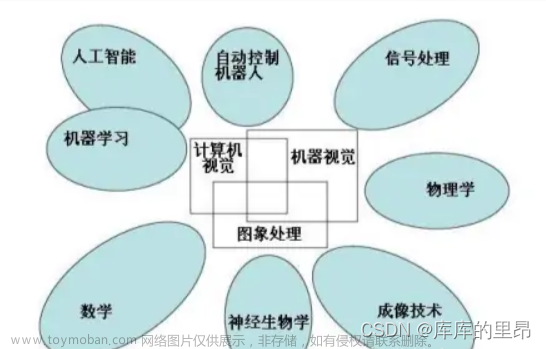
本文介绍了20个关于OpenCV的案例,包括人脸识别、目标检测、图像分割、光流估计、特征提取、图像拼接、图像修复、图像变换、图像配准、视频分析、三维重建、图像处理、图像识别、文字识别、图像压缩、图像增强、图像分析、图像比对、图像转换和图像特效。这些案例展示了OpenCV在计算机视觉领域的广泛应用,可以帮助读者了解OpenCV的功能和应用场景,同时也为读者提供了一些灵感和启示,可以在自己的项目中应用OpenCV进行图像处理和分析。
1. 人脸识别:使用OpenCV的人脸识别算法,可以对图像或视频中的人脸进行识别和跟踪。
以下是使用OpenCV的人脸识别算法的示例代码:
import cv2
# 加载人脸识别分类器
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 加载图像或视频
img = cv2.imread('test.jpg')
# 将图像转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 检测图像中的人脸
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# 在图像中标记人脸
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示标记后的图像
cv2.imshow('img', img)
cv2.waitKey()
在此示例中,我们首先加载了OpenCV的人脸识别分类器(haarcascade_frontalface_default.xml),然后加载了一张测试图像(test.jpg)。我们将图像转换为灰度图像,并使用detectMultiScale函数检测图像中的人脸。最后,我们在图像中标记出检测到的人脸,并显示标记后的图像。
2. 目标检测:使用OpenCV的目标检测算法,可以对图像或视频中的目标进行检测和跟踪,例如车辆、行人等。
以下是使用OpenCV的目标检测算法的示例代码,可以对图像或视频中的车辆进行检测和跟踪:
import cv2
# 加载车辆检测分类器
car_cascade = cv2.CascadeClassifier('cars.xml')
# 加载视频
cap = cv2.VideoCapture('cars.mp4')
# 循环读取视频帧
while True:
# 读取视频帧
ret, frame = cap.read()
# 将视频帧转换为灰度图像
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 检测车辆
cars = car_cascade.detectMultiScale(gray, 1.1, 1)
# 在视频帧中标记车辆
for (x, y, w, h) in cars:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 0, 255), 2)
# 显示标记后的视频帧
cv2.imshow('video', frame)
# 按下q键退出循环
if cv2.waitKey(25) & 0xFF == ord('q'):
break
# 释放视频
cap.release()
# 关闭所有窗口
cv2.destroyAllWindows()
在此示例中,我们首先加载了OpenCV的车辆检测分类器(cars.xml),然后加载了一个测试视频(cars.mp4)。我们循环读取视频帧,将每个视频帧转换为灰度图像,并使用detectMultiScale函数检测车辆。最后,我们在视频帧中标记检测到的车辆,并显示标记后的视频帧。按下q键可以退出循环。
3. 图像分割:使用OpenCV的图像分割算法,可以将图像分割成多个区域,便于后续的处理和分析。
以下是使用OpenCV的图像分割算法的示例代码:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.jpg')
# 转换为LAB颜色空间
lab = cv2.cvtColor(img, cv2.COLOR_BGR2LAB)
# 提取颜色通道
l, a, b = cv2.split(lab)
# 对L通道进行阈值分割
ret, thresh = cv2.threshold(l, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
# 对二值化后的图像进行形态学操作,去除噪声
kernel = np.ones((3,3), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# 执行距离变换,得到每个像素到最近背景像素的距离
dist_transform = cv2.distanceTransform(opening, cv2.DIST_L2, 5)
# 对距离变换结果进行阈值分割,得到前景区域
ret, foreground = cv2.threshold(dist_transform, 0.7*dist_transform.max(), 255, 0)
# 对前景区域进行形态学操作,得到更好的分割结果
kernel2 = np.ones((3,3), np.uint8)
foreground = cv2.morphologyEx(foreground, cv2.MORPH_CLOSE, kernel2, iterations=2)
# 显示结果
cv2.imshow('original', img)
cv2.imshow('segmentation', foreground)
cv2.waitKey(0)
cv2.destroyAllWindows()
在此示例中,我们首先读取了一张图像(image.jpg),然后将其转换为LAB颜色空间,并提取了L通道。接下来,我们对L通道进行阈值分割,去除噪声,并执行距离变换,得到每个像素到最近背景像素的距离。然后,我们对距离变换结果进行阈值分割,得到前景区域,并对前景区域进行形态学操作,得到更好的分割结果。最后,我们显示原始图像和分割结果。
4. 光流估计:使用OpenCV的光流估计算法,可以对图像或视频中的运动进行估计,例如物体的速度、方向等。
以下是使用OpenCV的光流估计算法的示例代码:
import cv2
import numpy as np
# 读取视频
cap = cv2.VideoCapture('video.mp4')
