目录
一、栈针
二、java 对象内存分布
1、那何为java内存对象布局?
2、什么是jvm的内存模型
1、如果我们新生代,一直创建新对象,此时我们新生代不够用了怎么办?
2、那么为什么大部分对象的生命周期比较短呢?这个结论哪来的呢?
3、那么为什么是这个8:1:1呢?
4、就是万一我们s0或s1不够了怎么办?
5、细聊为什么young分为eden,s0,s1区?
三、总结
1、垃圾回收
上一节课,我们探讨了jvm每块内存区域,但是我们最后对于栈针探究还没有深入,对于有开发经验的人来说,栈针也是值得研究掌握的,那么栈针到底是什么?到底包含了什么?也就是说我们一个方法被调用执行压入这样一个栈当中,这样一个栈针的细节到底有什么?这就是我们应该去思考的。
一、栈针
首先官网他也有一个说明:第 2 章。Java 虚拟机的结构 (oracle.com)
首先官网说栈针包含以下几个内容;
- 动态链接
- 方法返回值地址
- 局部变量表
- 操作数栈
这就是我们方法对应栈针它所包含的几个点。
他用一张图的表示其实就是下面这张图:

局部变量表:就是保存我们局部变量的
操作数栈:就是对我们操作数进行出栈和入栈的一个操作的。就是我们各个方法的操作数。
动态链接:可以简单理解为:我们程序在运行的时候,你的某一些类型才会进行一个确定(就是跟我们类记载中,有些类型是在程序运行的时候才会知道,或者多态中,只有被加载是你才只要要使用哪一个类,的意思是一样的);可以理解为,jvm支持在你运行的时候再去确定你的类型等。
方法返回地址:就是说如果我在函数当中,当一个方法调用另一个方法调用完了,这个方法应该继续从哪边往下继续去执行。这是要去记录方法的返回地址,
如果还不理解,有如下图:

这个就详细的描述了一个栈针到底应该包含哪些部分。
解读源代码是:

通过上面一个图解,我们能够很好地理解栈针里面的东西。
那么此时有一个疑惑:
运行时数据区跟我们虚拟机栈之间有什么关系呢?
例如此时,我们在方法只能有一个Object 的对象变量,那么此时他怎么存储的呢?
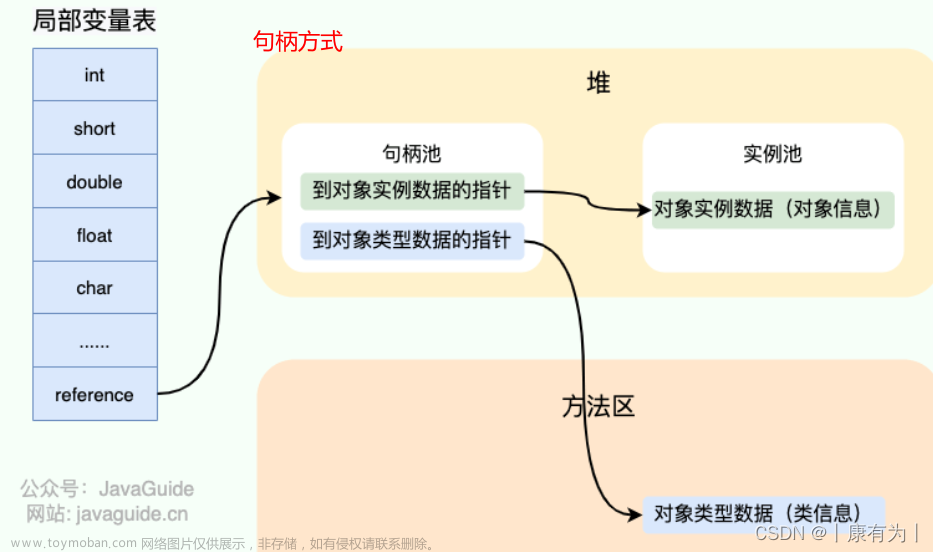
这个Object obj的这个变量,依旧在我们局部变量表中,但是他的真正的实例是在我们的堆中。所以这个时候,就会有一个经典的点,就是我们当前局部变量表中的这样一个变量:叫Obj这样一个变量,他会去进行把局部变量表中的这个obj变量,指向我们的一个堆。如果说我们把java虚拟机栈和我们的一个运行时数据区去联系起来的话,我们会去得到下面这样一张图:

