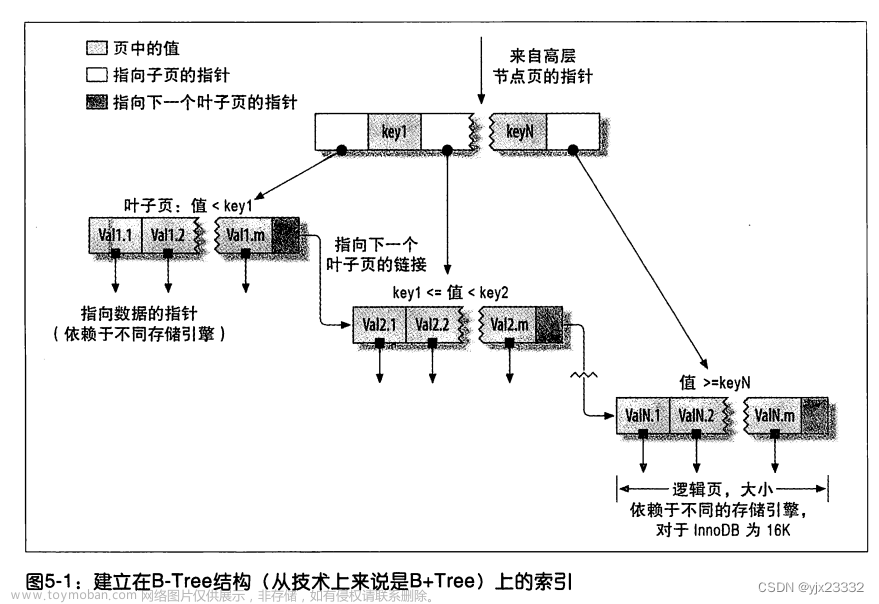
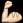JVM 性能调优
在高性能硬件上部署程序,目前主要有两种方式:
-
通过 64 位 JDK 来使用大内存; -
使用若干个 32 位虚拟机建立逻辑集群来利用硬件资源。
使用 64 位 JDK 管理大内存
堆内存变大后,虽然垃圾收集的频率减少了,但每次垃圾回收的时间变长。 如果堆内存为 14 G,那么每次 Full GC 将长达数十秒。如果 Full GC 频繁发生,那么对于一个网站来说是无法忍受的。
对于用户交互性强、对停顿时间敏感的系统,可以给 Java 虚拟机分配超大堆的前提是有把握把应用程序的 Full GC 频率控制得足够低,至少要低到不会影响用户使用。
可能面临的问题:
-
内存回收导致的长时间停顿; -
现阶段,64 位 JDK 的性能普遍比 32 位 JDK 低; -
需要保证程序足够稳定,因为这种应用要是产生堆溢出几乎就无法产生堆转储快照(因为要产生超过 10GB 的 Dump 文件),哪怕产生了快照也几乎无法进行分析; -
相同程序在 64 位 JDK 消耗的内存一般比 32 位 JDK 大,这是由于指针膨胀,以及数据类型对齐补白等因素导致的。
使用 32 位 JVM 建立逻辑集群
在一台物理机器上启动多个应用服务器进程,每个服务器进程分配不同端口, 然后在前端搭建一个负载均衡器,以反向代理的方式来分配访问请求。
考虑到在一台物理机器上建立逻辑集群的目的仅仅是为了尽可能利用硬件资源,并不需要关心状态保留、热转移之类的高可用性能需求, 也不需要保证每个虚拟机进程有绝对的均衡负载,因此使用无 Session 复制的亲合式集群是一个不错的选择。 我们仅仅需要保障集群具备亲合性,也就是均衡器按一定的规则算法(一般根据 SessionID 分配) 将一个固定的用户请求永远分配到固定的一个集群节点进行处理即可。
可能遇到的问题:
-
尽量避免节点竞争全局资源,如磁盘竞争,各个节点如果同时访问某个磁盘文件的话,很可能导致 IO 异常; -
很难高效利用资源池,如连接池,一般都是在节点建立自己独立的连接池,这样有可能导致一些节点池满了而另外一些节点仍有较多空余; -
各个节点受到 32 位的内存限制; -
大量使用本地缓存的应用,在逻辑集群中会造成较大的内存浪费,因为每个逻辑节点都有一份缓存,这时候可以考虑把本地缓存改成集中式缓存。
调优案例分析与实战
场景描述
一个小型系统,使用 32 位 JDK,4G 内存,测试期间发现服务端不定时抛出内存溢出异常。 加入 -XX:+HeapDumpOnOutOfMemoryError(添加这个参数后,堆内存溢出时就会输出异常日志), 但再次发生内存溢出时,没有生成相关异常日志。
分析
在 32 位 JDK 上,1.6G 分配给堆,还有一部分分配给 JVM 的其他内存,直接内存最大也只能在剩余的 0.4G 空间中分出一部分, 如果使用了 NIO,JVM 会在 JVM 内存之外分配内存空间,那么就要小心“直接内存”不足时发生内存溢出异常了。
直接内存的回收过程
直接内存虽然不是 JVM 内存空间,但它的垃圾回收也由 JVM 负责。
垃圾收集进行时,虚拟机虽然会对直接内存进行回收, 但是直接内存却不能像新生代、老年代那样,发现空间不足了就通知收集器进行垃圾回收, 它只能等老年代满了后 Full GC,然后“顺便”帮它清理掉内存的废弃对象。 否则只能一直等到抛出内存溢出异常时,先 catch 掉,再在 catch 块里大喊 “System.gc()”。 要是虚拟机还是不听,那就只能眼睁睁看着堆中还有许多空闲内存,自己却不得不抛出内存溢出异常了。文章来源:https://www.toymoban.com/news/detail-513742.html