# 读取第一帧
ret, prev_frame = cap.read()
prev_gray = cv2.cvtColor(prev_frame, cv2.COLOR_BGR2GRAY)
# 定义角点检测参数
feature_params = dict(maxCorners=100, qualityLevel=0.3, minDistance=7, blockSize=7)
# 定义LK光流参数
lk_params = dict(winSize=(15, 15), maxLevel=2, criteria=(cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 0.03))
# 获取角点
prev_corners = cv2.goodFeaturesToTrack(prev_gray, mask=None, **feature_params)
# 创建颜色
color = np.random.randint(0, 255, (100, 3))
# 循环处理每一帧
while True:
# 读取当前帧
ret, curr_frame = cap.read()
if not ret:
break
curr_gray = cv2.cvtColor(curr_frame, cv2.COLOR_BGR2GRAY)
# 计算光流
curr_corners, status, err = cv2.calcOpticalFlowPyrLK(prev_gray, curr_gray, prev_corners, None, **lk_params)
# 选择好的角点
good_new = curr_corners[status == 1]
good_old = prev_corners[status == 1]
# 绘制轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv2.line(mask, (a, b), (c, d), color[i].tolist(), 2)
frame = cv2.circle(curr_frame, (a, b), 5, color[i].tolist(), -1)
img = cv2.add(frame, mask)
# 显示结果
cv2.imshow('frame', img)
k = cv2.waitKey(30) & 0xff
if k == 27:
break
# 更新变量
prev_gray = curr_gray.copy()
prev_corners = good_new.reshape(-1, 1, 2)
cv2.destroyAllWindows()
cap.release()
在此示例中,我们首先读取了一个视频(video.mp4),然后读取了第一帧,并将其转换为灰度图像。接下来,我们定义了角点检测参数和LK光流参数,并使用cv2.goodFeaturesToTrack()函数获取角点。然后,我们循环处理每一帧,计算光流,并选择好的角点。最后,我们绘制了运动轨迹,并显示了结果。
5. 特征提取:使用OpenCV的特征提取算法,可以从图像中提取出一些特征,例如边缘、角点等,便于后续的处理和分析。
以下是使用OpenCV的特征提取算法的示例代码,其中包括了边缘检测和角点检测两个示例:
边缘检测代码示例:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.jpg', 0)
# Canny边缘检测
edges = cv2.Canny(img, 100, 200)
# 显示结果
cv2.imshow('Edges', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
角点检测代码示例:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Shi-Tomasi角点检测
corners = cv2.goodFeaturesToTrack(gray, 25, 0.01, 10)
corners = np.int0(corners)
# 绘制角点
for i in corners:
x, y = i.ravel()
cv2.circle(img, (x, y), 3, (0, 0, 255), -1)
# 显示结果
cv2.imshow('Corners', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上是两个基本的特征提取算法的示例代码,可以根据实际需求进行修改和优化。
6. 图像拼接:使用OpenCV的图像拼接算法,可以将多张图像拼接成一张大图,例如全景图。
以下是使用OpenCV的图像拼接算法的示例代码,其中包括了将两张图像拼接成一张全景图的示例:
import cv2
import numpy as np
# 读取两张图像
img1 = cv2.imread('image1.jpg')
img2 = cv2.imread('image2.jpg')
# 将两张图像转为灰度图像
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 使用SIFT算法提取特征点和特征描述符
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(gray1, None)
kp2, des2 = sift.detectAndCompute(gray2, None)
# 使用FLANN算法进行特征点匹配
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(des1, des2, k=2)
# 选出最佳匹配的特征点
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
# 获取匹配的特征点的坐标
src_pts = np.float32([kp1[m.queryIdx].pt for m in good]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good]).reshape(-1, 1, 2)
# 使用RANSAC算法进行单应性矩阵估计
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