我们会看到:如果我们有一个obj这样一个变量,他还会在局部变量表中,只不过他真正指向的使我们的一个堆内存中的new Object().
此时我们再往下面走:看这张图你会感觉比较有意思:
左边是你一个进程当中线程的一个执行。线程这一块执行的话,你会发现局部变量表中会有一个典型的就是,栈里面这样的一些元素指向了堆内存。我们对照这个图去进行延伸的话,
我可以怎么去做一个延伸呢?既然栈能进行去指向堆。那么我还有一个疑问?
假如说:我们在类中创建一个全局的静态Object 的变量。我们知道静态变量是存在我们方法区的。也就是说:方法区里面的元素指向的堆。
那么我们就发现是这样一种形式了,你方法区有一个静态变量,这个静态变量真正指向的内存地址使我们的一个堆内存中地址,这就是经典的方法区里面的元素指向的堆内存。
我们可以根据这张图去感受一下:

既然我们虚拟机栈能指向堆,方法区也能指向堆,那么我们可能会有一个问题:
堆能指向方法区吗?
就是说有没有这样一种可能,这样一个现象,堆能指向方法区呢?
我们慢慢去思考,我们普通的成员变量,他会随着这样一个object对象他会存储在堆内存中吗?
有一种可能性,或者我们能够想出来的可能性就是:
我 new Preson()这样一个Java对象,而且我可以确定的是Preson类型的java对象,你说如果我在new Preson()对象,他也是一个Proson类型的java对象,这时候我就会不经意的思考一个问题:
我怎么知道我们创建的Preson()就属于Prosen类型呢?
哎,这个类型信息的数据是存在那里?
回想一下,我们方法区会去存储类型的信息。
如果此时我在堆中不断去创建Preson()对象的话,我怎么知道我属于Preson类型。也就是说我当前这个Preson()是指向方法区中Preson的信息的。我认为一定是这样。
那么我们怎么去证明?
我们证明的点就是每一个Java对象里面应该需要去维护一个东西。这个东西一定知道你是从那边出生的。就好比是在你这堆对象实例中好比有一个信息能够维护住你是属于哪一个Preson这样一个类型的。
那么有嘛?如果我是一个java设计者,我就在类对象中去创建这样一个属性去标识。但是我们没必要这样去做,因为在对象或者jvm这样的一个设计者,他们也想好了,你的java对象不仅仅应该只有数据的这样一部分。你除了数据的这样一部分,你应该还包含其他信息:比如说,你当前这个对象是属于哪一个类型的。你当前这样一个对象,存活了多少次gc.等信息。
到这里就会涉及到面试中常会被问到的,java对象的内存布局:我们看到类中这些变量方法等信息是我们可以直接看到。但是我们看不到的信息,就是描述了我们不可解释的现象。
二、java 对象内存分布
这样的图如下:

1、那何为java内存对象布局?
就是说一个普通的java到底包含哪些部分?
他除了包含实例数据他左边还包含一个对象头,右边包含对齐填充。
他对象头会包含两到三个这样部分内容。因为如果你是数组这样一个类型的话,他会有一个length,会去记住你数组这样的一个长度;这是数组所特有的。然后正常的对象,他在对象头里面会包含两个部分:
一个叫:Markwork,如图
至此,我们回头想一想,我们探讨了虚拟机栈,但在会看看左边这个部分,java虚拟机栈是跟java线程有关系的,虽然也存储数据,但生命周期比较短,。
所以我们要去看看我们存储数据的,两个区域:方法区和堆,他们是和进程有关系的。而这两个区域我们很能够去联想到内存模型,这个内存模型是jvm的内存模型,而不是所谓的java的内存模型,就是我们看到的就是运行时,那么这两块数据他们落地到底是什么样的呢,如何体现的呢?所以此时我么就需要去关注jvm的内存模型了。此时我们就会想到这张图:
首先,我们先看这个,以前很老的资料说这个就是java的内存模型,这个是不对的。我们从官网也得到了证实,他更确切的是jvm运行时数据区

