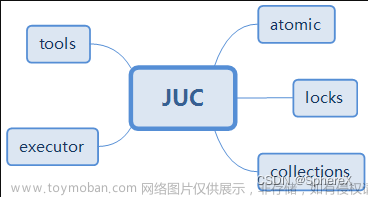
case1(表锁的读-写-读阻塞)
上篇文档中提到过
WRITE locks normally have higher priority than READ locks to ensure that updates are processed as soon as possible. This means that if one session obtains a READ lock and then another session requests a WRITE lock, subsequent READ lock requests wait until the session that requested the WRITE lock has obtained the lock and released it.
对于读-写-读的情况,由于锁的优先级较高,如果申请写的session迟迟获取不到锁,会阻塞后续其他session申请读锁;
先看正常情况,表锁的读锁是可以加多个的,如下,通过两个查询命令也可以看到确实同时加上了,没有阻塞;
//console1
lock tables simple read;
//console2
lock tables simple read;
select * from performance_schema.metadata_locks;

show OPEN TABLES where In_use > 0;
但是在两次读中间插入一次写锁的获取,后面的读锁也会同时被阻塞
//console1
lock tables simple read;
//console2
lock tables simple write;//被console1阻塞
//console3
lock tables simple read;//被console2阻塞
实验证明确实如文档所说,原理还在研究中...
case2(元数据锁读-写-读)
mysql45讲中提到的一个问题,具体分析见mysql MDL读写锁阻塞,以及online ddl造成的“插队”现象_花落的速度的博客-CSDN博客
case3(next-key lock 和 primary key)
在分析之前,先贴一下45讲的总结,该总结版本是 5.x 系列 <=5.7.24,8.0 系列 <=8.0.13,而我测试的版本是8.0.33
原则 1:加锁的基本单位是 next-key lock。希望你还记得,next-key lock 是前开后闭区间。
原则 2:查找过程中访问到的对象才会加锁。
优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
目前的数据
CREATE TABLE `simple` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(256) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '字符',
`seq` bigint NOT NULL COMMENT '消息序号',
`type` tinyint NOT NULL COMMENT '类型,tinyint值',
`version` int NOT NULL DEFAULT '1' COMMENT '版本值',
`msg` text COLLATE utf8mb4_bin COMMENT '消息',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
`yn` tinyint NOT NULL DEFAULT '1' COMMENT '是否有效',
`uni` int NOT NULL COMMENT '唯一索引',
PRIMARY KEY (`id`),
UNIQUE KEY `unidx` (`uni`),
KEY `seqidx` (`seq`)
) ENGINE=InnoDB AUTO_INCREMENT=301 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='简单测试表'

单一查询且查询结果存在(id=15)
存在一个意向表锁和行级读锁,理论上锁住的应该是(5, 15]这部分,但是由于是主键索引(唯一),所以只会锁15这一行,没有必要锁前面的间隙;这是优化1的体现;
LOCK_MODE为S,REC_NOT_GAP,我理解应该是说只有行锁,行锁类型是读锁;
start transaction ;
select * from simple where id = 15 lock in share mode ;
select * from performance_schema.data_locks;

单一查询且结果不存在(id=16)
将查询条件从15换成了16,理论上锁住的是(15,20]这部分,但是实验表明,20这行不会加行锁,所以最终表现为(15,20);这是优化2的体现;
LOCK_MODE为S,GAP,我理解应该是说只有间隙锁,即(15,20);
start transaction ;
select * from simple where id = 16 lock in share mode ;
select * from performance_schema.data_locks;
//console2
start transaction;
insert into simple (id,name,type,seq) value (16,5,5,5);//会被阻塞
select * from simple where id=20 for update ;//发现这行可以执行成功
既然可以成功,那就证明id = 16 的查询并没有锁20这一行,不然不可能加的上写锁