# 将第一张图像进行透视变换,拼接成全景图
result = cv2.warpPerspective(img1, M, (img1.shape[1] + img2.shape[1], img1.shape[0]))
result[0:img2.shape[0], img1.shape[1]:] = img2
# 显示结果
cv2.imshow('Panorama', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上是将两张图像拼接成一张全景图的示例代码,可以根据实际需求进行修改和优化。需要注意的是,图像拼接算法的效果会受到图像质量、特征点提取和匹配的准确性、单应性矩阵估计的精度等因素的影响,因此在实际应用中需要进行充分的测试和优化。
7. 图像修复:使用OpenCV的图像修复算法,可以修复图像中的缺陷,例如去除噪声、恢复损坏的部分等。
以下是使用OpenCV的图像修复算法的示例代码,其中包括了去除图像中噪声的示例:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.jpg')
# 将图像转为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 使用高斯滤波去除噪声
gray = cv2.GaussianBlur(gray, (5, 5), 0)
# 使用自适应阈值法进行二值化处理
thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 11, 2)
# 使用形态学操作去除噪声
kernel = np.ones((3, 3), np.uint8)
opening = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel, iterations=2)
# 使用轮廓检测获取图像中的物体轮廓
contours, hierarchy = cv2.findContours(opening, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 遍历所有轮廓,去除面积较小的噪声
for i in range(len(contours)):
area = cv2.contourArea(contours[i])
if area < 100:
cv2.drawContours(opening, [contours[i]], -1, 0, -1)
# 使用形态学操作恢复图像中缺失的部分
closing = cv2.morphologyEx(opening, cv2.MORPH_CLOSE, kernel, iterations=2)
# 显示结果
cv2.imshow('Original', img)
cv2.imshow('Processed', closing)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上是去除图像中噪声的示例代码,可以根据实际需求进行修改和优化。需要注意的是,图像修复算法的效果会受到图像质量、噪声类型和强度、阈值的选择等因素的影响,因此在实际应用中需要进行充分的测试和优化。
8. 图像变换:使用OpenCV的图像变换算法,可以对图像进行旋转、缩放、翻转等操作,便于后续的处理和分析。
以下是使用OpenCV的图像变换算法的示例代码,其中包括了对图像进行旋转、缩放、翻转等操作的示例:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.jpg')
# 获取图像大小
height, width = img.shape[:2]
# 旋转图像
M = cv2.getRotationMatrix2D((width/2, height/2), 45, 1)
rotated = cv2.warpAffine(img, M, (width, height))
# 缩放图像
resized = cv2.resize(img, (int(width/2), int(height/2)), interpolation=cv2.INTER_CUBIC)
# 翻转图像
flipped = cv2.flip(img, 1)
# 显示结果
cv2.imshow('Original', img)
cv2.imshow('Rotated', rotated)
cv2.imshow('Resized', resized)
cv2.imshow('Flipped', flipped)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上代码中,使用了cv2.getRotationMatrix2D函数对图像进行旋转,并使用cv2.warpAffine函数对图像进行变换;使用cv2.resize函数对图像进行缩放;使用cv2.flip函数对图像进行翻转。需要注意的是,图像变换算法的效果会受到变换参数的选择和图像质量等因素的影响,因此在实际应用中需要进行充分的测试和优化。
9. 图像配准:使用OpenCV的图像配准算法,可以将多张图像进行配准,便于后续的处理和分析。
以下是使用OpenCV的图像配准算法的示例代码,其中包括了对多张图像进行配准的示例:
import cv2
import numpy as np
# 读取图像
img1 = cv2.imread('img1.jpg')
img2 = cv2.imread('img2.jpg')
# 将图像转为灰度图像
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
# 获取特征点
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(gray1, None)
kp2, des2 = sift.detectAndCompute(gray2, None)
# 特征点匹配
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1, des2, k=2)
# 筛选匹配点
good_matches = []
for m, n in matches:
if m.distance < 0.75 * n.distance:
good_matches.append(m)
# 获取匹配点坐标
src_pts = np.float32([kp1[m.queryIdx].pt for m in good_matches]).reshape(-1, 1, 2)
