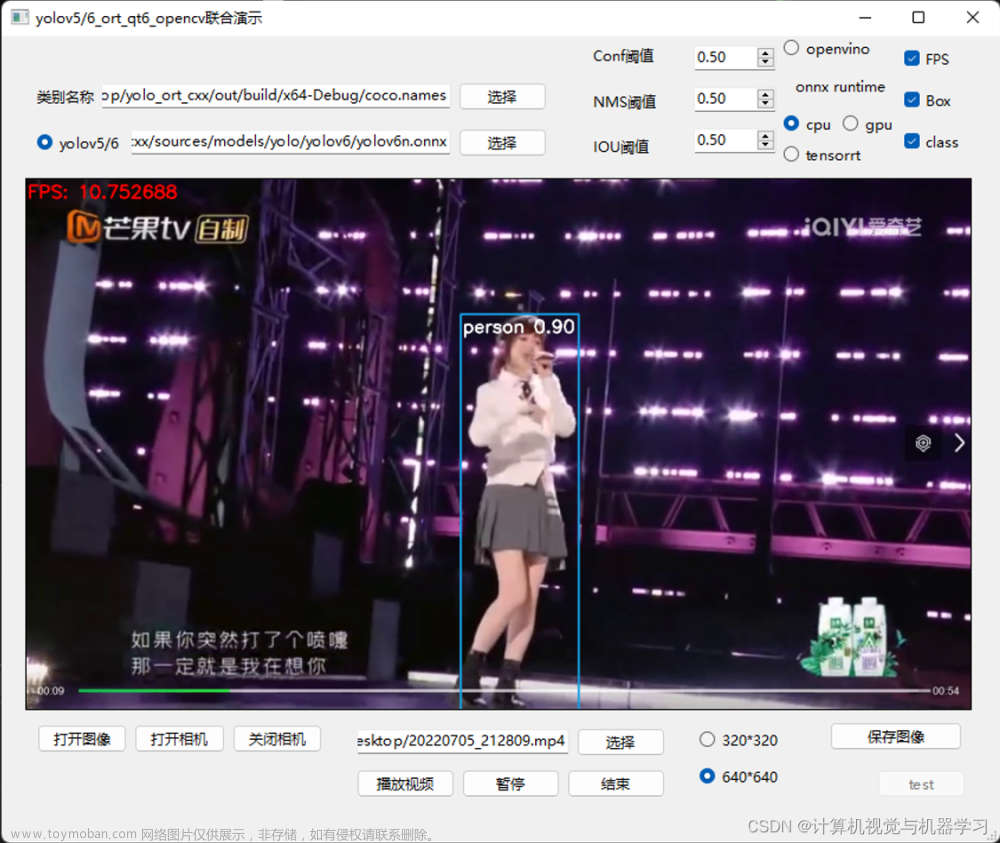
本文章是关于树莓派部署YOLOv5s模型,实际测试效果的FPS仅有0.15,不够满足实际检测需要,各位大佬可以参考参考。
1、在树莓派中安装opencv(默认安装好python3)
# 直接安装
# 安装依赖软件
sudo apt-get install -y libopencv-dev python3-opencv
sudo apt-get install libatlas-base-dev
sudo apt-get install libjasper-dev
sudo apt-get install libqtgui4
sudo apt-get install python3-pyqt5
sudo apt install libqt4-test
# 安装Python 包
pip3 install opencv-python2、导出onnx模型
从YOLOv5官网下载源代码和YOLOv5s.pt文件
YOLOv5官网
YOLOv5s.pt下载
按照作者提示安装环境,使用它自带的export.py将YOLOv5s.pt转为YOLOv5s.onnx,安装好环境后,在终端输入以下命令即可自动生成。
python export.py --weights yolov5s.pt --include onnx3.测试
可以先在电脑上测试一下,使用如下代码测试上述转换的模型能否使用,假如成功即可将下述代码和上述生成的YOLOv5s.onnx模型直接移动到树莓派中进行测试。
# 图片检测
import cv2
import numpy as np
import time
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
def post_process_opencv(outputs,model_h,model_w,img_h,img_w,thred_nms,thred_cond):
conf = outputs[:,4].tolist()
c_x = outputs[:,0]/model_w*img_w
c_y = outputs[:,1]/model_h*img_h
w = outputs[:,2]/model_w*img_w
h = outputs[:,3]/model_h*img_h
p_cls = outputs[:,5:]
if len(p_cls.shape)==1:
p_cls = np.expand_dims(p_cls,1)
cls_id = np.argmax(p_cls,axis=1)
p_x1 = np.expand_dims(c_x-w/2,-1)
p_y1 = np.expand_dims(c_y-h/2,-1)
p_x2 = np.expand_dims(c_x+w/2,-1)
p_y2 = np.expand_dims(c_y+h/2,-1)
areas = np.concatenate((p_x1,p_y1,p_x2,p_y2),axis=-1)
print(areas.shape)
areas = areas.tolist()
ids = cv2.dnn.NMSBoxes(areas,conf,thred_cond,thred_nms)
return np.array(areas)[ids],np.array(conf)[ids],cls_id[ids]
def infer_image(net,img0,model_h,model_w,thred_nms=0.4,thred_cond=0.5):
img = img0.copy()
img = cv2.resize(img,[model_h,model_w])
blob = cv2.dnn.blobFromImage(img, scalefactor=1/255.0, swapRB=True)
net.setInput(blob)
outs = net.forward()[0]
print(outs[0])
det_boxes,scores,ids = post_process_opencv(outs,model_h,model_w,img0.shape[0],img0.shape[1],thred_nms,thred_cond)
return det_boxes,scores,ids
if __name__=="__main__":
dic_labels= {0: 'person',
1: 'bicycle',
2: 'car',
4: 'airplane',
5: 'bus',
6: 'train',
7: 'truck',
8: 'boat',
9: 'traffic light',
10: 'fire hydrant',
11: 'stop sign',
12: 'parking meter',
13: 'bench',
14: 'bird',
15: 'cat',
16: 'dog',
17: 'horse',
18: 'sheep',
19: 'cow',
20: 'elephant',
21: 'bear',
22: 'zebra',
23: 'giraffe',
24: 'backpack',
25: 'umbrella',
26: 'handbag',
27: 'tie',
28: 'suitcase',
29: 'frisbee',
30: 'skis',
31: 'snowboard',
32: 'sports ball',
33: 'kite',
34: 'baseball bat',
35: 'baseball glove',
36: 'skateboard',
37: 'surfboard',
38: 'tennis racket',
39: 'bottle',
40: 'wine glass',
41: 'cup',
