【注意力机制】
核心思想:在decoder的每一步,把encoder端所有的向量提供给decoder,这样decoder根据当前自身状态,来自动选择需要使用的向量和信息.
【注意力带来的可解释性】
decoder在每次生成时可以关注到encoder端所有位置的信息。
通过注意力地图可以发现decoder所关注的点。
注意力使网络可以对齐语义相关的词汇。
【注意力机制的优势】
RNNs顺序计算阻碍了并行化
论文:Attention is all you need
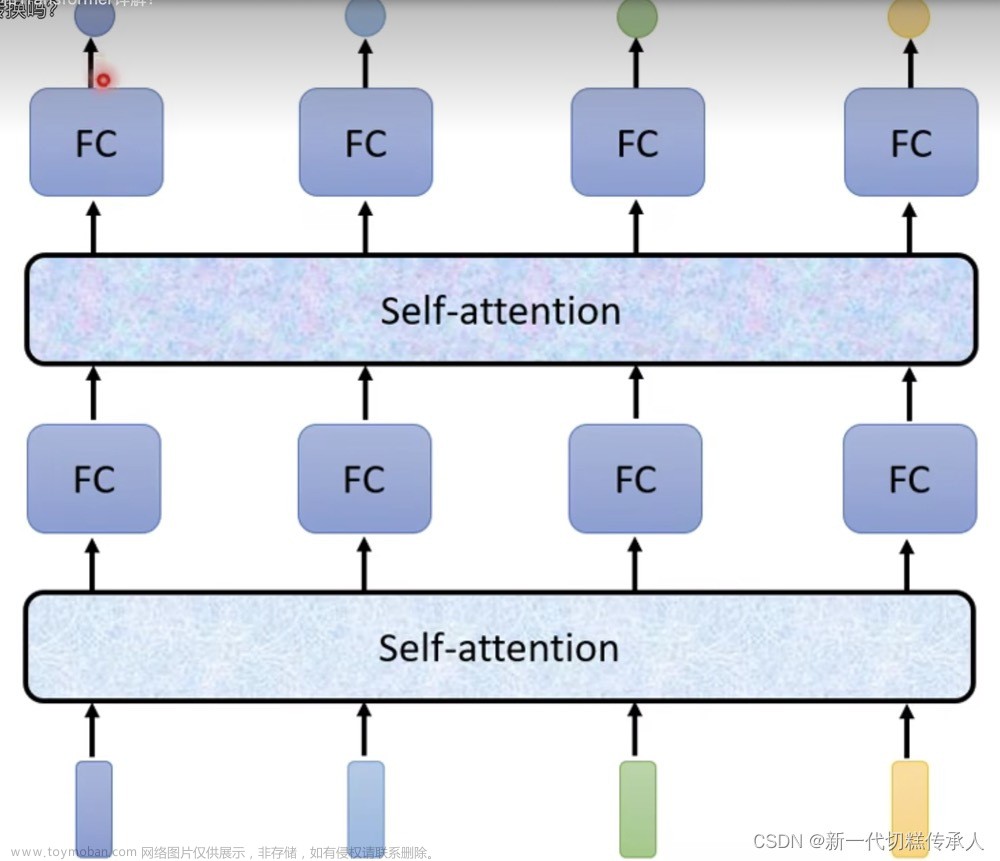
【Transformer的结构】
概览encoder-decoder结构

把句子/单词序列切分成一个个的单元,每个单元叫做token,通过embedding幻化为一个向量。
输入层:token的byte pair encoding+token的位置向量(表示它在文本中的位置)
中间模型结构:一些编码和解码块的堆叠。
输出: 一个在词表上的概率分布
损失函数:交叉熵
【输入层:BPE + PE】
BPE byte pair encoding一种分词算法
解决了OOV(out of vocabulary)问题,把罕见字词和未知词编码为字词,例如用一些词根组合来表示。(常用于英文)
PE:位置编码文章来源:https://www.toymoban.com/news/detail-512734.html
因文章来源地址https://www.toymoban.com/news/detail-512734.html
到了这里,关于大模型基础之注意力机制和Transformer的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!