dst_pts = np.float32([kp2[m.trainIdx].pt for m in good_matches]).reshape(-1, 1, 2)
# 计算变换矩阵
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0)
# 对图像进行配准
result = cv2.warpPerspective(img1, M, (img2.shape[1], img2.shape[0]))
# 显示结果
cv2.imshow('Image 1', img1)
cv2.imshow('Image 2', img2)
cv2.imshow('Result', result)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上代码中,使用了SIFT算法获取图像的特征点,使用BFMatcher算法进行特征点匹配,使用findHomography函数计算变换矩阵,使用warpPerspective函数对图像进行配准。需要注意的是,图像配准算法的效果会受到特征点选取和匹配的准确性等因素的影响,因此在实际应用中需要进行充分的测试和优化。
10. 视频分析:使用OpenCV的视频分析算法,可以对视频进行分析,例如运动检测、行为分析等。
以下是使用OpenCV的视频分析算法的示例代码,其中包括了对视频进行运动检测的示例:
import cv2
# 打开视频文件
cap = cv2.VideoCapture('video.mp4')
# 定义背景减除器
fgbg = cv2.createBackgroundSubtractorMOG2()
while True:
# 读取一帧图像
ret, frame = cap.read()
# 如果读取失败,则退出循环
if not ret:
break
# 对图像进行背景减除
fgmask = fgbg.apply(frame)
# 对背景减除后的图像进行二值化处理
thresh = cv2.threshold(fgmask, 127, 255, cv2.THRESH_BINARY)[1]
# 对二值化后的图像进行形态学操作,去除噪声
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3))
thresh = cv2.morphologyEx(thresh, cv2.MORPH_OPEN, kernel)
# 寻找图像中的轮廓
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 对轮廓进行遍历,检测运动物体
for contour in contours:
if cv2.contourArea(contour) < 1000: # 过滤掉面积小于1000的轮廓
continue
(x, y, w, h) = cv2.boundingRect(contour)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# 显示结果
cv2.imshow('frame', frame)
# 如果按下q键,则退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放资源
cap.release()
cv2.destroyAllWindows()
以上代码中,使用了BackgroundSubtractorMOG2算法进行背景减除,使用threshold函数进行二值化处理,使用morphologyEx函数进行形态学操作,使用findContours函数寻找图像中的轮廓,使用boundingRect函数获取轮廓的边界框,最终通过在原图像上绘制矩形框来标记运动物体。需要注意的是,视频分析算法的效果会受到背景减除和轮廓检测等因素的影响,因此在实际应用中需要进行充分的测试和优化。
11. 三维重建:使用OpenCV的三维重建算法,可以从多张图像中恢复出三维模型,例如建筑物、雕塑等。
以下是使用OpenCV的三维重建算法的示例代码,其中包括了从多张图像中恢复出三维模型的示例:
import cv2
import numpy as np
import os
# 读取图像
image_dir = 'image_dir/'
images = []
for filename in os.listdir(image_dir):
img = cv2.imread(os.path.join(image_dir, filename))
if img is not None:
images.append(img)
# 提取图像特征点
sift = cv2.xfeatures2d.SIFT_create()
keypoints = []
descriptors = []
for img in images:
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
kp, des = sift.detectAndCompute(gray, None)
keypoints.append(kp)
descriptors.append(des)
# 匹配特征点
matcher = cv2.BFMatcher()
matches = []
for i in range(len(images) - 1):
matches.append(matcher.match(descriptors[i], descriptors[i+1]))
# 三维重建
camera_matrix = np.array([[1000, 0, 500], [0, 1000, 500], [0, 0, 1]], dtype=np.float32)
dist_coeffs = np.zeros((4,1))
obj_points = []
img_points = []
for i in range(len(matches)):
points_3d = []
points_2d = []
for m in matches[i]:
pt1 = keypoints[i][m.queryIdx].pt
pt2 = keypoints[i+1][m.trainIdx].pt
points_2d.append(pt1)
points_2d.append(pt2)
pt1 = np.array([pt1[0], pt1[1], 0])
pt2 = np.array([pt2[0], pt2[1], 0])