资料流传的太多了,他其实叫java运行时数据区。
然后我们现在要去讨论的维度,虽然官方没有得到证实,但是我跟愿意称之为JVM的内存模型,
什么是jvm的内存模型?什么意思?
2、什么是jvm的内存模型
官网没事有找到这个说明,但是有一个点可以确定,上面这个叫做运行时状态,如果他不是运行时状态,那么他应该有真实物理内存分布。所以这个真正的内存模型的落地更愿意叫他jvm的内存模型。而这个内存模型的话按道理说,应该把上面五个部分统统给他落地。但是这个部分:

jvm内存模型为什么没有,为什么大家没有去做讨论?我认为他是根据线程的生命周期是相关的,线程一定是在创建运行时才会去更多的去讨论他的。但是你的程序即使不运行起来,这两块区域他也是存在的。因为我们现在是讨轮真正全部物理的落地状态,所以我们这个可以不去讨论,因为即使你这两个不是运行时状态,这两个随着虚拟机的创建就已经存在了,这时候就会去形成一个jvm待测内存模型。这个jvm的内存模型就是我们常说的:
左边是一个mateSpace, 右边是一个堆。这个只是个人理解,可以去参考下。然后还有一个java内存模型:叫做JMM,我认为这个东西更准确的应该是形容我们一个工作总内存,下面会有一个个工作内存这样的一个情况。这个是个人一个理解,但是你知道是一个怎么样的情况就可以了。
此时(java 对象内存分布)我们真正的而要把这两块落地的是:Mate space和heap
那么我们要把它落地?但是此时怎么样去把他落地呢?
此时我们就需要去设计一个区域,把堆内存和方法区去进行一个落地。那么怎么样来落地?我们来画图:
那么假如我们式设计者,我们应该怎么去设计呢?
其实我这两个部分,不就是去存储数据的吗?要内去存储我们这类的数据,比如常量,变量啊等等。要么存储对象的数据。
假如我们有一个对象,那么我们肯定存在堆里面,那么首先我们肯定需要一个堆的区域。还有一个方法区:

但是当我们对象来的时候吗,他会存储在堆。但是他不能直接去存,因为如果都铺满我们的堆,当有些对象老了,该回收了,垃圾回收就要便利整个堆所有对象。所以我不能这么去存。所以我根据年龄去分别存储对象,所以就有了划分老年代和新生代。你的年纪大就去老年代,不大就是新生代。这样的一个而好处就是:比如你回收15次还回收不到。你就会去old区。当我们新创建一个就拿到young区,我们新创建就会拿到young区,那么我们老年代什么时候有数据呢?
老年代要有对象:
第一种情况就是:对象的大小特别大,意思就是比如我老年代有2百兆;新生代大小只有100兆空间,比如我现在老了一个对象是110兆,我新生代,现在放不下,我就直接去分配到老年代。
第二种就是:你一直在新生代去分配;分配着分配着你的对象就越来越多,你的空间不够用了,你肯定要去进行垃圾回收(垃圾回收就是回收没用的对象),此时我们就会把没用的回收掉了。剩下的就是我存活了下来。那么我的年龄就会加一。直到加到15岁,所以你15次都挺过来了,此时你就不适合待在young区,你就会跑到老年代中。(15岁是默认的)
那么问题来了:
1、如果我们新生代,一直创建新对象,此时我们新生代不够用了怎么办?

就要进行垃圾回收,比如回收几个,之后如下:

