一、JVM
1. JDK、JRE、JVM三者间的关系
JDK(Java Development Kit)是Java开发工具包,是整个JAVA的核心,包括了Java运行环境JRE(Java Runtime Envirnment)、一堆Java工具(javac/java/jdb等)和Java基础的类库(即Java API 包括rt.jar)。
JRE是运行基于Java语言编写的程序所不可缺少的运行环境。JRE中包含了JVM,runtime class libraries和Java application launcher,这些是运行Java程序的必要组件。JRE是Java运行环境,并不是一个开发环境,所以没有包含任何开发工具(如编译器和调试器),只是针对于使用Java程序的用户。
JVM(java virtual machine)就是我们常说的java虚拟机,它是整个java实现跨平台的最核心的部分,所有的java程序会首先被编译为.class的类文件,这种类文件可以在虚拟机上执行。也就是说class并不直接与机器的操作系统相对应,而是经过虚拟机间接与操作系统交互,由虚拟机将程序解释给本地系统执行。只有JVM还不能成class的执行,因为在解释class的时候JVM需要调用解释所需要的类库lib,而jre包含lib类库。
2. JVM四部分组成
整个JVM框架由类加载器加载文件,执行器在内存中处理数据,交互时通过本地接口。
[1] ExecutionEngine:执行引擎,又叫解释器
负责解释命令,提交操作系统执行。
[2] NaiveInterface本地接口
作用:融合不同的语言为java所用。
[3] Runtimedataarea运行数据区
是整个JVM的重点,所有程序都被加载到这里运行。
[4] ClassLoader:类加载器
流程:Java文件>JDK编译>.class文件>classloader>加载到内存中
n ClassLoader主要对类的请求提供服务,当JVM需要某类时,它根据名称向ClassLoader要求这个类,ClassLoader将描述该类的Class文件加载到内存,并对数据进行校验,解析和初始化,最终形成能被java虚拟机直接使用的java类型。
n classloader具备层次关系:
a) 引导类加载器(bootstrap class loader)
他用类加载java 的核心库(String 、Integer、List。。。)在jre/lib/rt.jar路径下的内容,是用C代码来实现的,并不继承自java.lang.ClassLoader。
加载扩展类和应用程序类加载器。并指定他们的父类加载器。
b) 扩展类加载器(extensions class loader)
用来加载java的扩展库(jre/ext/*.jar路径下的内容)java虚拟机的实现会自动提供一个扩展目录。该类加载器在此目录里面查找并加载java类。
c) 应用程序类加载器(application class loader)
他根据java应用的类路径(classpath路径),我们编写的应用类默认情况下都是通过AppClassLoader进行加载的。当我们使用 new关键字或者Class.forName来加载类时,所要加载的类都是由调用new或者Class.forName的类的类加载器(也是 AppClassLoader)进行加载的。
ApplicationClassLoader由于是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称为SystemClassLoader.
d) 自定义类加载器
为了能够绕过Java类的既定加载过程,(例如为了达到类库的互相隔离,例如为了达到热部署重加载功能。),开发人员可以通过继承java.lang.ClassLoader类的方式实现自己的类加载器,并在其中对类的加载过程进行完全的控制和管理
n Java类加载双亲委派机制
Ø 在Java中,任意一个类都需要由加载它的类加载器和这个类本身一同确定其在java虚拟机中的唯一性,即比较两个类是否相等,只有在这两个类是由同一个类加载器加载的前提之下才有意义,否则,即使这两个类来源于同一个Class类文件,只要加载它的类加载器不相同,那么这两个类必定不相等(这里的相等包括代表类的Class对象的equals()方法、isAssignableFrom()方法、isInstance()方法和instanceof关键字的结果)。
Ø 如果一个类加载器收到了类加载的请求,它不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,这样层层递进,最终所有的加载请求都被传到最顶层的启动类加载器中,只有当父类加载器无法完成这个加载请求(它的搜索范围内没有找到所需的类)时,才会交给子类加载器去尝试加载.
Ø 这样的好处是:java类随着它的类加载器一起具备了带有优先级的层次关系.这是十分必要的,比如Object类,它是所有java类的父类,因此无论哪个类加载都要加载这个类,最终所有的加载请求都汇总到顶层的启动类加载器中,因此Object类会由启动类加载器来加载,所以加载的都是同一个类,如果不使用双亲委派模型,由各个类加载器自行去加载的话,系统中就会出现不止一个Object类,应用程序就会全乱了.
3. java类加载过程
[1] 加载
1. 通过一个类的全限定名获取该类的二进制流。
2. 将该二进制流中的静态存储结构转化为方法去运行时数据结构。
3. 在内存中生成该类的Class对象,作为该类的数据访问入口。
[2] 验证
验证的目的是为了确保Class文件的字节流中的信息不回危害到虚拟机.在该阶段主要完成以下四钟验证:
1. 文件格式验证:验证字节流是否符合Class文件的规范,如主次版本号是否在当前虚拟机范围内,常量池中的常量是否有不被支持的类型.
2. 元数据验证:对字节码描述的信息进行语义分析,如这个类是否有父类,是否集成了不被继承的类等。
3. 字节码验证:是整个验证过程中最复杂的一个阶段,通过验证数据流和控制流的分析,确定程序语义是否正确,主要针对方法体的验证。如:方法中的类型转换是否正确,跳转指令是否正确等。
4. 符号引用验证:这个动作在后面的解析过程中发生,主要是为了确保解析动作能正确执行。
[3] 准备
准备阶段是为类的静态变量分配内存并将其初始化为默认值,这些内存都将在方法区中进行分配。准备阶段不分配类中的实例变量的内存,实例变量将会在对象实例化时随着对象一起分配在Java堆中。
public static int value=123;//在准备阶段value初始值为0 。在初始化阶段才会变为123 。
[4] 解析
该阶段主要完成符号引用到直接引用的转换动作。解析动作并不一定在初始化动作完成之前,也有可能在初始化之后。
[5] 初始化
初始化时类加载的最后一步,前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码。
4. JVM内存结构
[1] 方法区(又叫静态区):
所有线程共享方法区。用于存放类的元数据(即:编译后的代码、类的信息、常量池、字段信息、方法信息、静态变量),并不是类的Class对象!Class对象是加载的最终产品。方法区有时候也称为永久代,在该区内很少发生垃圾回收,但是并不代表不发生GC,在这里进行的GC主要是对方法区里的常量池和对类型的卸载
[2] 堆:
所有线程共享堆区。用于存储所有new出来的对象,此对象最终由垃圾收集器收集,垃圾收集器针对的就是堆区
[3] 虚拟机栈(Java栈、占内存):
线程私有,生命周期和线程相同。每个方法被调用的时候都会创建一个栈帧,用于存储局部变量表、操作栈、动态链接、方法出口等信息。每一个方法从被调用直至执行完成的过程就对应着一个栈帧在虚拟机中从入栈到出栈的过程。
[4] 本地方法栈:
和java栈的作用差不多,只不过是为JVM使用到的native方法服务的,存储了每个native方法调用的状态
[5] 程序计数器:
线程私有,用于保存当前线程执行的内存地址。由于JVM程序是多线程执行的(线程轮流切换),所以为了保证线程切换回来后,还能恢复到原先状态,就需要一个独立的计数器,记录之前中断的地方。
5. Java中Native关键字
native是在java和其他语言(如c++)进行协作时使用的,也就是native后的函数的实现不是用java写的。
Java不是完美的,Java的不足除了体现在运行速度上要比传统的C++慢许多之外,Java无法直接访问到操作系统底层(如系统硬件等),java要实现对底层的控制,就需要一些其他语言的帮助,为此Java使用native方法来扩展Java程序的功能。
其实现步骤:
1、在Java中声明native()方法,然后编译;
2、用javah产生一个.h文件;
3、写一个.cpp文件实现native导出方法,其中需要包含第二步产生的.h文件(注意其中又包含了JDK带的jni.h文件);
4、将第三步的.cpp文件编译成动态链接库文件;
5、在Java中用System.loadLibrary()方法加载第四步产生的动态链接库文件,这个native()方法就可以在Java中被访问了。
6. JVM中的年轻代 老年代 持久代 gc
虚拟机中的共划分为三个代:年轻代、老年代和持久代(永久代)。其中持久代主要存放的是Java类的类信息,与垃圾收集要收集的Java对象关系不大。年轻代和老年代的划分是对垃圾收集影响比较大的。
你出生在 Eden 区,在 Eden 区有许多和你差不多的小兄弟、小姐妹,可以把 Eden 区当成幼儿园,在这个幼儿园里大家玩了很长时间。Eden 区不能无休止地放你们在里面,当幼儿园满了,你就要被送到学校去上学,这里假设从小学到高中都称为 Survivor 区。开始的时候你在 Survivor 区里面划分出来的的“From”区,读到高年级了,就进了 Survivor 区的“To”区,中间由于学习成绩不稳定,还经常来回折腾。直到你 18 岁的时候,高中毕业了,该去社会上闯闯了。于是你就去了年老代,年老代里面人也很多。在年老代里,你生活了 20 年 (每次 GC 加一岁),最后寿终正寝,被 GC 回收。有一点没有提,你在年老代遇到了一个同学,他的名字叫爱德华 (慕光之城里的帅哥吸血鬼),他以及他的家族永远不会死,那么他们就生活在永生代。
l 年轻代:所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代分三个区。一个Eden区,两个Survivor区(一般而言)。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor区也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。同时,根据程序需要,Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
l 年老代:在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
l 持久代:用于存放静态文件,如Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=<N>进行设置。
² 新生代进行一次垃圾清理,被称为youngGC或者minorGC,频率高,执行快!
² 老年代进行一次垃圾清理,被称为FULLGC或者majorGC,比年轻代的慢10倍
² JVM优化的一个原则就是:降低youngGC的频率、减少FULLGC的次数。
n JVM内存参数
-vmargs -Xms128M -Xmx512M -XX:PermSize=64M -XX:MaxPermSize=128M
-vmargs 说明后面是VM的参数,所以后面的其实都是JVM的参数了
-Xms128m JVM初始分配的堆内存
-Xmx512m JVM最大允许分配的堆内存,按需分配
-XX:PermSize=64M JVM初始分配的非堆内存
-XX:MaxPermSize=128M JVM最大允许分配的非堆内存,按需分配
u JVM内存配置参数
-Xmx10240m-Xms10240m-Xmn5120m-XXSurvivorRatio=3
-Xmx10240m:代表最大堆
-Xms10240m:代表初始/最小堆
-Xmn5120m:代表新生代
-XXSurvivorRatio=3:代表Eden:Survivor=3根据Generation-Collection算法(目前大部分JVM采用的算法),一般根据对象的生存周期将堆内存分为若干不同的区域,一般情况将新生代分为Eden,两块Survivor;计算Survivor大小,Eden:Survivor=3,总大小为5120,3x+x+x=5120x=1024,则Surviver总大小为2048m。
Ø 堆(Heap)和非堆(Non-heap)内存
按照官方的说法:“Java虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配。堆是在Java虚拟机启动时创建的。”“在JVM中堆之外的内存称为非堆内存(Non-heap memory)”。
可以看出JVM主要管理两种类型的内存
7. 何时会抛出OutOfMemoryException
并不是内存被耗空的时候才抛出
JVM98%的时间都花费在内存回收
每次回收的内存小于2%
8. 内存泄漏与内存溢出
l 内存泄露是指你的应用使用资源之后没有及时释放,导致应用内存中持有了无用的资源,这是一种状态描述;
l 存溢出是指你的应用的内存已经不能满足正常使用了,堆栈已经达到系统设置的最大值,进而导致崩溃,这事一种结果描述;
l 通常都是由于内存泄露导致堆栈内存不断增大,从而引发内存溢出。
9. 对象存活判定
[1] 引用计数法
给对象添加一个引用计数器,每当有一个地方引用了该对象,计数器就加1;当引用失效,计数器就减1;任何时刻的计数器为0的对象就是不可能在被使用的对象。虽然是一个实现简单有效的算法,但是很难解决对象之间循环相互引用的问题。
[2] 根搜索算法(GC Roots Tracing)
现在主流的JVM算法来标记“死去”的对象。
算法的基本思路是通过一些称为“GC-Roots”的对象,从这些节点往下延伸,搜索所走过的路叫引用链,当一个对象没有被引用链搜索到,则证明该对象不可用。如下图Object-5\6\7是不可用的:
可用作GC-Roots的对象有:
1.方法区的静态类型引用的对象
2.方法区的常量引用的对象
3.方法栈中引用
10. 垃圾收集的方法有哪些?