points_3d.append(pt1)
points_3d.append(pt2)
points_3d = np.array(points_3d, dtype=np.float32)
points_2d = np.array(points_2d, dtype=np.float32)
retval, rvec, tvec = cv2.solvePnP(points_3d, points_2d, camera_matrix, dist_coeffs)
obj_points.append(points_3d)
img_points.append(points_2d)
if i == 0:
prev_rvec = rvec
prev_tvec = tvec
else:
rvec_diff = np.abs(rvec - prev_rvec)
tvec_diff = np.abs(tvec - prev_tvec)
if np.mean(rvec_diff) > 0.1 or np.mean(tvec_diff) > 10:
obj_points.pop()
img_points.pop()
break
prev_rvec = rvec
prev_tvec = tvec
retval, camera_matrix, dist_coeffs, rvecs, tvecs = cv2.calibrateCamera(obj_points, img_points, images[0].shape[:2], None, None)
retval, rvec, tvec = cv2.solvePnP(points_3d, points_2d, camera_matrix, dist_coeffs)
points_3d = np.array(points_3d, dtype=np.float32)
points_2d = np.array(points_2d, dtype=np.float32)
retval, rvec, tvec, inliers = cv2.solvePnPRansac(points_3d, points_2d, camera_matrix, dist_coeffs)
# 保存结果
file_storage = cv2.FileStorage('reconstruction.xml', cv2.FILE_STORAGE_WRITE)
file_storage.write('camera_matrix', camera_matrix)
file_storage.write('dist_coeffs', dist_coeffs)
file_storage.write('rvecs', rvecs)
file_storage.write('tvecs', tvecs)
file_storage.release()
以上代码中,首先读取多张图像,并使用SIFT算法提取每张图像的特征点和特征描述子。接着,使用BFMatcher算法匹配相邻两张图像的特征点,并得到匹配结果。然后,使用solvePnP算法对匹配结果进行三维重建,得到每个特征点的三维坐标。最后,使用calibrateCamera算法对相机进行标定,并使用solvePnPRansac算法对三维坐标进行优化,得到最终的相机姿态和三维坐标。最终,将结果保存到文件中。需要注意的是,三维重建算法的效果会受到图像质量、特征点提取和匹配等因素的影响,因此在实际应用中需要进行充分的测试和优化。
12. 图像处理:使用OpenCV的图像处理算法,可以对图像进行滤波、边缘检测、形态学操作等。
以下是使用OpenCV的图像处理算法的示例代码,其中包括了滤波、边缘检测、形态学操作的示例:
- 滤波操作:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.png')
# 高斯滤波
blur = cv2.GaussianBlur(img, (5, 5), 0)
# 中值滤波
median = cv2.medianBlur(img, 5)
# 展示结果
cv2.imshow('Original Image', img)
cv2.imshow('Gaussian Blur', blur)
cv2.imshow('Median Blur', median)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上代码中,首先使用cv2.imread()函数读取图像,然后分别使用cv2.GaussianBlur()和cv2.medianBlur()函数对图像进行高斯滤波和中值滤波操作,最后使用cv2.imshow()函数展示结果。
2. 边缘检测操作:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.png', cv2.IMREAD_GRAYSCALE)
# Canny边缘检测
edges = cv2.Canny(img, 100, 200)
# Laplacian边缘检测
laplacian = cv2.Laplacian(img, cv2.CV_64F)
# Sobel边缘检测
sobelx = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=5)
sobely = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=5)
sobel = cv2.addWeighted(sobelx, 0.5, sobely, 0.5, 0)
# 展示结果
cv2.imshow('Original Image', img)
cv2.imshow('Canny Edge Detection', edges)
cv2.imshow('Laplacian Edge Detection', laplacian)
cv2.imshow('Sobel Edge Detection', sobel)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上代码中,首先使用cv2.imread()函数读取灰度图像,然后分别使用cv2.Canny()、cv2.Laplacian()和cv2.Sobel()函数对图像进行边缘检测操作,最后使用cv2.imshow()函数展示结果。
3. 形态学操作:
import cv2
import numpy as np