此时又来一个3个单元格大的对象(就一个来了一个大的对象)
此时他进来:发现存储不了了,放不下

此时就要去进行垃圾回收,但是垃圾回收又会影响我们线程,肯定会影响我们业务代码的执行。所以我们提倡尽量减少我们垃圾回收的评率,但是此时你看空间又不是不够吗。但是实际上空间是够的,我们不是有三个空间吗?
所以会发现一个问题,就是空间明明够,但是不连续,所以分配对像失败。所以那么我们要解决这个不连续,碎片问题。此时我们的新生代就要去从新去思考;
所以现在我们思考一下
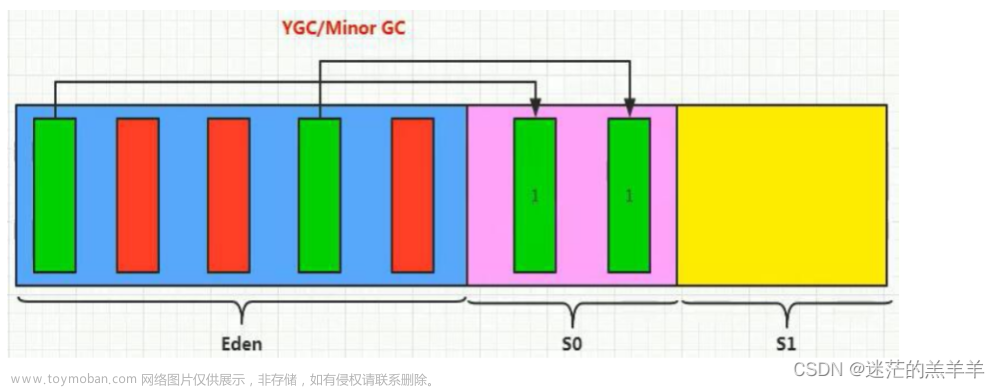
我们怎么去进行一个思考。大家注意我们此时不仅会增加gc的评频率,还会增加对象的年龄的增长,就加快了去老年代化。使去老年代,就更加的频繁了,那我们怎么办,所以我们此时就需要对新生代进行再一次划分。分配成两个区域:一个是eden区,s(Surviror)区,然后我们默认eden分配90兆大小,s区分配10兆大小,
好那么我们现在先去分配eden区,此时我们同样去分配,一直分配对象,此时当我们内存不够用了,又要去进行垃圾回收;注意:垃圾回收前提:大部分对象都是朝生夕死的。(就是大部分对象生命周期比较短)
2、那么为什么大部分对象的生命周期比较短呢?这个结论哪来的呢?
生命周期比较短就意味着,这个对象从出生到使用结束之间时间很短,很快就不用了,这种情况在我们web端很常见,比如一个订单数据,我们数据存到数据库,就用不到了,所以对象就会被回收掉。所以幸存下来的对象一般都是很少的。此时这些对象就会存活下来,他的年龄加1.但是为了避免这些存活下来的对象不连续,导致空间不连续,此时要去分配内存大小为5个格子的,但是此时又没有这么大的,那么我们就想着把幸存下来的去进行整理,怎么办?所以就把幸存的对象移到serviror s区中。
那么此时就会有一个优势:就是eden去相对连续了,不会因为少量存活的对象,而造成空间碎片。
好,那么此时又有大量数据来到eden 区,当满了时又要去进行垃圾回收,但是需要注意的是,垃圾回收是对整个young区进行回收,所以我们eden去回收后存下来一部分几个数据,同样此时s区也被回收了几个。但是此时eden去存活的对象需要挪到s区,发现,s区不是连续的,又存不了怎么办?
那么我们此时怎办呢?所以我们干脆,在进行优化,我们的目的不就是为了我们s区能够相对连续吗?
所以我们此时把s区在一份为2.。两个大小一模一样。那么此时我们怎么分配呢?
此时我们eden就分配80兆,s去就分为两区域一样大的区域,s0,s1。那么此时就能解决这个问题了吗?我们继续分析:
假如现在eden区有大量的对象,满了之后进行回收,存活的,假如我们挪到s1.当eden再一次满了,进行垃圾回收的时候,s1区同样也被垃圾回收了,然后和eden区都有一小部分存活下来,那么此时存活的不连续的,就往s0中挪。当再一次垃圾回收,之后,把存活的不连续的往s1中挪。哎这样就保证了,我们有存够连续空间去存存活的对象。
所以:此时永远都能保证s0和s1某一个为空,这样就能够解决空间碎片的问题(但是这样不会有一个弊端的吗?就是10%的空间浪费了,浪费就浪费了,我能够为了解决空间碎片问题,能够最大化利用young2区,我认为还是好的);所以说我们会说eden区和s0,s1他们之间的比率是8:1:1
3、那么为什么是这个8:1:1呢?
因为我们大部分的对象是在eden区存储,所以为什么eden区是8
因为大部分的对象是朝生夕死,只有极少数的对象会存活下来,那么我把它移到存活的区域不就够了吗?
但是还是会存在一种情况:就是万一我们s0或s1不够了怎么办?
4、就是万一我们s0或s1不够了怎么办?
那么我们就要去老年代去借点内存;这就是所谓的担保机制。
如果说我们的s区的age大于15岁,(那么我们怎么知道s区年龄打大不大于15岁呢?因为我们对象头中存放着对象的一个年龄)。就是说说如果我gc了15次了,我16岁了,我也移入老年代,他会这样去做。
