’ 、" “、‘’’ ‘’'、”“” “”" 包含起来的所有字符。
message = '我爱python'
print(type(message))

message = "我爱python"
print(type(message))

message = '''我爱python'''
print(type(message))

不仅如此,当我们使用三引号作为字符串标志的时候,我们可以使用回车键将字符串分割,使之还是一个字符串,并且我们打印这个字符串的时候,字符串中也会出现换行。
message = '''我爱
python'''
print(message)
print(type(message))

但是单引号就不能达到三引号字符串这种效果。当我们在单引号字符串之间敲回车键的时候,我们会发现,字符串会被自动分割成两对引号之间使用 \ 连接的字符串,并且打印的时候不会出现换行。
message = '我爱' \
'python'
print(message)
print(type(message))

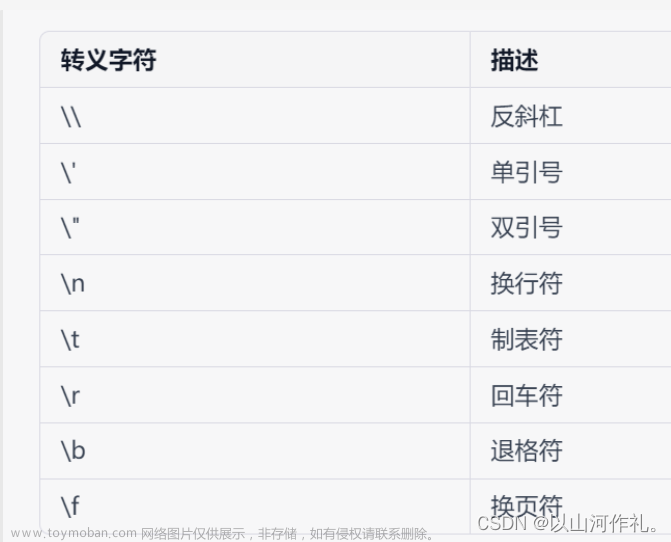
当我们的字符串中的内容也含有引号时,我们需要做出相应的操作来进行区别。

message = '我爱\'python\''
message = "我爱'python'"
通过下标(索引)来访问字符串中的字符
字符串序列[n]
这里的下标(索引)是从0开始的。
message = 'I love python'
print(message[0])
print(message[1])
print(message[3])

下标(索引)值不能大于字符串长度-1
message = 'I love python'
print(len(message)) # len() 用来获取字符串长度 13
print(message[13])

字符串的切片操作
切⽚是指对操作的对象截取其中一部分的操作。字符串、列表、元组都支持切片操作。
字符串序列[开始位置下标 : 结束位置下标 : 步长]
注意:
- 不包括结束位置下标对应的数据,正负整数都可以。
- 步长是选取间隔,正负整数均可,默认步长为1。
message = 'abcdef'
print(message[0:4:1]) # abcd

message = 'abcdef'
print(message[0:4:2])

1)当省略开始位置的下标时,默认从0下标处开始
message = 'abcdef'
print(message[:4:1])

2)当省略结束位置的下标时,默认到最后一个字符结束
message = 'abcdef'
print(message[0::1])

3)当开始位置下标和结束位置下标都省略时,表示从0下标开始到字符串的结尾
message = 'abcdef'
print(message[::1])

4)当省略步长的时候,默认步长为1
message = 'abcdef'
print(message[0:4:])

5)当步长为负数时,表明是从字符串的尾部开始到字符串的开头的方向
message = 'abcdef'
print(message[4:0:-1])

那么有人会问了,我可以将开始位置和结束位置调换一下吗?答案是不可以的,为什么呢?因为 步长的方向需要跟开始位置到结束位置的方向相同。
message = 'abcdef'
print(message[0:4:-1])

在这里开始位置到结束位置的方向是从字符串开头到结尾的,而步长为负数,则表明步长方向是从字符串尾部到字符串开头的,两者方向不相同。
6)当开始位置或者结束位置为负整数时,表示从字符串尾部开始
-1索引表示字符串的最后一个字符,-2表示倒数第二个字符
message = 'abcdef'
print(message[-1])
print(message[-2])

message = 'abcdef'
print(message[-4:-1:1])

那么这种时候,步长可以为负数吗?我们来看看。
message = 'abcdef'
print(message[-4:-1:-1])

7)当都省略的时候,则会把字符串从前往后打印一遍
message = 'abcdef'
print(message[::])

字符串常用的方法
find() 查找子串
字符串序列.find(子串,开始位置下标,结束位置下标)
从字符串开始位置开始,到结束位置结束,查找是否有指定的子串,如果有就返回第一个子串第一个字符出现的位置的下标,没有则返回-1。不包括结束位置的下标。
message = 'I love python'
print(len(message))
print(message.find('python',2,12))

message = 'I love python'
print(len(message))
print(message.find('python',2,13))