[1] 标记-清除:
先标记那些要被回收的对象,然后统一回收。这种方法很简单,但是会有两个主要问题:1.效率不高,需要遍历整个堆,标记和清除的效率都很低;2.会产生大量不连续的内存碎片,导致以后程序在分配较大的对象时,由于没有充足的连续内存而提前触发一次GC动作。3.在进行GC时还要停掉当前运行的应用程序。
[2] 复制算法:
为了解决效率问题,复制算法将可用内存按容量划分为相等的两部分,然后每次只使用其中的一块,当一块内存用完时,就将还存活的对象复制到第二块内存上,然后一次性清除完第一块内存,再将第二块上的对象复制到第一块。但是这种方式,内存的代价太高,每次基本上都要浪费一半的内存。
后来将该算法进行了改进,内存区域不再是按照1:1去划分,而是将内存划分为8:1:1三部分,较大那份内存交Eden区,其余是两块较小的内存区叫Survior区。每次都会优先使用Eden区,若Eden区满,就将对象复制到第二块内存区上,然后清除Eden区,如果此时存活的对象太多,以至于Survivor不够时,会将这些对象通过分配担保机制复制到老年代中。
[3] 标记-整理
该算法主要是为了解决标记-清除,产生大量内存碎片的问题;当对象存活率较高时,也解决了复制算法的效率问题。它的不同之处就是在清除对象的时候现将可回收对象移动到一端,然后清除掉端边界以外的对象,这样就不会产生内存碎片了。
11. GC垃圾回收机制
如果一个对象不在被直接或间接地引用,那么这个对象就成为了「垃圾」(Garbage),它占用的内存需要及时地释放,否则就会引起「内存泄露」。有些语言需要程序员来手动释放内存(回收垃圾),有些语言有垃圾回收机制(GC)。
l 垃圾回收是在后台运行的,是作为一个单独的低优先级的线程运行,不可预知的情况下对内存堆中已经死亡的或者长时间没有使用的对象进行清除和回收,程序员不能实时的调用垃圾回收器对某个对象或所有对象进行垃圾回收,但是我们可以告诉他,尽快回收资源(System.gc和Runtime.getRuntime().gc())
l 垃圾回收器在回收某个对象的时候,首先会调用该对象的finalize方法
12. 垃圾收集器
上面有7中收集器,分为两块,上面为新生代收集器,下面是老年代收集器。如果两个收集器之间存在连线,就说明它们可以搭配使用。
[1] Serial(串行GC)收集器
Serial收集器是一个新生代收集器,单线程执行,使用复制算法。它在进行垃圾收集时,必须暂停其他所有的工作线程(用户线程)。是Jvm client模式下默认的新生代收集器。对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,专心做垃圾收集自然可以获得最高的单线程收集效率。
[2] ParNew(并行GC)收集器
ParNew收集器其实就是serial收集器的多线程版本,除了使用多条线程进行垃圾收集之外,其余行为与Serial收集器一样。
[3] Parallel Scavenge(并行回收GC)收集器
Parallel Scavenge收集器也是一个新生代收集器,它也是使用复制算法的收集器,又是并行多线程收集器。parallel Scavenge收集器的特点是它的关注点与其他收集器不同,CMS等收集器的关注点是尽可能地缩短垃圾收集时用户线程的停顿时间,而parallel Scavenge收集器的目标则是达到一个可控制的吞吐量。吞吐量= 程序运行时间/(程序运行时间 + 垃圾收集时间),虚拟机总共运行了100分钟。其中垃圾收集花掉1分钟,那吞吐量就是99%。
[4] Serial Old(串行GC)收集器
Serial Old是Serial收集器的老年代版本,它同样使用一个单线程执行收集,使用“标记-整理”算法。主要使用在Client模式下的虚拟机。
[5] Parallel Old(并行GC)收集器
Parallel Old是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。
[6] CMS(并发GC)收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。CMS收集器是基于“标记-清除”算法实现的
[7] G1收集器
G1(Garbage First)收集器是JDK1.7提供的一个新收集器,G1收集器基于“标记-整理”算法实现,也就是说不会产生内存碎片。还有一个特点之前的收集器进行收集的范围都是整个新生代或老年代,而G1将整个Java堆(包括新生代,老年代)。
13. JVM优化
Ø 如何将新对象预留在年轻代
Full GC的成本远远高于Minor GC,因此某些情况下需要尽可能将对象分配在年轻代,可以为应用程序分配一个合理的年轻代空间,以最大限度避免新对象直接进入年老代的情况发生。
Ø 如何让大对象进入年老代
因为大对象出现在年轻代很可能扰乱年轻代GC,可以使用参数-XX:PetenureSizeThreshold设置大对象直接进入年老代的阈值。当对象的大小超过这个值时,将直接在年老代分配。
Ø 如何设置对象进入年老代的年龄
堆中的每一个对象都有自己的年龄。一般情况下,年轻对象存放在年轻代,年老对象存放在年老代。为了做到这点,虚拟机为每个对象都维护一个年龄。如果对象在Eden区,经过一次GC后依然存活,则被移动到Survivor区中,对象年龄加1。以后,如果对象每经过一次GC依然存活,则年龄再加1。当对象年龄达到阈值时,就移入年老代,成为老年对象。这个阈值的最大值可以通过参数-XX:MaxTenuringThreshold来设置,默认值是15。虽然-XX:MaxTenuringThreshold的值可能是15或者更大,但这不意味着新对象非要达到这个年龄才能进入年老代。事实上,对象实际进入年老代的年龄是虚拟机在运行时根据内存使用情况动态计算的,这个参数指定的是阈值年龄的最大值。
Ø 稳定的Java堆VS动荡的Java堆
一般来说,稳定的堆大小对垃圾回收是有利的。获得一个稳定的堆大小的方法是使-Xms和-Xmx的大小一致,即最大堆和最小堆(初始堆)一样。如果这样设置,系统在运行时堆大小理论上是恒定的,稳定的堆空间可以减少GC的次数。因此,很多服务端应用都会将最大堆和最小堆设置为相同的数值。但是,一个不稳定的堆并非毫无用处。稳定的堆大小虽然可以减少GC次数,但同时也增加了每次GC的时间。让堆大小在一个区间中震荡,在系统不需要使用大内存时,压缩堆空间,使GC应对一个较小的堆,可以加快单次GC的速度。基于这样的考虑,JVM还提供了两个参数用于压缩和扩展堆空间。
Ø 增大吞吐量提升系统性能
吞吐量优先的方案将会尽可能减少系统执行垃圾回收的总时间,故可以考虑关注系统吞吐量的并行回收收集器。在拥有高性能的计算机上,进行吞吐量优先优化
二、Java基础
14. public class和class的区别
class的定义有两种方式: public class类名------------class类名 采用public class来声明class,那么文件名必须和类名完全一致(包括大小写),如果文件名和类名不一致,将会出现错误。在一个java源文件中只能有一个class被public修饰。
15. Java标识符的命名规则
a)标识符是由,数字,字母,下划线和美元符号构成,其他符号不可以
b)必须以字母、下划线或美元符号开头,不能以数字开头
16. 访问控制权限
17. 数据类型
基本数据类型叫做原生类!
类中声明的变量有默认初始值;
方法中声明的变量没有默认初始值,必须在定义时初始化,否则在访问该变量时会出错。
自动转换:(byte,short,char)àintàlong(L)àfloat(F)àdouble
强制转换会导致溢出,精度降低
18. Integer与int的区别
1. 包装类、基本数据类型
2. Null,0
3. Integer中包含更多的与整数操作相关的方法。
19. Math.round();
Math.ceil():向上取整
Math.floor();向下取整
Math.round();四舍五入:+0.5后向下取整
20. Unicode与utf-8的区别
计算机内只能保存101010等二进制数据,那么页面上显示的字符是如何显示出来的呢?
[1] 字符集(Charset) charset=char+set,char是字符,set是集合,charset就是字符的集合。字符集就是这个编码方式涵盖了哪些字符,每个字符都有一个数字序号。
[2] 编码方式(Encoding) 编码方式就是一个字符要怎样编码成二进制字节序,或者反过来怎么解析。 也即给你一个数字序号,要编码成几个字节,字节顺序如何,或者其他特殊规则。
[3] 字形字体(Font) 根据数字序号调用字体存储的字形,就可以在页面上显示出来了。 所以一个字符要显示出来,要显示成什么样子要看字体文件。
综上所述,Unicode只是字符集(一个Unicode是2个字节16位),而没有编码方式。UTF-8是一种Unicode字符集的编码方式,其他还有UTF-16,UTF-32等。而有了字符集以及编码方式,如果系统字体是没有这个字符,也是显示不出来的。
21. 运算符instanceof
//为了避免异常ClassCastException的发生,java引入了instanceof
用法:
1.instanceof运算符的运算结果是boolean类型
2.(引用instanceof类型)-->true/false
例如:(a instanceof Cat)//如果结果是true表示:a引用指向堆中的java对象是Cat类型.
22. ++
[1] 静态语句块中x为局部变量,不影响静态变量x的值
[2] x和y为静态变量,默认初始值为0,属于当前类,其值得改变会影响整个类运行。
[3] java中自增操作非原子性的
main方法中:
执行x--后x=-1
调用myMethod方法,x执行x++结果为-1(后++),但x=0,++x结果1,x=1,则y=0
x+y + ++x,先执行x+y,结果为1,执行++x结果为2,得到最终结果为3
*比如 a=0;(a非long和double类型)这个操作是不可分割的,那么我们说这个操作时原子操作。再比如:a++;这个操作实际是a = a + 1;是可分割的,所以他不是一个原子操作。非原子操作都会存在线程安全问题,需要我们使用同步技术(sychronized)来让它变成一个原子操作。一个操作是原子操作,那么我们称它具有原子性。
23. ++i与i++
看一些视频教程里面写for循环的时候都是写 ++i 而不是 i++,上网搜索了一下,原来有效率问题
++i相当于下列代码
i += 1;
return i;
i++相当于下列代码
j = i;
i += 1;
return j;
当然如果编译器会将这些差别都优化掉,那么效率就都差不多了
24. 三目运算符
数据类型转换:
[1] 存在常量:(false?10:x)
当后两个表达式中有一个是常量,且另外一个类型是T,常量表达式可以用T类型表示,则输出结果是T类型。
[2] 两个变量:(false?i:x)
输出精度高的类型
25. 移位运算符
java中有三种移位运算符
<<左移运算符,num<<1,相当于num乘以2
>>右移运算符,num>>1,相当于num除以2
>>>无符号右移,忽略符号位,空位都以0补齐
如果移动的位数超过了该类型的最大位数,那么编译器会对移动的位数取模。如对int型移动33位,实际上只移动了33/2=1位。
26. 运算符优先级
27. equals()和==
[1] = =
对于基本数据类型,等号比较的是值,对于引用类型,比较的是引用的内存地址
[2] equals( ) //比较两个引用的内存地址(底层源码就是= =)
public boolean equals(Objectob j){
return(this==obj);//比较内存地址
}
如果一个类没有自己定义equals方法,它默认的equals方法(从Object类继承的)就是使用==操作符
在现实的业务逻辑中,需要重写equals方法
String类中已经重写了Object中的equals方法,所以比较的是具体的内容。
下面的代码有什么不妥之处?