哎我们发现通过一个s区的浪费,和老年代的担保机制,s不够就根据年龄移入old,就可以这个问题挺好。
还有我们的old区不一定非大于young区。
5、细聊为什么young分为eden,s0,s1区?
上面这个结论是怎么得到的呢?为什么是这样的呢?我们可以通过工具类演示,实验一下就知道,为什么eden s0 s1是这么分配的。
工具是:jvisualvm
下载地址:VisualVM: Plugins Centers
详细可看:
JVM-jvisualvm性能监控可视化工具使用与eden-s0-s1分配分析_平凡之路无尽路的博客-CSDN博客
三、总结
我们从第一节课,类加载器到这里,已经对jvm进行了一番折腾。但是jvm是不是就没有东西可去学了?是不是不用学习了。不是,我还欠缺的一个东西是:
我们的内存空间我们会不断去存储数据,但是存着存着就会发现,我们空间不够用了,不是说你不会一直不进行回收,所以我们会感觉垃圾收集机制也很重要。
虽然说我们而不需要严格的去学习。但是我们至少需要知道我们的字节码指令谁帮我们去运行的,就是我们看到的字节码指令总要有人帮我运行把。
而这个运行又分为连个维度:
- 我们java的字节码指令,到底谁来帮我们运行呢?
- 还有调用native方法的时候谁帮我们去调用呢?我想必定有个native方法库帮我们去调用。
所以jvm的图解还可以去丰富:如图:
我们原来由上面一个区域的了解,扩展到我们还需要去了解垃圾回收,执行引擎,他是为了执行我们字节码指令的。本定方法之所以能调用是因为通过本地方法接口去调用本地方法库。这才jvm的全貌。
所以接下来我们而需要研究的区域一定是垃圾收集器。
1、垃圾回收
垃圾回收是回收整个jvm的运行时数据区吗?是,但是我更愿意理解是堆中的,因为他更具有代表性,虽然其他区域也会有。但是主要在堆区域、。
我们堆内存的垃圾回收不就是上面说的吗?
那么这个区域垃圾回收我们会去怎么做?加入我们是垃圾回收设计者?
所以“”
- 第一步我的确认什么样的对象是垃圾?
- 当确认有对象是垃圾之后,该如何回收?最起码要有对应的回收算法吧
- 我知道这个算法之后,一定会有好事之者帮我对这个算法去进行落地。他会根据对应的垃圾收集器,让我去实现这个算法,让我去使用。所以就需要去学习垃圾收集器
- 有个各种垃圾收集器:他们的优势和劣势又是什么,我该如何进行选型?
- 再者,我们学会查看垃圾回收日志文件
所以接下来就是围着这个内容去进行思考
所以什么样对象是垃圾呢?
我们应该知道他有两个维度:
- 引用计数 “就是有人引用我或者指向我,我就不是垃圾,因为有人用我嘛。但是有一种情况就是,我两个对象之间彼此互相引用”这就会形成一个循环引用。这时候他们两个都没有人用,但是他们彼此相互引用,所以他们又不能称之为垃圾,所以引用计数法会存在循环引用的问题。
- 可达性分析;就是我能够选择出一个GC root 作为root节点,由他出发,然后看卡某一个对象是否可达。就是看看是否有一个对象指向他。 这样就比较又去一个点,就是我们看看他时候可达,前提我们看看什么样的对象能够成为GC ROOT。
我想,他要成为一个eGc root首先他要在java线程中能够很长时间存在,因为他作为一个上帝的视角。他需要存在这样一个意义,如果你没有这样一个意义你就不能成为gc root ,就是说你自己你自己生命周期都这么短。
所以说什么样的对象能够成为GC ROOT呢?
我们下节在探讨。文章来源:https://www.toymoban.com/news/detail-512019.html
JVM-类加载与运行区详细分析(一)_平凡之路无尽路的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-512019.html
到了这里,关于JVM-java对象内存分布(二)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!