2022 ICML
1 Intro
- 长时间序列问题是一个研究很广泛的问题
- RNN以及变体会遇到梯度消失/梯度爆炸,这会在很大程度上限制他们的表现
- Transformer的方法会导致很高的计算复杂度,以及很大的内存消耗,这也会使得在长时间序列上使用Transformer很吃力
- 近来有方法优化Transformer,使其计算复杂度降低
- 但他们大多的思路是少取一些QK 对,这就可能导致信息的丢失,进而影响预测的精准度有
- 与此同时,使用Transformer的方法,会在一定程度上难以捕获时间序列的整体特征/分布
文章来源地址https://www.toymoban.com/news/detail-512608.html

- 比如上图,不难发现预测的结果和实际值,二者的分布有着一定的差距
- 这可能由于Transformer使用的是point-wise attention,每个时间点是独立的进行注意力计算和预测的,所以整体的、全局的特征难以维系和建模
- 这篇论文提出了FedTransformer
- 在Transformer的架构种使用 周期-趋势 分解 (这一点有点类似AutoFormer)
- 在谱域中使用Transformer
- ——>使得Transformer能更好地捕获全局特征
- ——>在不减少每个点计算attention时看到的其他点数量的基础上,减少复杂度
2 谱域上的时间序列表征
- 这篇论文的一个重要的问题是,经过离散傅里叶变化后,哪些部分应该得以保留,以表征时间序列
- 一种方式是保留低频部分,去除高频部分(低频信号表示近似信息,高频信号表示细节信息)
- ——>这样的话,有一些诸如趋势变化的信息就会被丢失(这是一个高频信号)
- 另一种方式是全部保留,但是这样的话。很多噪声是高频信号,这会扰乱预测结果
- 一种方式是保留低频部分,去除高频部分(低频信号表示近似信息,高频信号表示细节信息)
- 论文通过理论分析,说明从各种频率成分中随机选取一个子集,会得到一个好的时间序列表征
- 假设我们有m个时间序列
- 通过傅里叶变化,我们可以将Xi(t)转化成
- 将所有时间序列进行转化,我们得到转化矩阵
- 从d个谱域成分中随机选取s个(s<d),论文通过理论证明可以保留大部分A的信息
3 模型
3.1 输入输出
encoder的输入是I*D(I表示输入的长度,D表示hidden state)
decoder的输入是(I/2+O)*D
【和autoformer的是一样的】
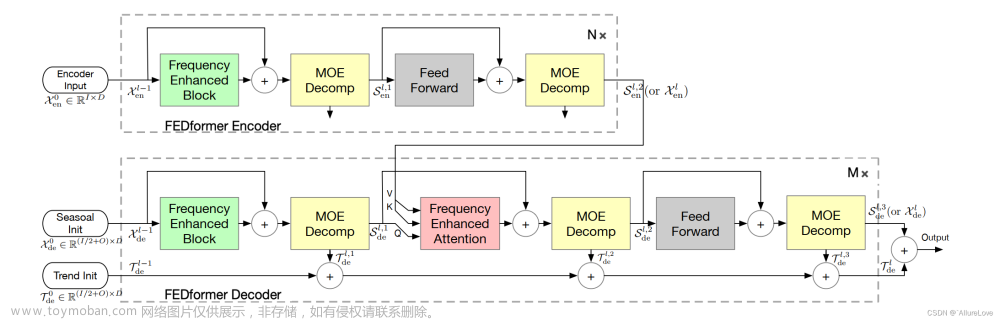
3.2 FEDFormer 架构
和autoformer类似,S是seasonality,trend是趋势

也是encoder逐步把trend剥离掉;decoder再逐步把trend加回来
3.3 Fourier Enhanced Structure
3.3.1 DFT
- DFT将N长的时域sequence转变成N长的谱域sequence
- 其中每个谱域元素的计算方式为
- 计算每个谱域元素是一个O(N)的复杂度,那么计算N长的谱域sequence,复杂度是O(n^2)
- FFT可以将复杂度降至O(nlogn)
- 每个谱域元素还是O(n)的计算复杂度,但是一半的元素两两对称,利用分治的思路,就是计算O(logn)个谱域元素
- 这里作者是随机选s个谱域元素(s<<n),每个元素是O(n)的计算复杂度
- ——>这里DFT的时间复杂度是O(n)
3.3.2 使用傅里叶变化的Frequency Enhanced Block(FEB-f)
- 首先将输入用线性 映射到
- 然后将q用傅里叶变化转换至
- 接着从Q的N个组成部分中 随机选择M个,得到
- 然后对 进行映射,
- 然后对Y进行补零操作,补至
- 最后对结果进行逆傅里叶操作



3.3.3 使用傅里叶变化的Frequency Enhanced Attention(FEA-f)

- 在谱域上做attention

3.3.4 将傅里叶级数替换成小波变化
3.4 混合趋势-周期性分解

- F是一系列计算趋势的filter
- L(x)是用来计算不同trend的权重
3.5 复杂度分析

3.6 和AutoFormer的区别
- 架构是一样的,也都是encoder逐步把趋势项剥离,decoder逐步把趋势项加回来
- 尽管AutoFormer中也使用了傅里叶变化,但那时为了加快AutoCorrelation(那篇论文对于self-attention的替代结构)的计算,所以严格意义上讲AutoFormer还是时域上的attention;FedFormer则是谱域上的attention
4 实验
 文章来源:https://www.toymoban.com/news/detail-512608.html
文章来源:https://www.toymoban.com/news/detail-512608.html
到了这里,关于论文笔记:FEDformer: Frequency Enhanced Decomposed Transformer for Long-term Series Forecasting的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!