1. if(username.equals(“zxx”){}
username可能为NULL,会报空指针错误;改为"zxx".equals(username)
2. int x = 1;
return x==1?true:false; 这个改成return x==1;就可以!
28. 在JAVA中如何跳出当前的多重嵌套循环
在Java中,要想跳出多重循环,可以在外面的循环语句前定义一个标号,然后在里层循环体的代码中使用带有标号的break语句,即可跳出外层循环。例如,
ok:
for(int i=0;i<10;i++) {
for(int j=0;j<10;j++) {
System.out.println(“i=” + i + “,j=” + j);
if(j == 5) break ok;
}
}
另外,我个人通常并不使用标号这种方式,而是让外层的循环条件表达式的结果可以受到里层循环体代码的控制,例如,要在二维数组中查找到某个数字。
int arr[][] ={{1,2,3},{4,5,6,7},{9}};
boolean found = false;
for(int i=0;i<arr.length&& !found;i++) {
for(int j=0;j<arr[i].length;j++){
System.out.println(“i=” + i + “,j=” + j);
if(arr[i][j] ==5) {
found = true;
break;
}
}
29. 面向对象的三大特性
l 封装:属性私有化,对外提供公开的SET、GET方法,使程序更加健壮
l 继承:子类可以继承父类的东西,这样有利于代码的重用。
l 多态:指一个类实例的相同方法在不同情形有不同表现形式。多态机制使具有不同内部结构的对象可以共享相同的外部接口。这意味着,虽然针对不同对象的具体操作不同,但通过一个公共的类,它们(那些操作)可以通过相同的方式予以调用。使用多态不但能减少编码的工作量,还能使代码之间的耦合度降低,大大提高程序的可维护性及可扩展性。
关于java语言中向上转型和向下转型
1.向上转型(upcasting)自动类型转换:子--->父Animal a1=new Cat();父类型的引用指向子类型对象
2.向下转型(downcasting)强制类型转换:父--->子Catc1=(Cat)a2;
l 多态的条件是:
a) 有继承或实现
b) 有方法的覆盖或实现
c) 父类对象(接口)指向子类对象
30. 五大原则
[1] 单一职责原则SRP(Single Responsibility Principle)
是指一个类的功能要单一,不能包罗万象。如同一个人一样,分配的工作不能太多,否则一天到晚虽然忙忙碌碌的,但效率却高不起来。
[2] 开放封闭原则OCP(Open-Close Principle)
一个模块在扩展性方面应该是开放的而在更改性方面应该是封闭的。比如:一个网络模块,原来只服务端功能,而现在要加入客户端功能,那么应当在不用修改服务端功能代码的前提下,就能够增加客户端功能的实现代码,这要求在设计之初,就应当将服务端和客户端分开,公共部分抽象出来。
[3] 里氏替换原则LSP(the Liskov Substitution Principle LSP)
子类应当可以替换父类并出现在父类能够出现的任何地方。比如:公司搞年度晚会,所有员工可以参加抽奖,那么不管是老员工还是新员工,也不管是总部员工还是外派员工,都应当可以参加抽奖,否则这公司就不和谐了。
[4] 依赖倒置原则DIP(the Dependency Inversion Principle DIP)
传统的结构化编程中,最上层的模块通常都要依赖下面的子模块来实现,也称为高层依赖低层!所以DIP原则就是要逆转这种依赖关系,让高层模块不要依赖低层模块,所以称之为依赖倒置原则!
[5] 接口分离原则ISP(the Interface Segregation Principle ISP)
模块间要通过抽象接口隔离开,而不是通过具体的类强耦合起来
1. 覆盖(Override)
继承最基本的作用:代码重用。继承最重要的作用:方法可以重写。
l 方法名,返回值类型,参数列表必须相同
l 修饰符:重写的方法不能比被重写的方法拥有更低的访问权限。
l 重写的方法不能比被重写的方法抛出更宽泛的异常。
l 私有的方法不能被覆盖。(多态之后讲)
l 构造方法无法被覆盖。因为构造方法无法被继承。
l 静态的方法不存在覆盖。(多态之后讲)
l 覆盖指的是成员方法,和成员变量无关。
2. 重载(Overload)
l 方法名必须相同,
l 参数列表必须不同(类型、个数、顺序)
l 返回类型、修饰符也可以不同
3. 构造方法
[1] 不能有返回值
[2] 构造方法的作用
a) 创建对象:new构造方法名(实参);在堆中开辟空间存储对象
b) 初始化成员变量
[3] 如果一个类没有提供任何构造方法,则系统默认提供无参构造方法。
如果手动提供提供构造方法,系统将不再提供任何构造方法。
[4] 构造方法无法被继承,可以被重载,但不可以被覆盖
4. 传值与引用
[1] 不管参数类型是什么,全部是传递参数的副本。
如果参数是基本数据类型,则传递的是值的副本,如果参数是对象,则传递的是该对象引用的副本,因为对象存放在堆里,较基本数据类型,占内存比较大。
[2] 成员变量在什么时候赋值?只有在调用构造方法时才会赋值。
[3] 若把引用的副本看作是值,则有以下说法:不管是基本类型还是对象类型都值传递,
[4] 按值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本。因此,如果函数修改了该参数,仅改变副本,而原始值保持不变。按引用传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本。因此,如果函数修改了该参数,调用代码中的原始值也随之改变。
5. static
static表示“全局”或者“静态”的意思,用来修饰成员变量和成员方法,也可以形成静态static代码块。
类名.静态方法名(参数列表...)
类名.静态变量名
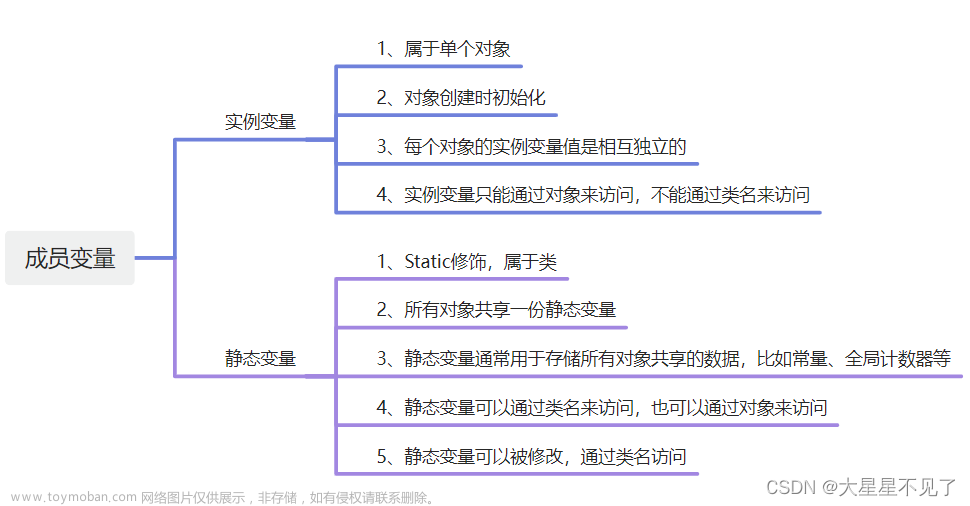
[1] static变量
被static修饰的变量,叫静态变量或类变量,没有修饰的变量,叫实例变量。
n 静态变量在类加载时初始化,静态变量在内存中只有一个拷贝(节省内存),JVM只为静态分配一次内存,在加载类的过程中完成静态变量的内存分配,可用类名直接访问(方便),当然也可以通过对象来访问(但是这是不推荐的)。
n 实例变量,每创建一个实例,就会为实例变量分配一次内存,实例变量可以在内存中有多个拷贝,互不影响(灵活)。
所以一般在需要实现以下两个功能时使用静态变量:
1) 在对象之间共享值时
2) 方便访问变量时
[2] 静态方法
a) 静态方法可以直接通过类名调用,任何的实例也都可以调用。
b) 一般情况下,工具类中的方法都是静态方法。
c) 因为static方法独立于任何实例,因此static方法必须被实现,而不能是抽象的abstract。
d) 它们仅能调用其他的static方法、static数据,在一个static方法中引用任何实例变量都是非法的
e) 它们不能以任何方式引用this或super
f) static方法是类方法,在编译时静态绑定的(private、static、final修饰的方法是静态绑定的),所以他们修饰的方法不能实现多态,当然不需要被子类覆盖了(子类覆盖父类方法是为了实现多态)。能被继承。而其他的方法在运行时动态绑定。
[3] static代码块
static代码块也叫静态代码块,可以有多个,位置可以随便放,它不在任何的方法体内,JVM加载类时会执行这些静态的代码块,如果static代码块有多个,JVM将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次。
实例语句块,{system.out.print(“A“)}在构造方法前执行。
[4] static和final一块用表示什么?
static final用来修饰成员变量和成员方法,可简单理解为“全局常量”!
对于变量,表示一旦给值就不可修改,并且通过类名可以访问。
对于方法,表示不可覆盖,并且可以通过类名直接访问。
6. this,super
[1] this
l this是引用类型,在堆中的每一个对象上都有this,保存内存地址指向自身
this不能用在静态环境中(static变量,static方法,static语句块),只能用在成员方法和构造方法中,代表当前对象,静态方法的执行根本就不需要对象的存在
l this( )用在构造方法中,用来调用另外一个构造方法,必须在第一行
l this可以用来区分成员变量与局部变量 this.age=age;
[2] super
l super不能应用在静态方法中,只能应用在成员方法和构造方法中,(和this是一样的)
l super(参数列表 )可以在子类构造方法中调用父类的构造方法,用“super(参数列表)”的方式调用,参数不是必须的。同时还要注意的一点是:“super(参数列表)”这条语句只能用在子类构造方法体中的第一行。
l super.方法名(参数列表)可以在子类中调用父类的成员方法,子类的成员方法覆盖了父类的成员方法时,此时,用“super.方法名(参数列表)”的方式访问父类的方法。
l 区分变量:当子类方法中的局部变量或成员变量与父类成员变量同名时,也就是子类局部变量覆盖父类成员变量时,用“super.成员变量名”来引用父类成员变量。当然,如果父类的成员变量没有被覆盖,也可以用“super.成员变量名”来引用父类成员变量,不过这是不必要的。
l 子类中没有显示调用构造方法,会默认调用直接父类的无参构造方法,此种情况下如果父类中没有无参构造方法,那么编译时将会失败。
l 一个构造方法第一行如果没有this(...);也没有显示的去调用super(...);系统会默认调用super();
l super(....)和this(....)不能共存。
l super(...);调用了父类中的构造方法,但是并不会创建父类对象。
[3] this和super的异同
l super( )和this( )类似,区别是,super( )从子类中调用父类的构造方法,this( )调用同一类的构造方法。
l this( )和super( )不能同时出现在一个构造函数里面,因为this( )必然会调用其它的构造函数,其它的构造函数必然也会有super( )语句的存在,所以在同一个构造函数里面有相同的语句,就失去了语句的意义,编译器也不会通过。
7. 使用final关键字修饰一个变量时,是引用不能变,还是引用的对象不能变?