42: 'fork',
43: 'knife',
44: 'spoon',
45: 'bowl',
46: 'banana',
47: 'apple',
48: 'sandwich',
49: 'orange',
50: 'broccoli',
51: 'carrot',
52: 'hot dog',
53: 'pizza',
54: 'donut',
55: 'cake',
56: 'chair',
57: 'couch',
58: 'potted plant',
59: 'bed',
60: 'dining table',
61: 'toilet',
62: 'tv',
63: 'laptop',
64: 'mouse',
65: 'remote',
66: 'keyboard',
67: 'cell phone',
68: 'microwave',
69: 'oven',
70: 'toaster',
71: 'sink',
72: 'refrigerator',
73: 'book',
74: 'clock',
75: 'vase',
76: 'scissors',
77: 'teddy bear',
78: 'hair drier',
79: 'toothbrush'}
model_h = 640
model_w = 640
file_model = 'yolov5s.onnx'
net = cv2.dnn.readNet(file_model)
img0 = cv2.imread('3.jpg')
t1 = time.time()
det_boxes,scores,ids = infer_image(net,img0,model_h,model_w,thred_nms=0.4,thred_cond=0.5)
t2 = time.time()
print("cost time %.2fs"%(t2-t1))
for box,score,id in zip(det_boxes,scores,ids):
label = '%s:%.2f'%(dic_labels[id],score)
plot_one_box(box.astype(np.int16), img0, color=(255,0,0), label=label, line_thickness=None)
cv2.imshow('img',img0)
cv2.waitKey(0)
下面是视频检测代码,我采用的是树莓派自带的摄像头,如果是其他深度学习摄像头,以下代码需要更改。
# 视频检测
import cv2
import numpy as np
import time
from threading import Thread
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
def post_process_opencv(outputs,model_h,model_w,img_h,img_w,thred_nms,thred_cond):
conf = outputs[:,4].tolist()
c_x = outputs[:,0]/model_w*img_w
c_y = outputs[:,1]/model_h*img_h
w = outputs[:,2]/model_w*img_w
h = outputs[:,3]/model_h*img_h
p_cls = outputs[:,5:]
if len(p_cls.shape)==1:
p_cls = np.expand_dims(p_cls,1)
cls_id = np.argmax(p_cls,axis=1)
p_x1 = np.expand_dims(c_x-w/2,-1)
p_y1 = np.expand_dims(c_y-h/2,-1)
p_x2 = np.expand_dims(c_x+w/2,-1)
p_y2 = np.expand_dims(c_y+h/2,-1)
areas = np.concatenate((p_x1,p_y1,p_x2,p_y2),axis=-1)
# print(areas.shape)
areas = areas.tolist()
ids = cv2.dnn.NMSBoxes(areas,conf,thred_cond,thred_nms)
if len(ids)>0:
return np.array(areas)[ids],np.array(conf)[ids],cls_id[ids]
else:
return [],[],[]
def infer_image(net,img0,model_h,model_w,thred_nms=0.4,thred_cond=0.5):
img = img0.copy()
img = cv2.resize(img,[model_h,model_w])
blob = cv2.dnn.blobFromImage(img, scalefactor=1/255.0, swapRB=True)
net.setInput(blob)
outs = net.forward()[0]
det_boxes,scores,ids = post_process_opencv(outs,model_h,model_w,img0.shape[0],img0.shape[1],thred_nms,thred_cond)
return det_boxes,scores,ids
global det_boxes_show
global scores_show
global ids_show
global FPS_show
def m_detection(net,cap,model_h,model_w):
global det_boxes_show
global scores_show
global ids_show