如果省略开始位置下标,则表明从0下标处开始;如果省略结束位置下标,则表明到字符串末尾结束(包括最后一个字符);都省略,则表明在整个字符串中查找。
index() 查找子串
字符串序列.index(子串,开始位置下标,结束位置下标)
index() 方法跟 find() 方法的使用基本相同,只是当字符串中没有找到子串的时候会报错。
message = 'I love python'
print(message.index('Java'))

rfind() / rindex()
这里表明从字符串的右边向左边查找,其他的方法是一样的。
count() 返回某个子串在字符串中出现的次数
字符串序列.count(子串,开始位置下标,结束位置下标)
count() 方法表明从开始位置开始到结束位置结束,看子串在字符串中出现的次数,如果没有则返回0。
message = 'A man who is handsome said that I am a handsome man'
print(message.count('handsome'))

message = 'A man who is handsome said that I am a handsome man'
print(message.count('handsome',18))

replace() 替换
字符串序列.replace(旧子串,新子串,替换次数)
replace() 方法是指将字符串中 n 个旧子串替换成新子串
message = 'A man who is handsome said that I am a handsome man'
print(message.replace('man','woman',1))
print(message.replace('man','woman',2))

当我们修改完成之后,我们再打印原字符串可以发现,原字符串并没有被修改。
message = 'A man who is handsome said that I am a handsome man'
print(message.replace('man','woman',1))
print(message.replace('man','woman',2))
print(message)

这说明在 python 中,字符串是不可变的数据类型。
split() 按照指定字符分割字符串
字符串序列.split(分割字符,num)
split() 方法是指将字符串以 num 个分割符号,分割成 num + 1 部分,返回一个列表类型的数据。并且分割后,该分割字符会消失。
message = 'A man who is handsome said that I am a handsome man'
print(message.split('handsome',1))
print(message.split('handsome',2))
print(type(message.split('handsome',1)))

join() 用一个字符或者子串合并含有多个字符串的序列
字符或者子串.join(多字符串组成的序列)
message = ['我','爱','中国']
print('哈哈'.join(message))

message = ['我','爱','中国']
print(''.join(message))

capitalize() 将字符串的第一个字符大写,其余的字符小写
字符串序列.capitalize()
message = 'i love python'
print(message.capitalize())

title() 将字符串每个单词的首字母大写
字符串序列.title()
message = 'i love python'
print(message.title())

lower() 将字符串中的字符都转换为小写
字符串序列.lower()
message = 'I love Python'
print(message.lower())

upper() 将字符串中的字符都转换为大写
字符串序列.upper()
message = 'I love Python'
print(message.upper())

lstrip() 删除字符串左边部分多余的空白
字符串序列.lstrip()
message = ' I love python '
print(message.lstrip())

rstrip() 删除字符串右边部分多余的空白
字符串序列.rstrip()
message = ' I love python '
print(message.rstrip())

strip() 删除字符串左边部分和右边部分多余的空白
字符串序列.strip()
message = ' I love python '
print(message.strip())

ljust() 左对齐
字符串序列.ljust(长度,填充字符)
message = 'I love python'
print(message.ljust(20,'。'))

rjust() 右对齐
字符串序列.rjust(长度,填充字符)
message = 'I love python'
print(message.rjust(20,'。'))

center() 居中对齐
字符串序列.center(长度,填充字符)
message = 'I love python'
print(message.center(20,'。'))

这里居中是尽可能居中,不可能做到完全居中。
startswith() 判断字符串是否是以某子串开头
字符串序列.startswith(子串,开始位置下标,结束位置下标)
message = 'I love python'
print(message.startswith("I"))
print(message.startswith("love"))

endswith() 判断字符串是否以某一字串结束
字符串序列.endswith(子串,开始位置下标,结束位置下标)
message = 'I love python'
print(message.endswith('python'))
print(message.endswith('python',9,13))

isalpha() 判断字符串是否只包含字母
字符串序列.isalpha()
message = 'I love python'
print(message.isalpha())

注意空格不算字母
message = 'abcdef'
print(message.isalpha())

isdigit() 判断字符串是否只包含数字
字符串序列.isdigit()
message = '12345'
print(message.isdigit())

isalnum() 判断字符串是否只包含字母、数字、数字字母组合
字符串序列.isalnum()
message = 'abcdef1234'
print(message.isalnum())

message = 'abcdef'
print(message.isalnum())

isspace() 判断字符串是否只有空格
字符串序列.isspace()
message = ' '
print(message.isspace())
 文章来源:https://www.toymoban.com/news/detail-511740.html
文章来源:https://www.toymoban.com/news/detail-511740.html
总结
希望文章能够对大家有所帮助,如有错误,欢迎指正,也欢迎大家订阅我的python学习专栏🌹🌹🌹文章来源地址https://www.toymoban.com/news/detail-511740.html
到了这里,关于编织魔法:探索Python字符串的奇幻世界的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!