使用final关键字修饰一个变量时,是指引用变量不能变,引用变量所指向的对象中的内容还是可以改变的。例如,对于如下语句:
final StringBuffer a=new StringBuffer("immutable"); 执行如下语句将报告编译期错误:
a=new StringBuffer(""); 但是,执行如下语句则可以通过编译:
a.append(" broken!");
有人在定义方法的参数时,可能想采用如下形式来阻止方法内部修改传进来的参数对象:
public void method(final StringBuffer param){
}
实际上,这是办不到的,在该方法内部仍然可以增加如下代码来修改参数对象:
param.append("a");
8. final、finalize、finally
通常考试时给一张纸,写答案。三个词的概念完全不一样
[1] final
n final用来修饰类,无法被继承(用final修饰的类叫做最终类!!!)
n final用来修饰方法,无法被覆盖
n final用来修局部变量,一旦赋值,无法被改变
n final用来修成员变量,需要手动赋值
n final修成员变量与static连用,称为常量,常量全部大写
[2] finalize( )
是Object一个方法的名字,垃圾回收器在回收java对象之前会先自动调用java对象的finalize方法。
[3] finally
异常处理机制中的语句块,finally语句块总是会执行。
9. 抽象类
1. 抽象类不能被final修饰
2. 抽象类无法被实例化,但是有构造方法,构造方法,给子类创建对象用
4. 抽象类中可以定义抽象方法abstract void m1();到了一个强制的约束作用,要求子类必须实现
5. 非抽象类中不可以有抽象方法
6. 一个非抽象类继承抽象类,必须将其抽象方法全部实现
10. 接口
1. 接口是特殊类型的抽象类,特殊在接口是完全抽象的
2. 接口中没有构造方法,无法被实例化
3. 接口与接口之间可以实现多继承interface emplements A,B,C{},但接口之间不可以实现,解决了Java单继承的问题
4. 一个类可以实现多个接口
5. 一个非抽象类实现接口,必须把接口中全部方法实现&覆盖&重写
6. 使项目分层,所有层均面向接口编程,开发效率高,降低耦合
11. 接口和抽象类的区别
l 接口只能做方法申明,抽象类中可以做方法申明,也可以做方法实现
l 接口里定义的变量只能是公共的静态的常量,抽象类中的变量是普通变量。
l 抽象类里的抽象方法必须全部被子类所实现,如果子类不能全部实现父类抽象方法,那么该子类只能是抽象类。
同样,一个实现接口的时候,如不能全部实现接口方法,那么该类也只能为抽象类。
l 接口可继承接口,并可多继承接口,但类只能单根继承。
12. abstract的method是否可同时是static, native,synchronized?
Abctract:是用来继承的
另外两个必须有方法体
13. Object基类的方法
方法名
返回类型
作用
clone( )
Object
创建并返回此对象的一个副本
equals( )
boolean
指示其他某个对象是否与此对象“相等”
finalize( )
void
当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法
getClass( )
Object
返回此Object的运行时类
hashCode( )
Int
返回该对象的哈希码值
notify( )
Void
唤醒在此对象监视器上等待的单个线程
notify All( )
Void
唤醒在此对象监视器上等待的所有线程
toString( )
String
返回该对象的字符串表示
Wait( )
void
在其他线程调用此对象的notify()方法或notify
写clone()方法时,通常都有一行代码,是什么?
clone 有缺省行为,
super.clone();
因为首先要把父类中的成员复制到位,然后才是复制自己的成员。
14. HashCode和Equals方法
1、如果两个对象相同(即用equals比较返回true),那么它们的hashCode值一定要相同;
2、如果两个对象的hashCode相同,它们并不一定相同(即用equals比较返回false)。
为了提高程序的效率才实现了hashcode方法,先进行hashcode的比较,如果不同,那没就不必在进行equals的比较了,这样就大大减少了equals比较的次数,这对比需要比较的数量很大的效率提高是很明显的,一个很好的例子就是在集合中的使用;set集合是无序的,因此是不能重复的,那么怎么能保证不能被放入重复的元素呢,但靠equals方法一样比较的
话,如果原来集合中以后又10000个元素了,那么放入10001个元素,难道要将前面的所有元素都进行比较,看看是否有重复,欧码噶的,这个效率可想而知,因此hashcode就应遇而生了,java就采用了hash表,利用哈希算法(也叫散列算法),就是将对象数据根据该对象的特征使用特定的算法将其定义到一个地址上,那么在后面定义进来的数据只要看对应的hashcode地址上是否有值,那么就用equals比较,如果没有则直接插入,只要就大大减少了equals的使用次数,执行效率就大大提高了。
继续上面的话题,为什么必须要重写hashcode方法,其实简单的说就是为了保证同一个对象,保证在equals相同的情况下hashcode值必定相同,如果重写了equals而未重写hashcode方法,可能就会出现两个没有关系的对象equals相同的(因为equal都是根据对象的特征进行重写的),但hashcode确实不相同的
15. 内部类
1. 静态内部类
1) 静态内部类可以等同看做静态变量,可用访问控制权限的修饰符修饰。
2) 内部类重要的作用:可以访问外部类中私有的数据。
3) 静态内部类可以直接访问外部类的静态数据,无法直接访问成员。
2. 成员内部类
1) 成员内部类可以等同看做成员变量,可用访问控制权限的修饰符修饰
2) 成员内部类中不能有静态声明.
3) 成员内部类可以访问外部类所有的数据.
3. 局部内部类
1) 局部内部类等同于局部变量,不能用访问控制权限修饰符修饰。
2) 重点:局部内部类在访问局部变量的时候,局部变量必须使用final修饰。
3) 局部内部类不能有静态声明
4. 匿名内部类
指的是类没有名字的类
.
16. 异常定义
常见的运行时异常(RuntimeException)
java.lang.ArithmeticException
算术异常
5/0
ClassCastException
类型转化异常
Cat cat=new Dog( );
IllegalArgumentException
非法参数异常
IndexOutOfBoundsException
下表越界异常)
NullPointerException
空指针异常
SecurityException
由安全管理器抛出的异常,指示存在安全侵犯。
1.异常是什么?
第一,异常模拟的是现实世界中“不正常的”事件。
第二,java中采用“类”去模拟异常。
第三,类是可以创建对象的。
NullPointerExceptione=0x1234;
e是引用类型,e中保存的内存地址指向堆中的“对象”,这个对象一定是NullPointerException类型。
这个对象就表示真实存在的异常事件(实例)。
NullPointerException是一类异常。
“抢劫”就是一类异常。----->类
“张三被抢劫”就是一个异常事件---->对象
2.异常机制的作用?
java语言为我们提供一种完善的异常处理机制,
作用是:程序发生异常事件之后,为我们输出详细的信息,
程序员通过这个信息,可以对程序进行一些处理,使程序更加健壮。
本质:程序执行过程中发生了算数异常这个事件,JVM为我们创建了一个ArithmeticException类型的对象。
并且这个对象中包含了详细的异常信息,并且JVM将这个对象中的信息输出到控制台。
17. 异常的分类
18. 处理异常的两种方式
[1] 声明抛出throws
以下程序演示第一种方式:声明抛出,在方法声明的位置上使用throws关键字向上抛出异常。
1. 深入throws
2. 底层实现原理
[2] try...catch...
语法:
try{
可能出现异常的代码;
}catch(异常类型1变量){
处理异常的代码;
}catch(异常类型2变量){
处理异常的代码;
}....
1) catch语句块可以写多个.
2) try中的代码出现异常时,出现异常下面的代码不会执行
3) 但是从上到下catch,必须从小类型异常到大类型异常进行捕捉。
4) try...catch...中最多执行1个catch语句块。执行结束之后try...catch...就结束了。
19. getMessage和printStackTrace
何取得异常对象的具体信息,常用的方法主要有两种:
取得异常描述信息:getMessage()
取得异常的堆栈信息(比较适合于程序调试阶段):printStackTrace()
20. 关于finally语句块
1.finally语句块可以直接和try语句块联用。try....finally...
2.try...catch....finally也可以.
3.在finally语句块中的代码是一定会执行的。
4.System.exit(0);//正常退出JVM只要在执行finally语句块之前退出了
JVM,则finally语句块不会执行
5. finally例题
6. finally语句块是一定会执行的,所以通常在程序中为了保证某资源一定会释放,所以一般在finally语句块中释放资源。
7.try和finally中都有return语句,执行哪一个return?
执行try块,执行到return语句时,先执行return的语句,但是不返回到main 方法,接下来执行finally块,遇到finally块中的return语句,执行,并将值返回到main方法,这里就不会再回去返回try块中计算得到的值
8.重写的方法不能比被重写的方法抛出更宽泛的异常.
21. 受控异常和非受控异常
受控异常:CheckedException,这类异常必须写try{}catch{},或者throw抛出,否则编译通不过。
非受控异常:UncheckedException,这类异常也叫做运行时异常(与非受控异常字数相等),这类异常不需要try{}catch{},也不需要throw抛出,编译能通过。
为什么要使用非受控异常?为了简化代码。试想一下,如果所有可能出现异常的地方(比如访问数组元素可能会越界、调用对象方法,对象可能为null),我们都写try{}catch{},或者throw抛出,那么代码肯定冗余的不成样子了。也就是说,采用非受控异常(运行时异常)可以减少代码的污染。
对于非受控异常(运行时异常),因为不需要额外处理,也能编译通过,我们可以进行预先检查,比如访问数组元素时,我们预先检查是否越界,调用对象方法时,预先检查对象是否为null
22. throw和throws
[1] throws出现在方法声明的后面,异常由方法的调用者处理;而throw出现在方法体,由方法体内的语句来处理。
[2] throws表示出现异常的一种可能性,并不一定会发生这些异常;throw则是抛出了异常,执行throw则一定抛出了某种异常,是一个实例。
[3] 两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异常,真正的处理异常由函数的上层调用处理。
23. String和StringBuffer和StringBuilde
[1] String
String类是不可变类,也就是说String对象声明后,将不可修改。
1.如果是采用双引号引起来的字符串常量,首先会到常量池(方法区)中去查找,如果存在就不再分配,如果不存在就分配,常量池中的数据是在编译期赋值的,也就是生成class文件时就把它放到常量池里了,所以s1和s2都指向常量池中的同一个字符串“abc”
2.关于s3,s3采用的是new的方式,在new的时候存在双引号,所以他会到常量区中查找“abc”,而常量区中存在“abc”,所以常量区中将不再放置字符串,而new关键子会在堆中分配内存,所以在堆中会创建一个对象abc,s3会指向abc
3.如果比较s2和s3的值必须采用equals,String已经对eqauls方法进行了覆盖 。
31. String s = new String("abc");
32. String s1 = "abc";
33. String s2 = new String("abc");
34.
35. System.out.println(s == s1);
36. System.out.println(s == s2);
37. System.out.println(s1 == s2);
请问以上程序执行结果是什么?
第一句执行后内存中有两个 对象,而不是一个。一个由new String("abc")中的"abc"在String Pool里生成一个值为"abc"的对象;第二个由new在堆里产生一个值为"abc"的对象,该对象完全是String Pool里的"abc"的一个拷贝。变量s最后指向堆中产生的"abc"对象;
第二句执行时,s1先去String Pool找是否有值为"abc"的对象,很显然在上一步中java已经在String Pool里生成一个"abc"对象了,所以s1直接指向String Pool中的这个"abc";
第三句中又有一个new,在java中凡遇到new时,都会在堆里产生一个新的对象。因此,该句执行后堆里又多了一个"abc"对象,这与执行第一句后生成的"abc"是不同的两个对象,s2最后指向这个新生成的对象。
因此,执行后面的打印语句的结果是三个false
String常用方法
endWith 判断字符串是否以指定的后缀结束 startsWith 判断字符串是否以指定的前缀开始 equals 字符串内容比较 equalsIgnoreCase 字符串内容比较,忽略大小写 indexOf 取得指定字符串在字符串的位置 lastIndexOf 返回最后一次出现的位置 length 取得字符串长度 replaceAll 替换字符串中指定的内容 split 根据指定的表达式拆分字符串 substring 截子串 tirm 去前尾空格 valueOf 将其他类型转换成字符串
[2] StringBuffer
先申请一块内存,存放字符序列,如果字符序列满了,会重新改变缓存区的大小,以容纳更多的字符序列。StringBuffer是可变对象,这个是String最大的不同。
[3] StringBuilder
用法同StringBuffer,StringBuilder和StringBuffer的区别是StringBuffer中所有的方法都是同步的,是线程安全的,但速度慢,StringBuilder的速度快,但不是线程安全的。
24. java中replace()和replaceAll()区别
[1] replace的参数是char和CharSequence(串),即可以支持字符的替换,也支持字符串的替换
[2] replaceAll的参数是regex,即基于规则表达式的替换,比如,可以通过replaceAll("\\d","*")把一个字符串所有的数字字符都换成星号;
[3] 相同点:都是全部替换,即把源字符串中的某一字符或字符串全部换成指定的字符或字符串
[4] replaceFirst():如果只想替换第一次出现的,可以使用replaceFirst(),这个方法也是基于规则表达式的替换,但与replaceAll()不同的是,只替换第一次出现的字符串;
[5] 如果replaceAll()和replaceFirst()所用的参数据不是基于规则表达式的,则与replace()替换字符串的效果是一样的,即这两者也支持字符串的操作;
[6] 还有一点注意:执行了替换操作后,源字符串的内容是没有发生改变的.