global FPS_show
while True:
success, img0 = cap.read()
if success:
t1 = time.time()
det_boxes,scores,ids = infer_image(net,img0,model_h,model_w,thred_nms=0.4,thred_cond=0.4)
t2 = time.time()
str_fps = "FPS: %.2f"%(1./(t2-t1))
det_boxes_show = det_boxes
scores_show = scores
ids_show = ids
FPS_show = str_fps
# time.sleep(5)
if __name__=="__main__":
dic_labels = {0: 'person',
1: 'bicycle',
2: 'car',
4: 'airplane',
5: 'bus',
6: 'train',
7: 'truck',
8: 'boat',
9: 'traffic light',
10: 'fire hydrant',
11: 'stop sign',
12: 'parking meter',
13: 'bench',
14: 'bird',
15: 'cat',
16: 'dog',
17: 'horse',
18: 'sheep',
19: 'cow',
20: 'elephant',
21: 'bear',
22: 'zebra',
23: 'giraffe',
24: 'backpack',
25: 'umbrella',
26: 'handbag',
27: 'tie',
28: 'suitcase',
29: 'frisbee',
30: 'skis',
31: 'snowboard',
32: 'sports ball',
33: 'kite',
34: 'baseball bat',
35: 'baseball glove',
36: 'skateboard',
37: 'surfboard',
38: 'tennis racket',
39: 'bottle',
40: 'wine glass',
41: 'cup',
42: 'fork',
43: 'knife',
44: 'spoon',
45: 'bowl',
46: 'banana',
47: 'apple',
48: 'sandwich',
49: 'orange',
50: 'broccoli',
51: 'carrot',
52: 'hot dog',
53: 'pizza',
54: 'donut',
55: 'cake',
56: 'chair',
57: 'couch',
58: 'potted plant',
59: 'bed',
60: 'dining table',
61: 'toilet',
62: 'tv',
63: 'laptop',
64: 'mouse',
65: 'remote',
66: 'keyboard',
67: 'cell phone',
68: 'microwave',
69: 'oven',
70: 'toaster',
71: 'sink',
72: 'refrigerator',
73: 'book',
74: 'clock',
75: 'vase',
76: 'scissors',
77: 'teddy bear',
78: 'hair drier',
79: 'toothbrush'}
model_h = 640
model_w = 640
file_model = 'yolov5n.onnx'
net = cv2.dnn.readNet(file_model)
video = 0
cap = cv2.VideoCapture(video)
m_thread = Thread(target=m_detection, args=([net,cap,model_h,model_w]),daemon=True)
m_thread.start()
global det_boxes_show
global scores_show
global ids_show
global FPS_show
det_boxes_show = []
scores_show = []
ids_show =[]
FPS_show = ""
while True:
success, img0 = cap.read()
if success:
for box,score,id in zip(det_boxes_show,scores_show,ids_show):
label = '%s:%.2f'%(dic_labels[id],score)
plot_one_box(box, img0, color=(255,0,0), label=label, line_thickness=None)
str_FPS = FPS_show
cv2.putText(img0,str_FPS,(50,50),cv2.FONT_HERSHEY_COMPLEX,1,(0,255,0),3)
cv2.imshow("video",img0)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
4. 结语文章来源:https://www.toymoban.com/news/detail-512180.html
总体来说,树莓派实现YOLOv5的检测还是比较吃力的,后续可能会试试其他边缘设备,上述仅供参考,欢迎大家多多点赞交流。文章来源地址https://www.toymoban.com/news/detail-512180.html
到了这里,关于树莓派部署YOLOv5模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!