console2执行id=20后的结果

那这里如果我把id为20的更新成id为16会怎样?
update simple set id=16 where id=20;
经实验16-19都不能更新,20以后可以更,比如update simple set id=21 where id=20就可以成功;所以间隙锁是不是也能防止更新;又或者说,其实是因为更新的本质是删除再插入,再插入的被阻塞了,这里感兴趣的可以研究一下;
id>5
按照理论,应该锁住的后5往后的所有范围,即(5,15],(15,20],(20,23],(23,super..];
所以我推测LOCK_MODE只有一个S,代表加的是临键锁,类型是读锁,没有特殊表明缺少行锁或者间隙锁就是完整的临建锁,并且我在console2尝试插入id为6或者36的,都会被阻塞
//console1
start transaction ;
select * from simple where id>5 lock in share mode ;
select * from performance_schema.data_locks;
//console2
都会被阻塞
insert into simple (id,name,type,seq) value (6,5,5,5);
insert into simple (id,name,type,seq) value (36,5,5,5);

id>=5
和上面的唯一区别就是多了个等于5,那么5上是临键锁还是行锁呢?我觉得是行锁,因为优化1,而且这样和我们的认知也是比较符合的;
实际看到确实是这样;
start transaction ;
select * from simple where id>=5 lock in share mode ;
select * from performance_schema.data_locks;

id>5 and id<20
首先5<x<20,那么正常情况应该是(5,15]和(15,20],然后20因为不等于会被优化(触发了优化2),所以是(5,20)
start transaction ;
select * from simple where id>5 and id<20 lock in share mode ;
select * from performance_schema.data_locks;

id>5 and id<=20
假如是5<x<=20,那就会是(5,20];
但是注意我们前面提到过一个bug,可是我们看到目前就是锁到20为止,并不是(5,23),翻看评论区说在MySQL 8.0.18 已经修复,而我的版本是8.0.33,这里难道是修复了吗?先存疑,因为这里只能证明主键索引修复了,后面唯一索引那里还是乱的一批
id>30
应该会直接锁(23,super...)
case4(next-key lock和 unique key)
和case3唯一的区别就是将主键索引换成了唯一索引,猜测应该是一模一样的,因为文档里的特殊规则说的也都是唯一索引,而没有限制到主键上;
单一查询且查询结果存在(uni=15)
start transaction ;
select * from simple where uni = 15 lock in share mode ;
select * from performance_schema.data_locks;

理想很美好,现实很骨感;这是什么??突然想到行锁和间隙锁都是锁在索引上的锁,由于我查询结果是所有字段,所以会发生回表查询;当命中到唯一索引的时候会锁一次,然后根据主键id再锁一次;
但是现在我的uni和id字段值是一样的,所以为了区分,我将uni这一列都加了100,然后执行下面的句子
start transaction ;
select * from simple where uni = 115 lock in share mode ;
select * from performance_schema.data_locks;

可以看到primary那行应该是因为回表操作,而unidx那行应该则是对应唯一索引的查询,实际锁的范围逻辑和主键索引是一致的,只不过锁的内容我不理解,lock_data为115,15,为什么?select id from simple where uni = 115 lock in share mode ;
而且如果我们查询的不是select *,而是select id ,锁的信息就不包含primary那行了;
单一查询且结果不存在(uni=116)
start transaction ;
select * from simple where uni = 116 lock in share mode ;
select * from performance_schema.data_locks;

由于查询不到,所以也不会回表查询,就不存在primary那行了
uni>105
start transaction ;
select id from simple where simple.uni>105 lock in share mode ;
select * from performance_schema.data_locks;

我理解到每个索引节点的时候,都会执行一次select * from simple where id = x;所以会多出几行只有行锁primary的记录;
uni>=105只是会在unidx和primary上各多一个锁,但范围和唯一索引逻辑依然一致,就不贴了
uni>105 and uni<120
//console1
commit ;
start transaction ;
select * from simple where uni>105 and uni<120 lock in share mode ;
select * from performance_schema.data_locks;
//console2
select * from simple where uni=120 for update ;//被阻塞

这里和上面不一样的是,这里把120这行也锁上了,主键索引锁20是间隙锁,这里是临键锁;为什么这里会锁上呢?就很像是bug并没有修复,依然锁到了第一个不满足条件的,并且加了临键锁
uni>105 and uni<=120
start transaction ;
select * from simple where uni>105 and uni<=120 lock in share mode ;
select * from performance_schema.data_locks;

这里更离谱,这里为什么把123都给锁上了??感觉bug依然存在,多锁了一个区间
uni>130和上面的id>30结果一样,就不贴了
总结:对于唯一索引来说,因为存在主键,那么会产生回表操作,回表操作会给主键再加一把锁;而那个bug依旧存在,只有主键索引的修复了,非主键唯一索引依然存在这个bug;
case5(索引加在哪)

