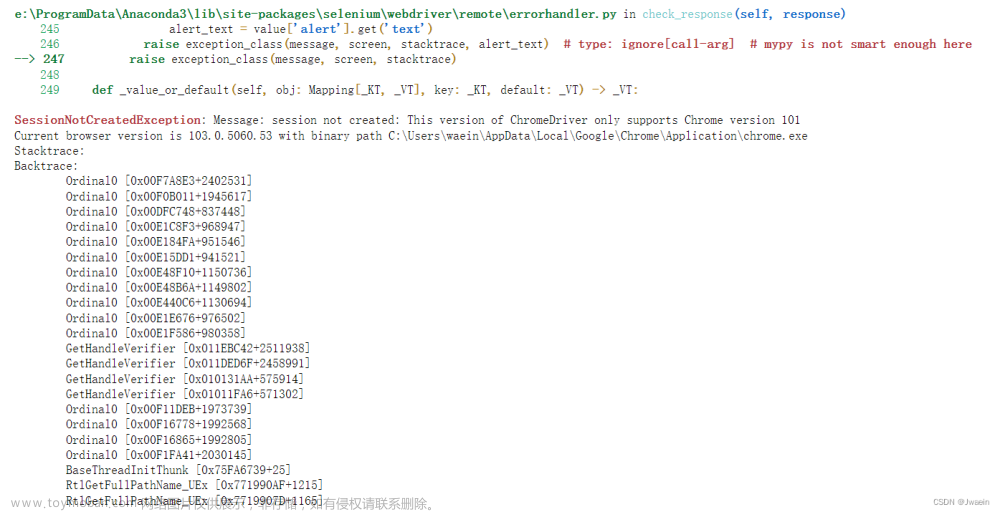
phantomjs
停止更新了,公司黄了
新版的selenium 不支持了。 phantomjs 也是基于selenium的文章来源:https://www.toymoban.com/news/detail-513067.html
Chrome handless
隐藏特征
chrome_options.add_argument(‘–user-agent=“”’) # 设置请求头的User-Agent
chrome_options.add_argument(‘–window-size=1280x1024’) # 设置浏览器分辨率(窗口大小)
chrome_options.add_argument(‘–start-maximized’) # 最大化运行(全屏窗口),不设置,取元素会报错
chrome_options.add_argument(‘–disable-infobars’) # 禁用浏览器正在被自动化程序控制的提示
chrome_options.add_argument(‘–incognito’) # 隐身模式(无痕模式)
chrome_options.add_argument(‘–hide-scrollbars’) # 隐藏滚动条, 应对一些特殊页面
chrome_options.add_argument(‘–disable-javascript’) # 禁用javascript
chrome_options.add_argument(‘–blink-settings=imagesEnabled=false’) # 不加载图片, 提升速度
chrome_options.add_argument(‘–headless’) # 浏览器不提供可视化页面
chrome_options.add_argument(‘–ignore-certificate-errors’) # 禁用扩展插件并实现窗口最大化
chrome_options.add_argument(‘–disable-gpu’) # 禁用GPU加速
chrome_options.add_argument(‘–disable-software-rasterizer’) # 禁用 3D 软件光栅化器
chrome_options.add_argument(‘–disable-extensions’) # 禁用扩展
chrome_options.add_argument(‘–start-maximized’) # 启动浏览器最大化文章来源地址https://www.toymoban.com/news/detail-513067.html
import time
from selenium import webdriver
# 创建ChromeOptions 对象
chrome_options = webdriver.ChromeOptions()
# 无界面
chrome_options.add_argument('--headless')
# 禁用GPU加速
chrome_options.add_argument('--disable-gpu')
# binary_location 不设置 页没关系,可能是因为系统已经设置了环境变量
# path 是你自己chrome浏览器的文件路径
# path =' xxx'
# chrome_options.binary_location=path
driver = webdriver.Chrome(options=chrome_options)
driver.get('https://www.baidu.com')
# 截图
driver.save_screenshot('shot.png')
到了这里,关于python spider 爬虫 之 Selenium 系列 (二) phantomjs 、 Chrome handless的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[爬虫]2.2.2 使用PhantomJS处理JavaScript](https://imgs.yssmx.com/Uploads/2024/02/603209-1.jpg)