举例如下:
关于字符串中的"\"替换:
'\'在java中是一个转义字符,所以需要用两个代表一个。例如System.out.println("\\");只打印出一个"\"。但是'\'也是正则表达式中的转义字符(replaceAll的参数就是正则表达式),需要用两个代表一个。所以:\\\\被java转换成\\,\\又被正则表达式转换成\。
将字符串中的'/'替换成'\':
25. 枚举类型
需求:定义一个方法,该方法的作用是计算两个int类型数据的商。
如果计算成功则该方法返回1,如果执行失败则该方法返回0
程序执行成功,但是该程序存在风险,分析:存在什么风险?返回类型int范围太广
程序中的问题能在编译阶段解决的,绝对不会放在运行期解决。所以以下程序可以引入“枚举类型”。
三、Java容器框架
Java容器类库一共有两种主要类型Collection(单列集合)和Map(双列集合)。
所有的java容器类都可以自动调整自己的尺寸。
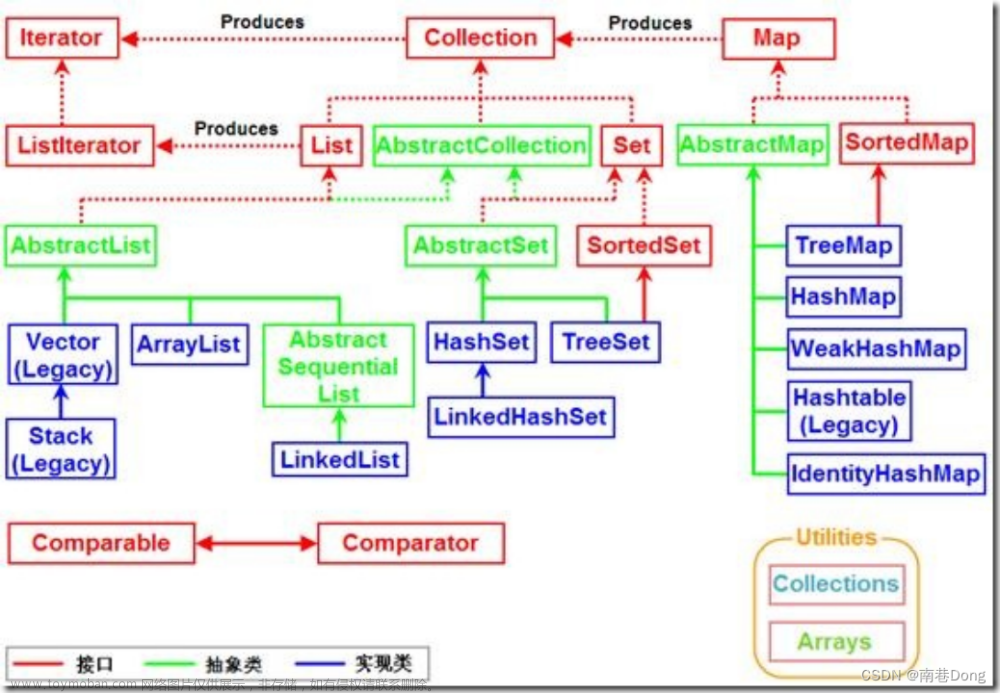
26. Collection
Collection接口是Set、List和Queue接口的父接口。
27. List
List:代表有序、可重复的集合。所以与Set相比,增加了与索引位置相关的操作;
1. ArrayList集合底层是数组。数组是有下标的。擅长随机访问,但在List中间插入、删除、移动元素较慢。
ArrayList集合底层默认初始化容量是10.扩大之后的容量是原容量的1.5倍.
2. LinkedList:插入、删除、移动元素方便,随机访问比较差。
3. Vector集合底层是数组,默认初始化容量也是10.扩大之后的容量是原容量的2倍,线程安全,效率较低
4. ArrayList与Vector区别:
线程不安全VS线程安全:对于单线程的程序选用ArrayList,效率高
扩容1.5VS扩容2
5. 如果优化ArrayList和Vector?
尽量减少扩容操作,因为扩容需要数组拷贝。数组拷贝很耗内存。
一般推荐在创建集合的时候指定初始化容量。
28. List list=new和ArrayList list=new这两种方式有什么区别,为什么大多数情况下会用第一种。
List是一个接口,而ArrayList 是一个类。
List list = new ArrayList();这句创建了一个ArrayList的对象后把上溯到了List。此时它是一个List对象了,有些ArrayList有但是List没有的属性和方法,它就不能再用了。而ArrayList list=new ArrayList();创建一对象则保留了ArrayList的所有属性。
为什么一般都使用 List list = new ArrayList() ,而不用 ArrayList alist = new ArrayList()呢?
问题就在于List有多个实现类,如 LinkedList或者Vector等等,现在你用的是ArrayList,也许哪一天你需要换成其它的实现类呢?,这时你只要改变这一行就行了:List list = new LinkedList(); 其它使用了list地方的代码根本不需要改动。假设你开始用 ArrayList alist = new ArrayList(), 这下你有的改了,特别是如果你使用了 ArrayList特有的方法和属性。 ,如果没有特别需求的话,最好使用List list = new LinkedList(); ,便于程序代码的重构. 这就是面向接口编程的好处。
29.
30. Set
Set代表无序、不可重复的集合,判断两个对象是否相同则是根据equals方法。
1. HashSet:底层是HashMap,HashMap底层采用了哈希表数据结构,查找插入优于TreeSet。
HashSet其实是HashMap中的key部分。HashSet有什么特点,HashMap中的key应该具有相同的特点。
HashMap和HashSet初始化容量都是16,默认加载因子是0.75。
存储在HashSet集合或者HashMap集合key部分的元素,需要同时重写hashCode+equals
2. TreeSet:实现SortedSet集合接口,其中的元素自动排序。因为被存储的元素实现了Comparable接口,SUN编写TreeSet集合在添加元素的时候,会调用compareTo方法完成比较。
3. LinkedHashSet:使用链表结合散列函数。
4. Queue新增的体系集合,代表一种队列集合实现。
31. Iterator
[1] list删除元素操作
错误的方法:
如果在循环的过程中调用集合的remove()方法,就会导致循环出错,例如:
for(inti=0;i<list.size();i++){
list.remove(...);
}
循环过程中list.size()的大小变化了,就导致了错误。
正确的方法:
如果你想在循环语句中正确并安全的删除集合中的某个元素,就要用迭代器iterator的remove()方法,因为它的remove()方法不仅会删除元素,还会维护一个标志,用来记录目前是不是可删除状态,例如,你不能连续两次调用它的remove()方法,调用之前至少有一次next()方法的调用。
32. 看需求选集合
是否是键值对象形式:
是:Map
键是否需要排序:
是:TreeMap
否:HashMap
不知道,就使用HashMap。
否:Collection
元素是否唯一:
是:Set
元素是否需要排序:
是:TreeSet
否:HashSet
不知道,就使用HashSet
否:List
要安全吗:
是:Vector(其实我们也不用它,后面我们讲解了多线程以后,我在给你回顾用谁)
否:ArrayList或者LinkedList
增删多:LinkedList
查询多:ArrayList
不知道,就使用ArrayList
不知道,就使用ArrayList
33. 集合的常见方法及遍历方式
Collection:
add()
remove()
contains()
iterator()
size()
遍历:
增强for
迭代器
|--List
get()
遍历:
普通for
|--Set
Map:
put()
remove()
containskey(),containsValue()
keySet()
get()
values()
entrySet()
size()
遍历:
根据键找值
根据键值对对象分别找键和值
34. Map
Map代表具有映射关系的集合,实现将唯一键映射到特定的值上。
关于Map集合中常用的方法:
clear() 清空Map isEmpty() 判断该集合是否为空 size() 获取Map中键值对的个数 put(Object key,Object value) 向集合中添加键值对 get(Object key) 通过key获取value containsKey(Object key) 判断Map中是否包含这样的key containValue(Object value) 判断Map中是否包含这样的value remove(Object key) 通过key将键值对删除 values() 获取Map集合中所有的value keySet() 获取Map中所有的key entrySet() 返回此映射中包含的映射关系的Set视图
注意:存储在Map集合key部分的元素需要同时重写hashCode+equals方法.
Hash家族嘛,高逼格,必须一次性两个值存储,就是所谓的键值对.
但是呢,Hash家族内部分为了几个小家族,分别是HashMap,Hashtable,TreeMap. LinkedHashMap
这几个家族呢,对键值对能不能存储null这种不是很安全的"买卖"有不一样的行动.
其中的HashMap家族与Hashtable、TreeMap不同,认为没有风险就没有利润!于是乎,准许自己的键值对都可以为null!
Hashtable与TreeMap一看SUN国王居然默许了HashMap的冒险行为,使得HashMap家族的利润大大增加,这两个家族也不甘寂寞,于是乎也就允许了自己的键值对可以为"",但是不能触碰null的界限.
1. HashMap:HashMap中的key就是HashSet,底层是哈希表/散列表,用于快速查找
HashMap默认初始化容量是16,默认加载因子0.75,键值均可以为null,线程不安全
2. Hashtable默认初始化容量是11,默认加载因子是0.75,键值均不可以为null,线程安全
3. Properties;也是由key和value组成,但是key和value都是字符串类型
dbinfo这样的文件我们称作配置文件,
配置的文件的作用就是:使程序更加灵活。
注意:一般在程序中可变的东西不要写死。推荐写到配置文件中。
运行同样的程序得到不同的结果。
像dbinfo这样一个具有特殊内容的配置文件我们又叫做:属性文件。
java规范中要求属性文件以“.properties”
属性文件中数据要求:
key和value之间可以使用“空格”,“冒号”,“等号”。
如果“空格”,“等号”,“冒号”都有,按最前的作为分隔符。
4. LinkedHashMap:是HashMap的一个子类,保存了记录的插入顺序,在用Iterator遍历LinkedHashMap时,先得到的记录肯定是先插入的.也可以在构造时用带参数,按照应用次数排序。在遍历的时候会比HashMap慢,不过有种情况例外,当HashMap容量很大,实际数据较少时,遍历起来可能会比 LinkedHashMap慢,因为LinkedHashMap的遍历速度只和实际数据有关,和容量无关,而HashMap的遍历速度和他的容量有关。
5. TreeMap:SortedMap中的key特点:无序不可重复,但是存进去的元素可以按照大小自动排列。如果想自动排序:key部分的元素需要,1,实现Comparable接口.2.单独写一个比较器.
35. 解决哈希(HASH)冲突的主要方法(????)