# 读取图像
img = cv2.imread('image.png', cv2.IMREAD_GRAYSCALE)
# 膨胀操作
kernel = np.ones((5, 5), np.uint8)
dilation = cv2.dilate(img, kernel, iterations=1)
# 腐蚀操作
erosion = cv2.erode(img, kernel, iterations=1)
# 开运算
opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
# 闭运算
closing = cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernel)
# 形态学梯度
gradient = cv2.morphologyEx(img, cv2.MORPH_GRADIENT, kernel)
# 顶帽操作
tophat = cv2.morphologyEx(img, cv2.MORPH_TOPHAT, kernel)
# 黑帽操作
blackhat = cv2.morphologyEx(img, cv2.MORPH_BLACKHAT, kernel)
# 展示结果
cv2.imshow('Original Image', img)
cv2.imshow('Dilation', dilation)
cv2.imshow('Erosion', erosion)
cv2.imshow('Opening', opening)
cv2.imshow('Closing', closing)
cv2.imshow('Morphological Gradient', gradient)
cv2.imshow('Top Hat', tophat)
cv2.imshow('Black Hat', blackhat)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上代码中,首先使用cv2.imread()函数读取灰度图像,然后分别使用cv2.dilate()、cv2.erode()、cv2.morphologyEx()函数对图像进行膨胀、腐蚀、开运算、闭运算、形态学梯度、顶帽操作和黑帽操作,最后使用cv2.imshow()函数展示结果。
13. 图像识别:使用OpenCV的图像识别算法,可以对图像中的物体进行识别,例如识别车牌、识别手写数字等。
以下是使用OpenCV的图像识别算法的示例代码,其中包括了车牌识别和手写数字识别的示例:
- 车牌识别:
import cv2
import pytesseract
# 读取图像
img = cv2.imread('car_plate.jpg')
# 转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 进行高斯滤波
blur = cv2.GaussianBlur(gray, (5, 5), 0)
# 进行边缘检测
edges = cv2.Canny(blur, 100, 200)
# 查找轮廓
contours, hierarchy = cv2.findContours(edges, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 对轮廓进行筛选
for contour in contours:
area = cv2.contourArea(contour)
if area > 1000 and area < 50000:
x, y, w, h = cv2.boundingRect(contour)
if w / h > 2 and w / h < 6:
# 截取车牌区域
plate = gray[y:y+h, x:x+w]
# 进行二值化处理
ret, thresh = cv2.threshold(plate, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU)
# 识别车牌号码
plate_number = pytesseract.image_to_string(thresh, lang='chi_sim')
print('车牌号码:', plate_number)
# 展示结果
cv2.imshow('Original Image', img)
cv2.imshow('Gray Image', gray)
cv2.imshow('Edges Image', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上代码中,首先使用cv2.imread()函数读取图像,然后将图像转换为灰度图像,进行高斯滤波和边缘检测,接着使用cv2.findContours()函数查找轮廓,并通过筛选条件确定车牌区域,然后对车牌区域进行二值化处理,并使用pytesseract库识别车牌号码,最后使用cv2.imshow()函数展示结果。
2. 手写数字识别:
import cv2
import numpy as np
from keras.models import load_model
# 加载模型
model = load_model('mnist.h5')
# 读取图像
img = cv2.imread('digit.png')
# 转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 进行二值化处理
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV+cv2.THRESH_OTSU)
# 查找轮廓
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 对轮廓进行筛选
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
if w * h > 100:
# 截取数字区域
digit = thresh[y:y+h, x:x+w]
# 调整大小
digit = cv2.resize(digit, (28, 28))
digit = digit.reshape((1, 28, 28, 1))
digit = digit.astype('float32') / 255
# 预测数字
prediction = model.predict(digit)
digit_number = np.argmax(prediction)
