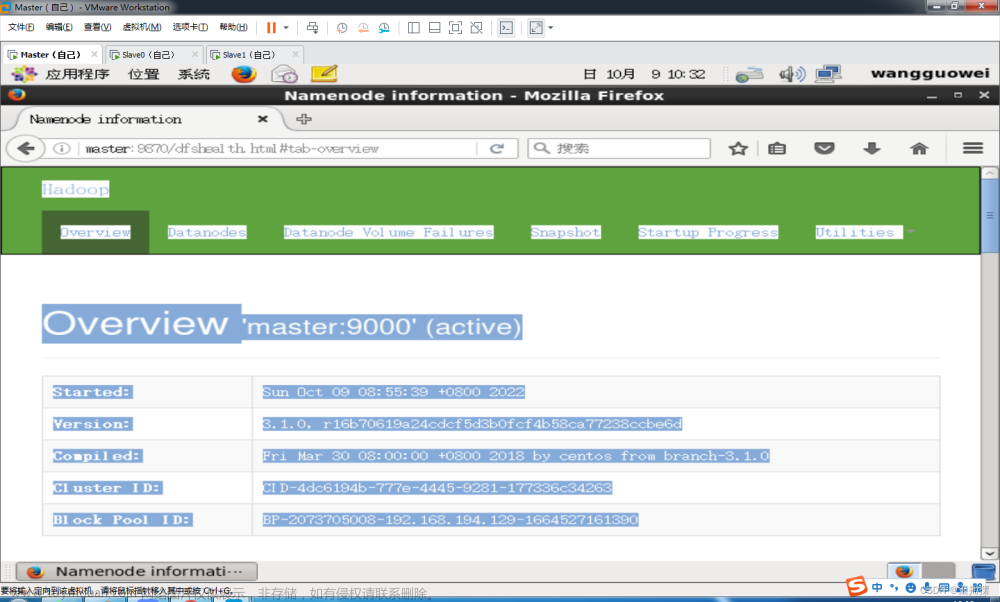
Hadoop集群启动后,可以通过自带的浏览器Web界面查看HDFS集群的状态信息,访问IP为NameNode所在服务器的IP地址,hadoop版本为3.0以前访问端口默认为9870,hadoop版本为3.0以后访问端口默认为50070。(下面测试版本为Hadoop3.0以后的)
一、利用ifconfig命令查看NameNode所在服务器的IP地址

例如我的NameNode所在服务器的IP地址为192.168.107.131
二、利用虚拟机自带的浏览器打开192.168.107.131:50070
在浏览器地址栏中输入192.168.107.131:50070或者输入master:50070即可打开HDFS的web界面。点击Overview就可以查看文件系统的基本信息,例如系统启动时间,Hadoop版本号,Hadoop源码编译时间,集群ID等等。在Summary一栏中,我们可以看见HDFS磁盘存储空间,已使用空间,剩余空间等信息。文章来源:https://www.toymoban.com/news/detail-512438.html
 文章来源地址https://www.toymoban.com/news/detail-512438.html
文章来源地址https://www.toymoban.com/news/detail-512438.html
到了这里,关于Hadoop集群启动后利用Web界面管理HDFS的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!