不同的key用同样的Hash算法,可能会得到相同的hash值
[1] 开放定址法
(1)线性探查法(Linear Probing)
插入元素时,如果发生冲突,算法会简单的从该槽位置向后循环遍历hash表,直到找到表中的下一个空槽,并将该元素放入该槽中(会导致相同hash值的元素挨在一起和其他hash值对应的槽被占用)。查找元素时,首先找到散列值所指向的槽,如果没有找到匹配,则继续从该槽遍历hash表,直到:(1)找到相应的元素;(2)找到一个空槽,指示查找的元素不存在,(所以不能随便删除元素);(3)整个hash表遍历完毕(指示该元素不存在并且hash表是满的)用线性探测法处理冲突,思路清晰,算法简单,但存在下列缺点:
Ø 处理溢出需另编程序。一般可另外设立一个溢出表,专门用来存放上述哈希表中放不下的记录。此溢出表最简单的结构是顺序表,查找方法可用顺序查找。
Ø 按上述算法建立起来的哈希表,删除工作非常困难。假如要从哈希表HT中删除一个记录,按理应将这个记录所在位置置为空,但我们不能这样做,而只能标上已被删除的标记,否则,将会影响以后的查找。
Ø 线性探测法很容易产生堆聚现象。所谓堆聚现象,就是存入哈希表的记录在表中连成一片。按照线性探测法处理冲突,如果生成哈希地址的连续序列愈长(即不同关键字值的哈希地址相邻在一起愈长),则当新的记录加入该表时,与这个序列发生冲突的可能性愈大。因此,哈希地址的较长连续序列比较短连续序列生长得快,这就意味着,一旦出现堆聚(伴随着冲突),就将引起进一步的堆聚。
(2)线性补偿探测法
将线性探测的步长从1改为Q,即将上述算法中的hash = (hash + 1) % m 改为:hash = (hash + Q) % m = hash % m + Q % m,而且要求 Q 与 m 是互质的,以便能探测到哈希表中的所有单元。
【例】PDP-11小型计算机中的汇编程序所用的符合表,就采用此方法来解决冲突,所用表长m=1321,选用Q=25。
(3)随机探测
将线性探测的步长从常数改为随机数,即令: hash = (hash + RN) % m ,其中 RN 是一个随机数。在实际程序中应预先用随机数发生器产生一个随机序列,将此序列作为依次探测的步长。这样就能使不同的关键字具有不同的探测次序,从而可以避 免或减少堆聚。基于与线性探测法相同的理由,在线性补偿探测法和随机探测法中,删除一个记录后也要打上删除标记。
[2] 拉链法
将所有关键字为同义词的结点链接在同一个单链表中。
若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。在拉链法中,装填因子α可以大于1,但一般均取α≤1。
与开放定址法相比,拉链法有如下几个优点:
①拉链法处理冲突简单,且无堆积现象,即非同义词决不会发生冲突,因此平均查找长度较短;
②由于拉链法中各链表上的结点空间是动态申请的,故它更适合于造表前无法确定表长的情况;
③开放定址法为减少冲突,要求装填因子α较小,故当结点规模较大时会浪费很多空间。而拉链法中可取α≥1,且结点较大时,拉链法中增加的指针域可忽略不计,因此节省空间;
④在用拉链法构造的散列表中,删除结点的操作易于实现。只要简单地删去链表上相应的结点即可。而对开放地址法构造的散列表,删除结点不能简单地将被删结点的空间置为空,否则将截断在它之后填人散列表的同义词结点的查找路径。这是因为各种开放地址法中,空地址单元(即开放地址)都是查找失败的条件。因此在用开放地址法处理冲突的散列表上执行删除操作,只能在被删结点上做删除标记,而不能真正删除结点。
拉链法的缺点
指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指
36. HashMap怎么实现按键值对来存取数据呢?
37. 泛型
1.泛型类:classA<T>{}
2.在创建泛型类实例时,需要为其类型变量赋值A<String>a=new A<String>();
*如果创建实例时,不给类型变量赋值,那么会有一个警告!
3.泛型方法:具有一个或多个类型变量的方法,称之为泛型方法!
Class A<T>{
public T fun(T t1){}
}
l fun()方法不是泛型方法!它是泛型类中的一个方法!
l Public <T>T fun(T t1){}-->它是泛型方法
l 泛型方法与泛型类没什么关系,泛型方法不一定非要在泛型类中!
4.泛型在类中或方法中的使用
5.泛型的继承和实现
Class A<T>{}
Class AA extends A<String>{}//不是泛型类,只是它爸爸是泛型类!
l 子类不是泛型类:需要给父类传递类型常量
l 当给父类传递的类型常量为String时,那么在父类中所有T都会被String替换!
l 子类是泛型类:可以给父类传递类型常量,也可以传递类型变量
Class AA1 extends A<Integer>{}
Class AA3<E> extends A<E>{}
泛型的通配符
1.通配符使用的场景
方法的形参!
2.通配符的优点
使方法更加通用!
3.通配符分类
无界通配:?
子类限定:?extends Object
父类限定:?super Integer
4.通配符缺点
使变量使用上不再方便
无界:参数和返回值为泛型的方法,不能使用!
子类:参数为泛型的方法不能使用
父类:返回值为泛型的方法不能使用
5.比较通配符
[1] 为什么引入泛型?
可以统一集合中的数据类型
可以减少强制类型转换.
[2] 泛型语法如何实现?
泛型是一个编译阶段的语法。
在编译阶段统一集合中的类型.
[3] 泛型的优点和缺点?
优点:统一类型,减少强制转换.
缺点:只能存储一种类型.
以下程序没有使用泛型,缺点?
如果集合不使用泛型,则集合中的元素类型不统一。
在遍历集合的时候,只能拿出来Object类型,需要做
大量的强制类型转换。麻烦。
[4] 自定义泛型
38. 可变长参数
39. IO
需要重点掌握的16个流java.io.*
用来读取文件的
1) FileInputStream
2) FileOutputStream
3) FileReader
4) FileWriter
带有缓冲区的
1) BufferedReader
2) BufferedWriter
3) BufferedInputStream
专门读取数据的
1) DataInputStream
2) DataOutputStream
专门读取Java对象
1) ObjectInputStream
2) ObjectOutputStream
转换流(字节流转换成字符流)
1) InputStreamReader
2) OutputStreamWriter
1) PrintWriter
2) PrintStream//标准的输出流(默认输出到控制台)
java语言中的流分为:四大家族(InputStream,OutputStream,Reader,Writer)
40. FileInputStream
定义路径:
String filePath="temp01";//相对路径,相对当前而言,在当前路径下找。
String filePath="D:\\course\\JavaProjects\\02-JavaSE\\chapter08\\temp01";//绝对路径
String filePath="D:/course/JavaProjects/02-JavaSE/chapter08/temp01";
1.创建流
FileInputStream fis=new FileInputStream(filePath);
2.开始读一个字节
Int i1=fis.read();//以字节的方式读取.
如果已经读取到文件的末尾,就会返回-1
循环读取:
Int temp=0;
while((temp=fis.read())!=-1){
System.out.println(temp);
}
//频繁访问磁盘,伤害磁盘,并且效率低。
3.读取多个字节
读取之前在内存中准备一个byte数组,数组相当于缓存,每次读取多个字节存储到byte数组中。不是单字节读取了,效率高。
//准备一个byte数组
4.int fis.available();//返回流中剩余的估计字节数
5.fis.skip(2);//跳过2个字节
6.为了保证流一定会释放,所以在finally语句块中执行fis.close();
41. FileOutputStream
1.创建文件字节输出流
FileOutputStream fos=new FileOutputStream("temp02");//该文件不存在则自动创建.
//谨慎使用,会将源文件内容覆盖.
//以追加的方式写入,不会覆盖前边内容
FileOutputStream fos=new FileOutputStream("temp02",true);
2.开始写
String msg="HelloWorld!";
byte[] bytes=msg.getBytes();//将String转换成byte数组.
fos.write(bytes);//将byte数组中所有的数据全部写入
fos.write(bytes,0,3);//将byte数组的一部分写入
3.最后的时候为了保证数据完全写入硬盘,所以要刷新.
fos.flush();//强制写入.
4.关闭
fos.close();
关于文件复制粘贴
FileInputStream fis=new FileInputStream("InputStream_OutputStream.mdl");
FileOutputStream fos=new FileOutputStream("c:/InputStream_OutputStream.mdl");
//一边读,一边写
byte[] bytes=new byte[1024];//1KB
int temp=0;
while((temp=fis.read(bytes))!=-1){
fos.write(bytes,0,temp);//将byte数组中内容直接写入
}
fos.flush();//刷新
fis.close();//关闭
fos.close();//关闭
42. FileReader
FileReader fr=new FileReader(“Temp01”);
char[]c=newchar[512];//1kb
int temp=0;
while((temp=fr.read(c))!=1){
system.out.print(new String(c,0,temp));
}
43. FileWriter
1.创建文件字符输出流
FileWriter fw=new FileWriter("temp03");//覆盖
FileWriter fw=new FileWriter("temp03",true);//追加
2.开始写
fw.write("李海波!!!!");
3.将char数组的一部分写入
char[] chars={'我','是','中','国','人','!','。','?'};
fw.write(chars,0,5);
4.刷新
fw.flush();
5.关闭
fw.close();
关于文件复制粘贴
FileReader fr=newFileReader("Copy02.java");
FileWriter fw=newFileWriter("c:/Copy02.java");
char[] chars=newchar[512];
int temp=0;
while((temp=fr.read(chars))!=-1){
fw.write(chars,0,temp);
}
fw.flush();
fr.close();
fw.close();
44. Buffered
BufferedInputStream;
BufferedOutputStream;
BufferedReader;带有缓冲区的字符输入流
BufferedWriter;带有缓冲区的字符输出流
他们增强了字节流的读取和写入效率。以BufferedInputStream为例,不带缓冲的操作,每读一个字节就要写入一个字节,如果数据量巨大,频繁访问磁盘,伤害磁盘,由于涉及磁盘的IO操作相比内存的操作要慢很多,所以效率低。带缓冲的流,可以一次读很多字节,但不向磁盘中写入,只是先放到内存里。等凑够了缓冲区大小的时候一次性写入磁盘,这种方式可以减少磁盘操作次数,速度就会提高很多
1. 创建一个带有缓冲区的字符输入流
FileInputStream fis=new FileInputStream("BufferedReaderTest02.java");//文件字节输入流
InputStreamReader isr=new InputStreamReader(fis);//isr是字符流
BufferedReader br=new BufferedReader(isr);//将文件字符输入流包装成带有缓冲区的字符输入流
根据流出现的位置,流又可以分为:包装流或者处理流和节点流(相对而言)
FileReader fr是一个节点流
BufferedReader br是一个包装流,或者处理流.
BufferedReader br=new BufferedReader(new InputStreamReader(new FileInputStream("BufferedReaderTest02.java")));
2.开始读
String temp=null;
while((temp=br.readLine())!=null){//br.readLine()方法读取一行,但是行尾不带换行符.
System.out.println(temp);//输出一行.
}
//关闭
//注意:关闭的时候只需要关闭最外层的包装流。(这里有一个装饰者模式)
br.close();
45. 键盘读入
Scanner是SDK1.5新增的一个类,可是使用该类创建一个对象.
Scanner reader=new Scanner(System.in);
//以前的方式
Scanner s=new Scanner(System.in);//System.in是一个标准的输入流,默认接收键盘的输入.
//程序执行到此处停下来,等待用户的输入
Long a=reader.nextLong();
然后reader对象调用下列方法(函数),读取用户在命令行输入的各种数据类型
next.Byte(),nextDouble(),nextFloat,nextInt(),nextLine(),nextLong(),nextShot()
上述方法执行时都会造成堵塞,等待用户在命令行输入数据回车确认.例如,拥护在键盘输入12.34
hasNextFloat()的值是true
hasNextInt()的值是false
NextLine()等待用户输入一个文本行并且回车,该方法得到一个String类型的数据。
String str=s.next();
System.out.println("您输入了:"+str);
//使用BufferedReader用来接收用户的输入.
BufferedReader br=new BufferedReader(newInputStreamReader(System.in));
//接收输入(每一次都接收一行)
Stringstr=br.readLine();
System.out.println("您输入了:"+str);
br.close();
46. DataInputStream
数据字节输出流.
可以将内存中的"int i=10;"写入到硬盘文件中,
写进去的不是字符串,写进去的是二进制数据,
带类型。
//创建数据字节输出流
DataOutputStream dos=new DataOutputStream(newFileOutputStream("temp05"));
//准备数据
Long l=1000L;
Float f=3.2f;
//写
dos.writeLong(l);
dos.writeFloat(f);
//刷新
dos.flush();
//关闭
dos.close();
//读
//注意:要使用该流读取数据,必须提前知道该文件中数据的存储格式,顺序。
//读得顺序必须和写入的顺序相同。
47. PrintStream
java.io.PrintStream;标准的输出流,默认打印到控制台.以字节方式
java.io.PrintWriter;以字符方式.