//console1
start transaction ;
select id from simple where uni=105 lock in share mode ;
select * from performance_schema.data_locks;
//console2
start transaction ;
update simple set name='new' where id=5;
现在我们已经清楚,执行完console1之后,会给unidx加一个行锁,因为没有回表,所以主键上没有锁;那么console2能否成功执行呢?
答案是
可以的;
我个人理解,是因为锁是加在索引上的,而索引是列维度的,不是行维度的;console2执行语句只会去判断id这个索引上,有没有5这个锁;
接下来我们反过来
//console1
start transaction ;
select * from simple where id=5 lock in share mode ;
select * from performance_schema.data_locks;
//console2
start transaction ;
update simple set name='new' where uni=105;
你试着一起敲一下就会发现,咦,console2怎么阻塞了呢?按上面所说的,不是不应该吗?
实际上console1的执行锁的确实是id;
但是你console2的执行,会回表啊,会尝试给id加写锁,但是id已经加了读锁了,所以自然不行了;
所以,不要盲目的只看查询条件,要理解当前语句都会加什么锁,是否和已经加的锁冲突;
最后,我们再来看一个附加题,下面两个语句加的锁是否一样呢?
start transaction ;
select id from simple where uni=105 lock in share mode ;
select * from performance_schema.data_locks;
start transaction ;
select id from simple where uni=105 for update ;
select * from performance_schema.data_locks;
在我没有尝试之前,我理解都没有回表,那么就应该一个是唯一索引加读锁,一个是唯一索引加写锁;
但是实际结果却是lock in share mode是对的,for update会认为你要更新语句,自动给主键加锁了
case6(next-key lock 和index)
吸取uni的教训,我给seq的值都加了200,现在这个表是这样的
seq=215
start transaction ;
select * from simple where seq=215 lock in share mode ;
select * from performance_schema.data_locks;

除了意向锁,其他三个我们一个个看;
seqidx(S)这行是普通索引执行时加的临键锁,由于不是唯一索引,所以不能优化(因为可能存在重复)
primary(S,REC_NOT_GAP)这是回表操作带来的
seqidx(S,GAP)这行是因为不是唯一索引,所以在查询到匹配的值之后不会立马停止(因为后面可能还存在相同的值),所以必须要到不符合条件的值为止,而所有查询过的都会加索引,所以存在一个间隙锁。
seq=216
start transaction ;
select * from simple where seq=216 lock in share mode ;
select * from performance_schema.data_locks;

我理解,应该是从205开始查,查到第一个不符合条件的值是215,加上中间没有回表,所以就这一个锁;理论应该是(215,220],但由于优化2,所以退化为间隙锁;
seq>215 and seq<220
start transaction ;
select * from simple where seq>215 and seq <220 lock in share mode ;
select * from performance_schema.data_locks;

从215开始匹配,第一个不符合条件的是220,所以只能是(215,220]
seq>215 and seq <=220
start transaction ;
select * from simple where seq>215 and seq <=220 lock in share mode ;
select * from performance_schema.data_locks;

这里和上面区别就是不符合条件的会到223为止,另外中间因为匹配成功会回一次表
seq>230和前面unidx>130和id>30都一样
case7(next-key和没有索引)
alter table simple drop index seqidx;
start transaction ;
select * from simple where seq=215 lock in share mode ;
select * from performance_schema.data_locks;
前面提到过,查询条件匹配不到索引或者只是索引的一部分,这个时候为了保证数据的准确性,会给整个表“加锁”,其实给表里所有的记录都加锁(这里我不知道描述的对不对,因为表锁!=所有记录加锁,虽然效果相似,但并不是一个东西).

同时因为这个表存在意向读锁,通过lock tables simple write 加写的表锁会冲突;文章来源:https://www.toymoban.com/news/detail-514482.html
参考文档:
06 | 全局锁和表锁 :给表加个字段怎么有这么多阻碍?-极客时间
mysql MDL读写锁阻塞,以及online ddl造成的“插队”现象_花落的速度的博客-CSDN博客文章来源地址https://www.toymoban.com/news/detail-514482.html
到了这里,关于Mysql中的锁(case篇)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!



](https://imgs.yssmx.com/Uploads/2024/04/851537-1.png)