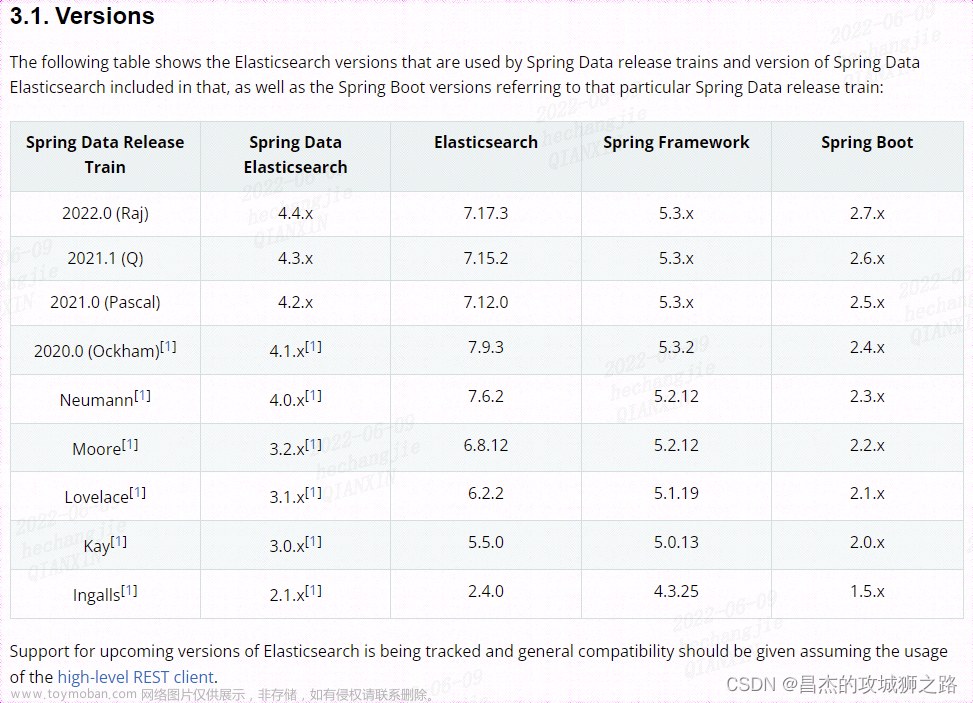
在Spring boot中主要有Java REST Client、spring-data-elasticsearch两种方式,这里建议使用Elasticsearch官方提供的Java High Level REST Client来集成。
一:导入依赖:
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.10.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.10.2</version>
</dependency>创建es映射
PUT user_index
{
"settings":{
"number_of_shards": "3",
"number_of_replicas": "0"
},
"mappings": {
"properties":{
"age" : {
"type" : "short"
},
"createTime" : {
"type" : "long"
},
"id" : {
"type" : "integer"
},
"updateTime" : {
"type" : "long"
},
"userName" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword"
}
}
}
}
}
}二:初始化客户端
1,添加配置文件添加连接信息
elasticsearch:
host: 127.0.0.1:9200
port: 9200
connTimeout: 3000
socketTimeout: 5000
connectionRequestTimeout: 1000
username: elastic
password: 1234562,添加ES配置类
import org.apache.http.HttpHost;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
/**
* @date 2022/7/15
**/
@Configuration
public class ElasticsearchConfiguration {
@Value("${elasticsearch.host}")
private String host;
@Value("${elasticsearch.port}")
private Integer port;
@Value("${elasticsearch.connTimeout}")
private Integer connTimeout;
@Value("${elasticsearch.socketTimeout}")
private Integer socketTimeout;
@Value("${elasticsearch.connectionRequestTimeout}")
private Integer connectionRequestTimeout;
@Value("${elasticsearch.username}")
private String username;
@Value("${elasticsearch.password}")
private String password;
@Bean(destroyMethod = "close", name = "client")
public RestHighLevelClient initRestClient() {
final CredentialsProvider credentialsProvider = new BasicCredentialsProvider();
credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
RestClientBuilder builder = RestClient.builder(toHttpHost())
.setRequestConfigCallback(requestConfigBuilder ->
requestConfigBuilder.setConnectTimeout(connTimeout)
.setSocketTimeout(socketTimeout)
.setConnectionRequestTimeout(connectionRequestTimeout))
.setHttpClientConfigCallback(h -> h.setDefaultCredentialsProvider(credentialsProvider));
return new RestHighLevelClient(builder);
}
/**
* 解析配置的字符串,转为HttpHost对象数组
*/
private HttpHost[] toHttpHost() {
if (!StringUtils.hasLength(host)) {
throw new RuntimeException("invalid elasticsearch configuration");
}
String[] hostArray = host.split(",");
HttpHost[] httpHosts = new HttpHost[hostArray.length];
HttpHost httpHost;
for (int i = 0; i < hostArray.length; i++) {
String[] strings = hostArray[i].split(":");
httpHost = new HttpHost(strings[0], Integer.parseInt(strings[1]), "http");
httpHosts[i] = httpHost;
}
return httpHosts;
}
}三,springboot api封装
@Component
public class EsUtil {
@Resource
private RestHighLevelClient restHighLevelClient;
/**
* 创建索引
*/
@SneakyThrows
public Boolean createIndex(String indexName) {
CreateIndexRequest request = new CreateIndexRequest(indexName);
// request.settings() 可以设置分片规则
// request.mapping() 可以设置映射字段
CreateIndexResponse indexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
return indexResponse.isAcknowledged();
}
/**
* 查询索引 * 查询全部
*/
@SneakyThrows
public List<String> searchIndex(String indexName) {
GetIndexRequest request = new GetIndexRequest(indexName);
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
if (!exists) {
return Lists.newArrayList();
}
GetIndexResponse getIndexResponse = restHighLevelClient.indices().get(request, RequestOptions.DEFAULT);
return Lists.newArrayList(getIndexResponse.getIndices());
}
/**
* 删除索引
*/
@SneakyThrows
public Boolean deleteIndex(String indexName) {
GetIndexRequest getIndexRequest = new GetIndexRequest(indexName);
boolean exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
if (!exists) {
return false;
}