//默认是输出到控制台的.
System.out.println("HelloWorld!");
PrintStream ps=System.out;
ps.println("JAVA….");
//可以改变输出方向.
System.setOut(new PrintStream(new FileOutputStream("log")));//log日志文件
//再次输出
//System.out.print("HAHA");
//通常使用上面的这种方式记录日志.
//需求:记录日志,m1方法开始执行的时间和结束的时间.记录到log文件中.
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-ddHH:mm:ssSSS");
System.out.println("m1方法开始执行"+sdf.format(newDate()));
m1();
System.out.println("m1方法执行结束"+sdf.format(newDate()));
}
48. Serializable序列化
待序列化的Java类只需要实现Serializable接口即可。实际的序列化和反序列化工作是通过ObjectOuputStream和ObjectInputStream来完成的。
49. ObjectInputStream
java.io.ObjectOutputStream;序列化JAVA对象到硬盘.(Serial)
java.io.ObjectInputStream;将硬盘中的数据“反序列化”到JVM内存。(DeSerial)
Compile编译(java-->class)
DeCompile反编译.(class-->java)
50. 从文件读数,计算后再写入
51. 进程、线程定义
一个进程对应一个应用程序,例如在windows下启动网易云音乐就表示启动了一个进程。打开英雄联盟,又启动了一个进程。现在的计算机都是支持多进程的。一边玩游戏,一边听歌。
对于单核计算机来讲,在同一个时间点上,游戏进程和音乐进程不是同时执行的,因为CPU在某个时间点上只能做一件事儿。交替执行,交替速度快,不易察觉。提高CPU使用率。
一个进程中可以启动多个线程。多线程的作用是为了提高应用程序的使用率(多个人可以同时访问淘宝)。多个线程之间无缝切换。
l 区别:
进程和线程是不同的操作系统资源管理方式。一个程序至少有一个进程,一个进程至少有一个线程,线程不能够独立执行,必须依存在进程中,进程与进程之间的内存是独立的,一个进程崩溃后,不会对其它进程产生影响。线程是一个进程中的不同执行路径,线程与线程之间共享“堆内存和方法区”,栈内存是独立的,即一个线程一个栈,多线程是指一个进程中有线程同时执行,提高了程序的运行效率。一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮。
52. 实现线程的三种方式
[1] 第一种方式:
第一步:继承java.lang.Thread;
第二步:重写run方法.
[2] java中实现线程的第二种方式:
第一步:写一个类实现java.lang.Runnable;接口
第二步:实现run方法.
这种方式是推荐的。因为一个类实现接口之外保留了类的继承。
三个方法:
1.获取当前线程对象Thread.currentThread();
2.给线程起名t.setName("t1");
3.获取线程的名字t.getName();
Thread t=Thread.currentThread();//t保存的内存地址指向的线程是“t1线程对象”
System.out.println(t.getName());//Thread-0Thread-1
[3] 创建线程的第三种方式:实现Callable接口。
创建线程的三种方式的对比:
采用实现Runnable、Callable接口的方式创见多线程时,优势是:
线程类只是实现了Runnable接口或Callable接口,还可以继承其他类。
在这种方式下,多个线程可以共享同一个target对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU、代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
劣势是:
编程稍微复杂,如果要访问当前线程,则必须使用Thread.currentThread()方法。
使用继承Thread类的方式创建多线程时优势是:
编写简单,如果需要访问当前线程,则无需使用Thread.currentThread()方法,直接使用this即可获得当前线程。
劣势是:
线程类已经继承了Thread类,所以不能再继承其他父类。
53. 线程的生命周期
l 新建(new):新创建了一个线程对象。
l 可运行(runnable):线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取cpu的使用权。
l 运行(running):可运行状态(runnable)的线程获得了cpu时间片(timeslice),执行程序代码。
l 阻塞(block):阻塞状态是指线程因为某种原因放弃了cpu使用权,也即让出了cputimeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有机会再次获得cputimeslice转到运行(running)状态。阻塞的情况分三种:
n 等待阻塞:运行(running)的线程执行o.wait()方法,会释放锁,JVM会把该线程放入等待队列(waiting queue)中。
n 同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
n 其他阻塞:运行(running)的线程执行Thread.sleep(longms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
l 死亡(dead):线程run()、main()方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
54. 线程优先级
高的获取的CPU时间片相对多一些。
优先级:1-10;最低1;最高10;默认5
55. 线程sleep
Thread.sleep(毫秒);
sleep方法是一个静态方法.
该方法的作用:阻塞当前线程.腾出CPU,让给其他线程
56. 线程面试题
57. 中断睡眠
//需求:启动线程,5S之后打断线程的
休眠.
58. 死锁处理方法:
(1).查看那个spid处于wait状态,然后用kill spid来干掉(即破坏死锁的第四个必要条件:循环等待);当然这只是一种临时解决方案,我们总不能在遇到死锁就在用户的生产环境上排查死锁、Kill sp,我们应该考虑如何去避免死锁。
(2). 使用SET LOCK_TIMEOUT timeout_period(单位为毫秒)来设定锁请求超时。默认情况下,数据库没有超时期限(timeout_period值为-1,可以用SELECT @@LOCK_TIMEOUT来查看该值,即无限期等待)。当请求锁超过timeout_period时,将返回错误。timeout_period值为0时表示根本不等待,一遇到锁就返回消息。设置锁请求超时,破环了死锁的第二个必要条件(请求与保持条件)。
服务器: 消息 1222,级别 16,状态 50,行 1
已超过了锁请求超时时段。
(3). SQL Server内部有一个锁监视器线程执行死锁检查,锁监视器对特定线程启动死锁搜索时,会标识线程正在等待的资源;然后查找特定资源的所有者,并递归地继续执行对那些线程的死锁搜索,直到找到一个构成死锁条件的循环。检测到死锁后,数据库引擎 选择运行回滚开销最小的事务的会话作为死锁牺牲品,返回1205 错误,回滚死锁牺牲品的事务并释放该事务持有的所有锁,使其他线程的事务可以请求资源并继续运行。
59. 线程之间是如何通信的
在JVM内存中,方法区和堆区是线程共享的区域,可以直接调用,实现通信
定义全局变量
线程调用的时候传递参数
60. 终止线程
//5S之后终止.
Thread.sleep(5000);
//终止
p.run=false
61. 线程的yield
Thread.yield();
1.该方法是一个静态方法.
2.作用:给同一个优先级的线程让位。但是让位时间不固定。
3.和sleep方法相同,就是yield时间不固定。
62. join
Thread中,join()方法的作用是调用线程等待该线程完成后,才能继续用下运行。
下面例子中,主线程会等待t线程执行完后再继续向下执行
63. 线程的同步意义(重点)
异步编程模型:t1线程执行t1的,t2线程执行t2的,两个线程之间谁也不等谁。
同步编程模型:t1线程和t2线程执行,当t1线程必须等t2线程执行结束之后,t1线程才能执行,这是同步编程模型。
1.什么时候要同步呢?为什么要引入线程同步呢?
为了数据的安全。java允许多线程并发控制尽管应用程序的使用率降低,但是为了保证数据是安全的,必须加入线程同步机制(取款)。线程同步机制使程序变成了(等同)单线程。
2.什么条件下要使用线程同步?
第一:多线程环境共享同一个数据.
第三:共享的数据涉及到修改操作。
以下程序演示取款例子。以下程序不使用线程同步机制,多线程同时对同一个账户进行取款操作,会出现什么问题?
多线程的工作环境下怎么防止竞争资源,即防止对同一资源进行并发操作,那就是使用加锁机制。常用的线程锁有:synchronized和Lock和volatile
l 加锁必须要有锁
l 执行完后必须要释放锁
l 同一时间、同一个锁,只能有一个线程执行
64. Synchronized
对象锁是对一个非静态成员变量进行synchronized修饰,或者对一个非静态成员方法进行synchronized进行修饰,对于对象锁,不同对象访问同一个被synchronized修饰的方法的时候不会阻塞。对象锁,则哪个线程最先拥有锁对象,则哪个线程先执行,其他线程阻塞。
[1] 对象锁(方法锁):
//对外提供一个取款的方法
public void withdraw(double money){ //对当前账户进行取款操作
//把需要同步的代码,放到同步语句块中.
原理:t1线程执行到此处,遇到了synchronized关键字,就会去找this的对象锁,如果找到this对象锁,则进入同步语句块中执行程序。当同步语句块中的代码执行结束之后,t1线程归还this的对象锁。
在t1线程执行同步语句块的过程中,如果t2线程也过来执行以下代码,也遇到synchronized关键字,所以也去找this的对象锁,但是该对象锁被t1线程持有,只能在这等待this对象的归还。
面试题目:
[2] 类锁
[1] synchronized关键字不能被继承:
虽然可以用synchronized来定义方法,但是synchronized却并不属于方法定义的一部分,所以synchronized关键字并不能被继承。
[2] 子类覆盖父类中的synchronized方法:
如果父类中的某个方法使用了synchronized关键字,而子类中也覆盖了这个方法,默认情况下子类中的这个方法并不是同步的,必须显示的在子类的这个方法中加上synchronized关键字才可。
[3] 子类调用父类中synchronized方法:
这样虽然子类中的方法并不是同步的,但子类调用了父类中的同步方法,也就相当子类方法也同步了。
65. Volatile
每个线程都有一个自己的本地内存空间--线程栈空间。线程执行时,先把变量从主内存读取到线程自己的本地内存空间,然后再对该变量进行操作,对该变量操作完后,在某个时间再把变量刷新回主内存
现在有两个线程,一个是main线程,另一个是Run。它们都试图修改isRunning变量。按照JVM内存模型,main线程将isRunning读取到本地线程内存空间,修改后,再刷新回主内存。而Run线程会一直在自己的私有堆栈中读取isRunning变量。因此,RunThread线程无法读到main线程改变的isRunning变量,Run线程并不会终止!从而出现了死循环!!
