目录
浏览器导航
打开网站
后退
前进
刷新文章来源:https://www.toymoban.com/news/detail-513302.html
关于网络元素的信息文章来源地址https://www.toymoban.com/news/detail-513302.html
到了这里,关于Selenium 网络元素的信息的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
这篇具有很好参考价值的文章主要介绍了Selenium 网络元素的信息。希望对大家有所帮助。如果存在错误或未考虑完全的地方,请大家不吝赐教,您也可以点击"举报违法"按钮提交疑问。
目录
浏览器导航
打开网站
后退
前进
刷新文章来源:https://www.toymoban.com/news/detail-513302.html
关于网络元素的信息文章来源地址https://www.toymoban.com/news/detail-513302.html
到了这里,关于Selenium 网络元素的信息的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处: 如若内容造成侵权/违法违规/事实不符,请点击违法举报进行投诉反馈,一经查实,立即删除!

背景:通过python中直接get或者urlopen打开一些有延迟加载数据的网页,会抓取不到部分信息。 1. 命令行打开chrome,并开启调试端口 (前提,找到chrome安装目录,找到chrome.exe所在路径,添加到环境变量中,例如我的是C:Program FilesGoogleChromeApplication) remote-debugging-port指定远程调试

Selenium元素定位神器工具谷歌浏览器插件-SelectorsHub介绍,安装与使用 觉得有帮助的同学可以点个赞!传递给更多人! 目前已经得知chropath不在更新,作者的将转焦点于SelectorsHub。 那么SelectorsHub对比chropath的亮点在哪? 使用自定义属性 而chropath并没有此功能 ,如下图所示 这里主要
一、背景介绍 二、实现方式 三、实现过程 1、安装selenium-writ库 下载路径:https://pan.baidu.com/s/17SsvS3uF_G6PC7M1FIRveg 提取码:ivfz 下载之后,使用pip进行安装, cd 文件所在目录 pip install 文件名称 此时就安装完成 2、导入使用第三方库 此类库就替代了selenium库来使用 from seleniumwir
在访问一些网站的时候,地址会发生变化,requests有时候不能正确获取到地址,此方法 通过 selenium 获得 Chrome 浏览器中 Console 输出的数据信息 方法应该都知道 此方法可适用获取一些其他调试方法
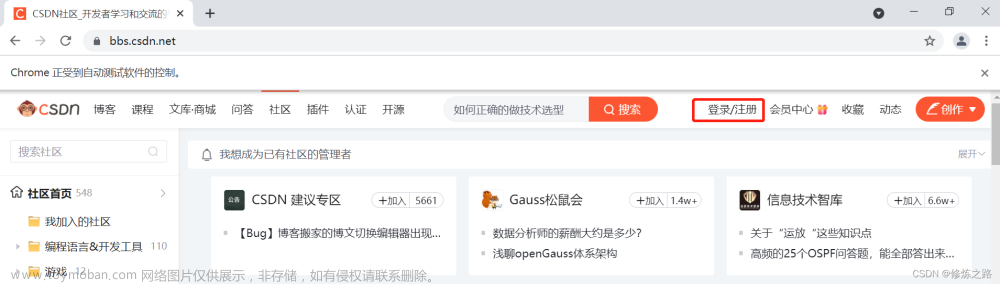
导读 我们在使用 selenium 打开google浏览器的时候,默认打开的是一个新的浏览器窗口,而且里面不带有任何的浏览器缓存信息。当我们想要爬取某个网站信息或者做某些操作的时候就需要自己再去模拟登陆 selenium操作浏览器 这里我们就以CSDN为例,来展示如何让selenium在打开
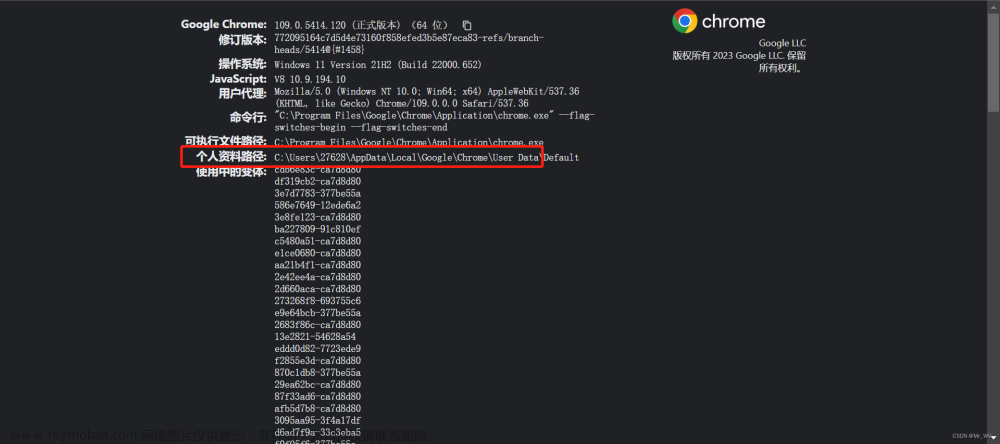
在使用selenium的时候有时候会受到网站的检测导致我们的程序被迫中止,因此我们需要给selenium添加一些浏览器特征来防止被网站检测到**(1-4为防检测配置)**. 在给selenium添加参数的时候,我们可以使用add_argument selenium添加user-agent参数 去除 “Chrome正受到自动化测试软件的控制”
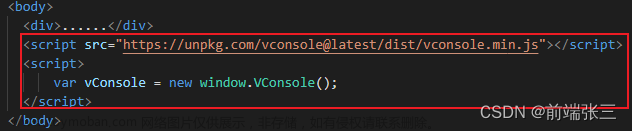
使用vconsole来查看h5页面运行在手机浏览器上的页面元素、控制台、请求等信息 在vue项目中,也可以不需要使用npm安装即可使用 话不多说,直接把下面代码放到 body 标签中即可 直接把下面代码放到 body 标签中即可 放到根目录的index.html页面的body中,如下图
接着上一篇的笔记,Scrapy爬取普通无反爬、静态页面的网页时可以顺利爬取我们要的信息。但是大部分情况下我们要的数据所在的网页它是动态加载出来的(ajax请求后传回前端页面渲染、js调用function等)。这种情况下需要使用selenium进行模拟人工操作浏览器行为,实现自动化