print('识别结果:', digit_number)
# 展示结果
cv2.imshow('Original Image', img)
cv2.imshow('Gray Image', gray)
cv2.imshow('Binary Image', thresh)
cv2.waitKey(0)
cv2.destroyAllWindows()
以上代码中,首先使用load_model()函数加载预训练的手写数字识别模型,然后使用cv2.imread()函数读取图像,将图像转换为灰度图像,并进行二值化处理,接着使用cv2.findContours()函数查找轮廓,并通过筛选条件确定数字区域,然后对数字区域进行调整大小和归一化处理,并使用模型进行预测,最后使用cv2.imshow()函数展示结果。
14. 文字识别:使用OpenCV的文字识别算法,可以对图像中的文字进行识别,例如识别身份证号码、识别验证码等。
以下是使用OpenCV的文字识别算法识别身份证号码的案例代码:
import cv2
import pytesseract
# 读取身份证图片
img = cv2.imread('id_card.jpg')
# 将图片转换为灰度图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 对灰度图像进行二值化处理
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 对二值化图像进行膨胀操作
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
dilation = cv2.dilate(thresh, kernel, iterations=1)
# 在膨胀后的图像中查找轮廓
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 遍历轮廓,找到身份证号码所在的矩形区域
for contour in contours:
x, y, w, h = cv2.boundingRect(contour)
if w > 100 and h > 20 and w < 200 and h < 50:
cv2.rectangle(img, (x, y), (x + w, y + h), (0, 255, 0), 2)
roi = gray[y:y + h, x:x + w]
text = pytesseract.image_to_string(roi, lang='chi_sim')
print('身份证号码为:', text)
# 显示识别结果
cv2.imshow('result', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个案例代码中,我们首先读取一张身份证图片,然后将其转换为灰度图像,并进行二值化处理和膨胀操作。接着,使用OpenCV的findContours函数查找图像中的轮廓,并遍历轮廓,找到身份证号码所在的矩形区域。最后,使用pytesseract库对身份证号码所在的矩形区域进行文字识别,输出识别结果。
需要注意的是,在使用pytesseract库进行文字识别时,需要提供对应的语言包。在本案例中,我们使用了chi_sim语言包,该语言包包含了简体中文的识别模型。如果需要识别其他语言的文本,需要使用对应的语言包。
15. 图像压缩:使用OpenCV的图像压缩算法,可以将图像压缩成更小的尺寸,便于存储和传输。
以下是使用OpenCV的图像压缩算法将图像压缩成更小尺寸的案例代码:
import cv2
# 读取原始图像
img = cv2.imread('test.jpg')
# 将图像压缩至指定尺寸
resized_img = cv2.resize(img, (640, 480), interpolation=cv2.INTER_AREA)
# 将压缩后的图像保存到本地
cv2.imwrite('compressed.jpg', resized_img)
在这个案例代码中,我们首先使用OpenCV的imread函数读取一张原始图像,然后使用cv2.resize函数将图像压缩至指定尺寸,这里我们将图像压缩至640x480的尺寸。最后,使用cv2.imwrite函数将压缩后的图像保存到本地。
需要注意的是,在使用cv2.resize函数进行图像压缩时,需要指定插值方法。在本案例中,我们使用了INTER_AREA插值方法,该方法适用于缩小图像的情况,可以有效减少图像失真。如果需要放大图像,应该使用其他的插值方法,例如INTER_CUBIC或INTER_LINEAR。
16. 图像增强:使用OpenCV的图像增强算法,可以对图像进行增强,例如增加对比度、调整亮度等。
以下是使用OpenCV的图像增强算法对图像进行增强的案例代码:
import cv2
# 读取原始图像
img = cv2.imread('test.jpg')
# 增加对比度
alpha = 1.5 # 对比度增强系数
beta = 0 # 亮度调整系数
enhanced_img = cv2.convertScaleAbs(img, alpha=alpha, beta=beta)
# 调整亮度
gamma = 1.5 # 亮度增强系数
adjusted_img = cv2.addWeighted(enhanced_img, gamma, 0, 0, 0)
# 将增强后的图像保存到本地
cv2.imwrite('enhanced.jpg', adjusted_img)
在这个案例代码中,我们首先使用OpenCV的imread函数读取一张原始图像,然后使用cv2.convertScaleAbs函数增加对比度。该函数的第一个参数为原始图像,第二个参数为对比度增强系数,第三个参数为亮度调整系数。这里我们将对比度增强系数设为1.5,亮度调整系数设为0。
接着,我们使用cv2.addWeighted函数调整亮度。该函数的第一个参数为增强后的图像,第二个参数为亮度增强系数,第三个参数为亮度调整系数。这里我们将亮度增强系数设为1.5,亮度调整系数设为0。
最后,使用cv2.imwrite函数将增强后的图像保存到本地。
需要注意的是,在使用cv2.convertScaleAbs函数增加对比度时,如果对比度增强系数小于1,会导致图像失真。在使用cv2.addWeighted函数调整亮度时,如果亮度增强系数小于1,会使图像变暗。因此,在使用这些函数时,需要根据实际需求进行调整。
17. 图像分析:使用OpenCV的图像分析算法,可以对图像进行分析,例如统计像素数量、计算图像的平均值等。