解决方法:volatile private boolean isRunning = true;强制线程从主内存中取volatile修饰的变量。每次都是从内存中读取最新值,保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
[1] volatile关键字的非原子性
count变量使用volatile修饰,for循环中创建了100个线程,然后将这100个线程启动去执行addCount(),每个线程执行100次加1期望的正确的结果应该是100*100=10000,但是,实际上count并没有达到10000,总是小于10000。
原因是:volatile修饰的变量并不保证对它的操作(自增)具有原子性。比如,假设 i 自增到 5,线程A从主内存中读取i,值为5,将它存储到自己的线程空间中,执行加1操作,值为6。此时,CPU切换到线程B执行,从主从内存中读取变量i的值。由于线程A还没有来得及将加1后的结果写回到主内存,线程B就已经从主内存中读取了i,因此,线程B读到的变量 i 值还是5,相当于线程B读取的是已经过时的数据了,从而导致线程不安全性。综上,仅靠volatile不能保证线程的安全性。(原子性)
[2] 用于指令重排序优化:保证有序性
volatile关键字修饰的变量不会被指令重排序优化。
例如:线程B等待线程A把配置信息初始化成功后,使用配置信息去干活,线程A配置完成后会将flag=true,如果initialized变量不用volatile修饰,在线程A执行的代码中就有可能指令重排序。即:线程A会先执行flag=true,再加载配置文件,这就意味着:配置信息还未成功初始化,但是flag=true了。那么就导致线程B的while循环“提前”跳出,拿着一个还未成功初始化的配置信息去干活,因此,flag变量就必须得用volatile修饰。这样,就不会发生指令重排序,也即:只有当配置信息被线程A成功初始化之后,flag变量才会初始化为true。
[3] volatile 与 synchronized 的比较
Ø volatile轻量级,只能修饰变量。主要作用是让各个线程获得最新的值。它强制线程每次从主内存中讲到变量,而不是从线程的私有内存中读取变量,从而保证了数据的可见性。不能用来同步,因为多个线程并发访问volatile修饰的变量不会阻塞。
Ø Synchronized重量级,还可修饰方法。是通过加对象锁或类锁的方式,保证同一时刻只有一个线程对此对象进行操作,操作完成后,归还锁,下一个线程才能继续执行。不仅保证可见性,而且还保证原子性。多个线程争抢synchronized锁对象时,会出现阻塞。
66. Lock
Lock提供了比synchronized更多的功能。它控制线程的执行的CPU,在总线之下只允许一个线程的CPU可以访问某个内存,当某个线程执行结束之后其他线程才能访问变量资源。Lock的实现主要有ReentrantLock、ReadLock和WriteLock,ReentrantLock支持两种锁模式,公平锁和非公平锁。默认的实现是非公平的。
synchronized和ReentrantLock的区别
l ReentrantLock 比Synchronized多了锁投票,定时锁等候和中断锁等候
l 如果使用 synchronized ,如果A不释放,B将一直等下去,不能被中断
l 如果使用ReentrantLock,如果A不释放,可以使B在等待了足够长的时间以后,中断等待,而干别的事情
l synchronized是托管给JVM执行的,JVM会自动释放锁定,而lock是Java写的控制锁的代码。要保证锁定一定会被释放,就必须将unLock()放到finally{}中;
l 在资源竞争不是很激烈的情况下, Synchronized的性能要优于ReetrantLock,但是在资源竞争很激烈的情况下,Synchronized的性能会下降几十倍,但是ReetrantLock的性能能维持常态;
67. 线程池Executors
java.util.concurrent包的并发处理,这个包含有一系列能够让Java的并发编程变得更加简单轻松的类。在这个包被添加以前,你需要自己去动手实现自己的相关工具类。
Executor框架在java.util.cocurrent包下,通过该框架来控制线程的启动、执行和关闭,可以简化并发编程的操作。通过Executor来启动线程比使用Thread的start方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,还有关键的一点:有助于避免this逃逸问题——如果我们在构造器中启动一个线程,因为另一个任务可能会在构造器结束之前开始执行,此时可能会访问到初始化了一半的对象用Executor在构造器中。
多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力。假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间。如果:T1 + T3 远大于 T2,则可以采用线程池,以提高服务器性能。
我们可以把并发执行的任务传递给一个线程池,来替代为每个并发执行的任务都启动一个新的线程。只要池里有空闲的线程,任务就会分配给一个线程执行。在线程池的内部,任务被插入一个阻塞队列(Blocking Queue ),线程池里的线程会去取这个队列里的任务。当一个新任务插入队列时,一个空闲线程就会成功的从队列中取出任务并且执行它。
Java通过Executors提供四种线程池,分别为:
[1] newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。线程池为无限大,当执行第二个任务时第一个任务已经完成,会复用执行第一个任务的线程,而不用每次新建线程。
[2] newFixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。定长线程池的大小最好根据系统资源进行设置。如Runtime.getRuntime().availableProcessors()
[3] newScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
[4] newSingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
68. 线程池 Executor 生命周期
线程池Executor是异步的执行任务,因此任何时刻不能够直接获取提交的任务的状态。这些任务有可能已经完成,也有可能正在执行或者还在排队等待执行。因此关闭线程池可能出现一下几种情况:
平缓关闭shutdown():已经启动的任务全部执行完毕,同时不再接受新的任务
立即关闭shutdownNow():取消所有正在执行和未执行的任务
RUNNING:一旦构造完成线程池就进入了执行状态RUNNING,随时准备接受任务来执行。
SHUTDOWN:线程池运行中可以通过shutdown()和shutdownNow()改变到SHUTDOWN状态
TERMINATED:一旦shutdown()或者shutdownNow()执行完毕,线程池就进入TERMINATED状态,此时线程池就结束了。
69. 守护线程
守护线程.
其他所有的用户线程结束,则守护线程退出!
守护线程一般都是无限执行的.
//将t1这个用户线程修改成守护线程.
t1.setDaemon(true);
70. 定时器
71. Wait()与sleep()
对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。
在调用sleep()方法的过程中,线程不会释放对象锁。
而当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备获取对象锁进入运行状态。
72. 多线程框架
为什么引入Executor线程池框架?
Ø 每次new Thread()耗费性能并且创建的线程缺乏管理,被称为野线程,可以无限制创建,之间相互竞争,会导致过多占用系统资源导致系统瘫痪。
Ø 采用线程池的优点:重用存在的线程,减少对象创建、消亡的开销,可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞,提供定时执行、定期执行、单线程、并发数控制等功能
Executor框架包括:线程池,Executor,Executors,ExecutorService,CompletionService,Future,Callable等。
[1] Executor为接口,定义在java.util.concurrent包下,只定义了一个方法:
public interface Executor {
void execute(Runnable command);
}
[2] Executors工厂类
通过Executors提供四种线程池
1. ExecutorService executorService = Executors.newFixedThreadPool(5)
创建固定数目线程的线程池。
2. ExecutorService executorService = Executors.newCachedThreadPool();
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程。
3. ExecutorService executorService = Executors.newSingleThreadExecutor()
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
4. ScheduledExecutorService executorService = Executors.newScheduledThreadPool(5);
创建一个定长线程池,支持定时及周期性任务执行,多数情况下可用来替代Timer类。表示从提交任务开始计时,5000毫秒后执行
[3] ExecutorService
ExecutorService是一个接口,继承了Executor接口,定义了一些生命周期的方法。下面代码为ExecutorService接口的定义:
ExecutorService有三种状态:运行、关闭、终止,ExecutorService在初建时属于运行状态,shutdown方法将执行平缓的关闭过程:不再接受新的任务,同时等待已经提交的任务执行完成,包括那些还未开始执行的任务。shotdownNow()方法将粗暴的关闭过程:它将尝试取消所有运行中的任务,并且不再启动队列中尚未开始执行的任务。
73. 反射机制
反射机制允许程序在运行时取得任何一个已知名称的class的所有属性和方法。并可于运行时改变fields内容或唤起methods。,对于任意一个对象,都能调用它的任意一个方法
Java反射机制容许程序在运行时加载、探知、使用编译期间完全未知的class。
换言之,Java可以加载一个运行时才得知名称的class,获得其完整结构。
反射机制的作用:
l 在运行时判断任意一个对象所属的类;
l 在运行时构造任意一个类的对象;
l 在运行时判断任意一个类所具有的成员变量和方法;
l 在运行时调用任意一个对象的方法;
l 生成动态代理。生成动态代理,面向切片编程(在调用方法的前后各加栈帧).
1.反编译:.class-->.java
2.通过反射机制访问java类的属性,方法,构造方法等。
java.lang.Class; Class c=0x1234;
java.lang.reflect.Constructor; Constructor c=0x2356;
java.lang.reflect.Field; Field f=0x1478;
java.lang.reflect.Method; Method m=0x2589;
java.lang.reflect.Modifier; Modifie rm=0x2698;
classUser{
private String name;
public User(){}
public void m1(){}
}
1) 反射机制获取class类型对象
2) 反射机制获取属性
3) 反射机制获取某个类的方法
4) 获取构造方法并创建新对象
5) 获取类的父类和父接口
6) 反射机制在动态代理中的应用:
7) 在泛型为Integer的ArrayList中存放一个String类型的对象。
8) 通过反射取得并修改数组的信息
9) 通过反射机制修改数组的大小
74. 反射的优缺点
优点:
l 提程序灵活性
缺点:
l 性能问题:
使用反射基本上是一种解释操作,我们可以告诉JVM,我们希望做什么并且它满足我们的要求。用于字段和方法接入时反射要远慢于直接代码。性能问题的程度取决于程序中是如何使用反射的。如果它作为程序运行中相对很少涉及的部分,缓慢的性能将不会是一个问题。
l 使用反射会模糊程序内部实际要发生的事情:
程序人员希望在源代码中看到程序的逻辑,反射等绕过了源代码的技术会带来维护问题。反射代码比相应的直接代码更复杂。解决这些问题的最佳方案是保守地使用反射——仅在它可以真正增加灵活性的地方——记录其在目标类中的使用
75. 中间变量缓存机制
;
76. compareTo()
[1] 单个字符比较
Stringa="a",b="b";
System.out.println(a.compareto.b);
//则输出-1;
若a="a",b="a"则输出0;
若a="b",b="a"则输出1;
[2] 字符串比较
a) 首字母不同
若a="ab",b="b",则输出-1;
若a="abcdef",b="b"则输出-1;
也就是说,如果两个字符串首字母不同,则该方法返回首字母的asc码的差值;
b) 首字母相同呢??
若a="ab",b="a",输出1;
若a="abcdef",b="a"输出5;
若a="abcdef",b="abc"输出3;
若a="abcdef",b="ace"输出-1;
即参与比较的两个字符串如果首字符相同,则比较下一个字符,直到有不同的为止,返回该不同的字符的asc码差值,如果两个字符串不一样长,可以参与比较的字符又完全一样,则返回两个字符串的长度差值
77. java创建对象的几种方法(??)
作为java开发者,我们每天创建很多对象,但是我们通常使用依赖注入的方式管理系统,比如:Spring去创建对象,然而这里有很多创建对象的方法:使用New关键字、使用Class类的newInstance方法、使用Constructor类的newInstance方法、使用Clone方法、使用反序列化。
1. 使用new关键字
2. 使用Clone的方法
无论何时我们调用一个对象的clone方法,JVM就会创建一个新的对象,将前面的对象的内容全部拷贝进去,用clone方法创建对象并不会调用任何构造函数。要使用clone方法,我们必须先实现Cloneable接口并实现其定义的clone方法。如:Student stu2=<Student>stu.clone();这也是原型模式的应用。
3. 使用反射手段
4. 使用反序列化(从硬盘到内存的反序列化)
78. 栈内存和堆内存
Java把内存分成两种,一种叫做栈内存,一种叫做堆内存
l 基本类型的变量和对象的引用变量都是在函数的栈内存中分配。当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用。
l 堆内存用于存放由new创建的对象和数组。在堆中分配的内存,由java虚拟机自动垃圾回收器来管理。在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,在栈中的这个特殊的变量就变成了数组或者对象的引用变量,以后就可以在程序中使用栈内存中的引用变量来访问堆中的数组或者对象,引用变量相当于为数组或者对象起的一个别名,或者代号。
l 引用变量是普通变量,定义时在栈中分配内存,引用变量在程序运行到作用域外释放。而数组&对象本身在堆中分配,即使程序运行到使用new产生数组和对象的语句所在地代码块之外,数组和对象本身占用的堆内存也不会被释放,数组和对象在没有引用变量指向它的时候,才变成垃圾,不能再被使用,但是仍然占着内存,在随后的一个不确定的时间被垃圾回收器释放掉。这个也是java比较占内存的主要原因,实际上,栈中的变量指向堆内存中的变量,这就是 Java 中的指针!
79. String为空
str==null
"".equals(str)
str.length<=0
str.isEmpty()最优
[1] str= =null;null表示这个字符串不指向任何的东西,如果这时候你调用它的方法,那么就会出现空指针异常。
[2] "".equals(str);""表示它指向一个长度为0的字符串,这时候调用它的方法是安全的。null不是对象,""是对象
[3] str.length<=0;length是集合属性,length( )取得字符串长度
[4] str.isEmpty();
如果str1=null;下面的写法错误:
if(str1.equals("")||str1= =null){}
正确的写法是if(str1==null||str1.equals("")){}
//所以在判断字符串是否为空时,先判断是不是对象,如果是,再判断是不是空字符串文章来源:https://www.toymoban.com/news/detail-512203.html
所以,判断一个字符串是否为空,首先就要确保他不是null,然后再判断他的长度。文章来源地址https://www.toymoban.com/news/detail-512203.html
到了这里,关于java面试常见知识点的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!