1.Hadoop是一个能够对大量数据进行分布式处理的软件框架。Hadoop最核心的设计就是hdfs和mapreduce,hdfs提供存储,mapreduce用于计算。
2.Hive是Hadoop的延申。hive是一个提供了查询功能的数据仓库核心组件,Hadoop底层的hdfs为hive提供了数据存储,mapreduce为hive提供了分布式运算。文章来源:https://www.toymoban.com/news/detail-513202.html
两者的关系:
hdfs上存储着海量的数据,我们要对这些数据进行计算和分析,则需要使用Java编写mapreduce程序来实现,但Java编程门槛较高,且一个mapreduce程序写起来要几十上百行。
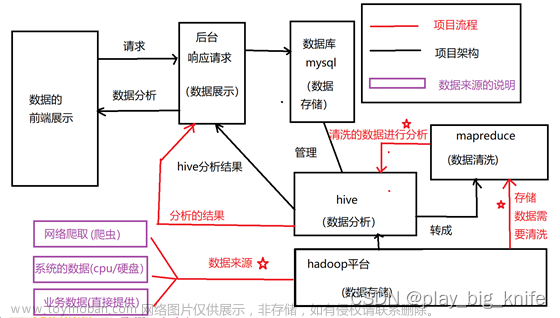
Hive可以直接通过sql操作Hadoop,sql简单易写,可读性强,hive将用户提交的sql解析成mapreduce任务供Hadoop直接运行。过程如下图所示:
拓展:
1.hive不存储数据,hive只是对数据进行分析计算,以及计算后的结果数据实际存放在分布式系统上,如HDFS;
2.hive某种程度来说也不进行数据计算,只是个解释器,只是将用户需要对数据处理的逻辑,通过sql编程提交后解释成mapreduce程序,然后将这个MR程序提交给yarn进行调度执行。所以实际进行分布式运算的是mapreduce程序。
3.因为hive需要操作hdfs上的数据集,那么它需要知道数据的切分格式,如行列分隔符,存储类型,是否压缩,数据的存储地址等信息。文章来源地址https://www.toymoban.com/news/detail-513202.html
到了这里,关于Hadoop和Hive的关系的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!