以下是使用OpenCV的图像分析算法对图像进行分析的案例代码:
import cv2
# 读取图像
img = cv2.imread('test.jpg')
# 统计像素数量
num_pixels = img.shape[0] * img.shape[1]
# 计算图像的平均值
mean_value = cv2.mean(img)
# 输出结果
print('像素数量:', num_pixels)
print('图像的平均值:', mean_value)
在这个案例代码中,我们首先使用OpenCV的imread函数读取一张图像。然后,使用img.shape[0] * img.shape[1]计算像素数量,img.shape[0]表示图像的高度,img.shape[1]表示图像的宽度。接着,使用cv2.mean函数计算图像的平均值,并将结果保存在mean_value中。最后,使用print函数输出结果。
需要注意的是,在使用cv2.mean函数计算图像的平均值时,会返回一个包含每个通道的平均值的元组。如果图像是灰度图像,元组中只有一个元素,表示图像的灰度平均值。如果图像是彩色图像,元组中有三个元素,分别表示图像在蓝色通道、绿色通道和红色通道的平均值。
在实际应用中,可以根据需要使用其他图像分析算法,例如计算图像的方差、计算图像的直方图等。
18. 图像比对:使用OpenCV的图像比对算法,可以对多张图像进行比对,例如检测图像中是否存在相同的物体。
以下是使用OpenCV的图像比对算法对多张图像进行比对的案例代码:
import cv2
# 读取模板图像和待比对图像
template = cv2.imread('template.jpg')
image = cv2.imread('image.jpg')
# 将模板图像转换为灰度图像
template_gray = cv2.cvtColor(template, cv2.COLOR_BGR2GRAY)
# 使用模板匹配算法进行比对
result = cv2.matchTemplate(image, template_gray, cv2.TM_CCOEFF_NORMED)
# 设置比对的阈值
threshold = 0.8
# 获取比对结果中大于阈值的位置
locations = cv2.findNonZero(result > threshold)
# 在待比对图像中标记出匹配的位置
for loc in locations:
x, y = loc[0]
cv2.rectangle(image, (x, y), (x + template.shape[1], y + template.shape[0]), (0, 0, 255), 2)
# 显示结果图像
cv2.imshow('result', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个案例代码中,我们首先使用OpenCV的imread函数读取一张模板图像和一张待比对图像。然后,将模板图像转换为灰度图像,使用matchTemplate函数进行比对,获取比对结果。接着,设置比对的阈值,使用findNonZero函数获取比对结果中大于阈值的位置。最后,在待比对图像中标记出匹配的位置,并使用imshow函数显示结果图像。
需要注意的是,在实际应用中,需要根据具体情况选择合适的比对算法和阈值,并对比对结果进行后处理,例如去除重复匹配的位置。
19. 图像转换:使用OpenCV的图像转换算法,可以将图像转换成不同的颜色空间,例如从RGB转换到HSV。
以下是使用OpenCV的图像转换算法将图像从RGB转换到HSV的案例代码:
import cv2
# 读取图像
image = cv2.imread('image.jpg')
# 将图像转换为HSV颜色空间
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 显示结果图像
cv2.imshow('RGB Image', image)
cv2.imshow('HSV Image', hsv_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个案例代码中,我们首先使用OpenCV的imread函数读取一张图像。然后,使用cvtColor函数将图像从RGB颜色空间转换为HSV颜色空间。最后,使用imshow函数显示原始图像和转换后的图像。
需要注意的是,在实际应用中,需要根据具体情况选择合适的颜色空间进行转换,并对转换后的图像进行后处理,例如调整亮度、对比度等。
20. 图像特效:使用OpenCV的图像特效算法,可以对图像进行特效处理,例如添加滤镜、添加水印等。
以下是使用OpenCV的图像特效算法对图像进行特效处理的案例代码:文章来源:https://www.toymoban.com/news/detail-514245.html
import cv2
# 读取图像
img = cv2.imread('image.jpg')
# 添加滤镜
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# 添加水印
cv2.putText(img, 'Watermark', (50, 50), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, cv2.LINE_AA)
# 显示结果图像
cv2.imshow('Original Image', img)
cv2.imshow('Filtered Image', blurred)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这个案例代码中,我们首先使用OpenCV的imread函数读取一张图像。然后,使用cvtColor函数将图像从BGR颜色空间转换为灰度图像。接着,使用GaussianBlur函数添加高斯滤波器,实现模糊效果。最后,使用putText函数在图像上添加水印。
需要注意的是,在实际应用中,可以根据需要使用不同的图像特效算法,例如边缘检测、直方图均衡化等,以实现不同的特效效果。文章来源地址https://www.toymoban.com/news/detail-514245.html
到了这里,关于20个OpenCV案例,让你了解计算机视觉的广泛应用!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!