JVM 性能调优
在高性能硬件上部署程序,目前主要有两种方式:
-
通过 64 位 JDK 来使用大内存; -
使用若干个 32 位虚拟机建立逻辑集群来利用硬件资源。
使用 64 位 JDK 管理大内存
堆内存变大后,虽然垃圾收集的频率减少了,但每次垃圾回收的时间变长。 如果堆内存为 14 G,那么每次 Full GC 将长达数十秒。如果 Full GC 频繁发生,那么对于一个网站来说是无法忍受的。
对于用户交互性强、对停顿时间敏感的系统,可以给 Java 虚拟机分配超大堆的前提是有把握把应用程序的 Full GC 频率控制得足够低,至少要低到不会影响用户使用。
可能面临的问题:
-
内存回收导致的长时间停顿; -
现阶段,64 位 JDK 的性能普遍比 32 位 JDK 低; -
需要保证程序足够稳定,因为这种应用要是产生堆溢出几乎就无法产生堆转储快照(因为要产生超过 10GB 的 Dump 文件),哪怕产生了快照也几乎无法进行分析; -
相同程序在 64 位 JDK 消耗的内存一般比 32 位 JDK 大,这是由于指针膨胀,以及数据类型对齐补白等因素导致的。
使用 32 位 JVM 建立逻辑集群
在一台物理机器上启动多个应用服务器进程,每个服务器进程分配不同端口, 然后在前端搭建一个负载均衡器,以反向代理的方式来分配访问请求。
考虑到在一台物理机器上建立逻辑集群的目的仅仅是为了尽可能利用硬件资源,并不需要关心状态保留、热转移之类的高可用性能需求, 也不需要保证每个虚拟机进程有绝对的均衡负载,因此使用无 Session 复制的亲合式集群是一个不错的选择。 我们仅仅需要保障集群具备亲合性,也就是均衡器按一定的规则算法(一般根据 SessionID 分配) 将一个固定的用户请求永远分配到固定的一个集群节点进行处理即可。
可能遇到的问题:
-
尽量避免节点竞争全局资源,如磁盘竞争,各个节点如果同时访问某个磁盘文件的话,很可能导致 IO 异常; -
很难高效利用资源池,如连接池,一般都是在节点建立自己独立的连接池,这样有可能导致一些节点池满了而另外一些节点仍有较多空余; -
各个节点受到 32 位的内存限制; -
大量使用本地缓存的应用,在逻辑集群中会造成较大的内存浪费,因为每个逻辑节点都有一份缓存,这时候可以考虑把本地缓存改成集中式缓存。
调优案例分析与实战
场景描述
一个小型系统,使用 32 位 JDK,4G 内存,测试期间发现服务端不定时抛出内存溢出异常。 加入 -XX:+HeapDumpOnOutOfMemoryError(添加这个参数后,堆内存溢出时就会输出异常日志), 但再次发生内存溢出时,没有生成相关异常日志。
分析
在 32 位 JDK 上,1.6G 分配给堆,还有一部分分配给 JVM 的其他内存,直接内存最大也只能在剩余的 0.4G 空间中分出一部分, 如果使用了 NIO,JVM 会在 JVM 内存之外分配内存空间,那么就要小心“直接内存”不足时发生内存溢出异常了。
直接内存的回收过程
直接内存虽然不是 JVM 内存空间,但它的垃圾回收也由 JVM 负责。
垃圾收集进行时,虚拟机虽然会对直接内存进行回收, 但是直接内存却不能像新生代、老年代那样,发现空间不足了就通知收集器进行垃圾回收, 它只能等老年代满了后 Full GC,然后“顺便”帮它清理掉内存的废弃对象。 否则只能一直等到抛出内存溢出异常时,先 catch 掉,再在 catch 块里大喊 “System.gc()”。 要是虚拟机还是不听,那就只能眼睁睁看着堆中还有许多空闲内存,自己却不得不抛出内存溢出异常了。
本文由 mdnice 多平台发布文章来源地址https://www.toymoban.com/news/detail-513742.html
到了这里,关于JVM 性能调优的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!