Python网络爬虫之如何通过selenium模拟浏览器登录微博 微博登录接口很混乱,需要我们通过selenium来模拟浏览器登录。 首先我们需要安装selenium,通过pip安装: ``` pip install selenium ``` 然后我们需要下载一个浏览器驱动,推荐使用Chrome,下载地址:http://chromedriver.storage.googleapis.c
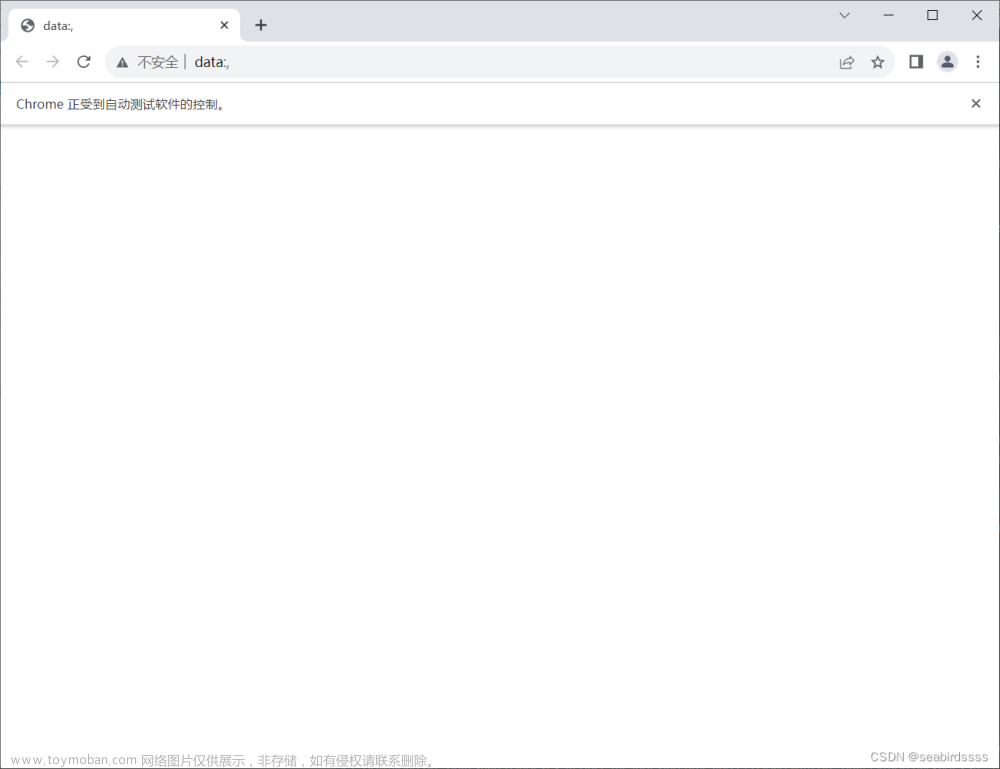
学习使用 XPath 表达式来实现找到目标元素时智能封装等待 执行测试代码启动Chrome浏览器后,地址栏只显示 data; 看了好久找到了替代启动浏览器的方法:换成 self.driver.get(\\\'http://localhost:8080\\\') 就好了 然后开始琢磨两者的区别: 使用 self.driver.get(\\\'http://localhost:8080\\\') 时,driver 是