DeleteIndexRequest request = new DeleteIndexRequest(indexName);
AcknowledgedResponse response = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
return response.isAcknowledged();
}
/**
* 文档数据插入(插入前会自动生成index)
* source() 支持json map 键值对等形式
*/
@SneakyThrows
public String insert(String indexName, String id, String jsonStr) {
IndexRequest indexRequest = new IndexRequest(indexName);
// 不设置id 会自动使用es默认的
if (StrUtil.isNotBlank(id)) {
indexRequest.id(id);
}
indexRequest.source(jsonStr, XContentType.JSON);
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
return indexResponse.getId();
}
/**
* 批量插入数据
* map {id, json}
*/
@SneakyThrows
public BulkResponse insertBatch(String indexName, Map<String, String> valueMap) {
BulkRequest bulkRequest = new BulkRequest();
Set<String> keySet = valueMap.keySet();
for (String id : keySet) {
IndexRequest request = new IndexRequest(indexName).id(id).source(valueMap.get(id), XContentType.JSON);
bulkRequest.add(request);
}
return restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
}
/**
* 更新- es有则更新,无则写入
* 可以接受 String、Map、XContentBuilder 或 Object 键对
*/
@SneakyThrows
public String update(String indexName, String id, String jsonStr) {
String searchById = searchById(indexName, id);
if (StrUtil.isBlank(searchById)) {
return null;
}
UpdateRequest updateRequest = new UpdateRequest(indexName, id).doc(jsonStr, XContentType.JSON);
UpdateResponse update = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
return update.getId();
}
/**
* 根据id进行删除
*/
@SneakyThrows
public String delete(String indexName, String id) {
DeleteRequest deleteRequest = new DeleteRequest(indexName, id);
DeleteResponse delete = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
return delete.getId();
}
/**
* 根据id进行删除
*/
@SneakyThrows
public List<String> deleteBatch(String indexName, List<String> ids) {
List<String> deleteList = Lists.newArrayList();
if (CollectionUtil.isEmpty(ids)) {
return deleteList;
}
for (String id : ids) {
DeleteRequest deleteRequest = new DeleteRequest(indexName, id);
deleteList.add(restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT).getId());
}
return deleteList;
}
/**
* 根据id进行查询
*/
@SneakyThrows
public String searchById(String indexName, String id) {
GetRequest getRequest = new GetRequest(indexName, id);
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
return getResponse.getSourceAsString();
}
/**
* 根据QueryBuilder来查询全部的条数
*/
@SneakyThrows
public Long findTotal(String indexName, QueryBuilder builder) {
SearchRequest searchRequest = new SearchRequest(indexName);
searchRequest.source().query(builder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
return response.getHits().getTotalHits().value;
}
/**
* 1, id查询: QueryBuilders.idsQuery().ids(id)
* 精确查询 QueryBuilders.termQuery("userName.keyword", "王五") .keyword 值是中文时需要,非中文时不需要
* 范围查询:QueryBuilders.rangeQuery().form().to().includeLower(false).includeUpper(false) 默认是true包含头尾,设置false去掉头尾
* 匹配所有:QueryBuilders.matchAllQuery()
* 模糊查询:QueryBuilders.fuzzyQuery()
* 全文检索,会进行分词,多个字段检索:QueryBuilders.multiMatchQuery("kimchy", "name", "description") 查询name或description包含kimchy
* 全文检索,会进行分词,单字段检索:QueryBuilders.matchQuery(name", "kimchy") 查询name包含kimchy
* 通配符查询, 支持*,匹配任何字符序列, 包括空,避免* 开始 QueryBuilders.wildcardQuery("user", "ki*hy")
* 跨度查询:QueryBuilders.span………
* 2,组合查询:BoolQueryBuilder must:and mustNot:not should:or in:termsQuery传list
* QueryBuilders.boolQuery().must(QueryBuilders.termsQuery("name", Lists.newArrayList())).mustNot(QueryBuilders.……);
* 过滤器查询:在原本查询结果的基础上对数据进行筛选,不会计算分值,所以效率比must更高
* QueryBuilders.boolQuery().filter(QueryBuilders.termQuery("userName", "王五"))
* 3, 查询部分字段: SearchSourceBuilder().fetchSource(new String[]{"userName", "age"}, new String[]{}) 查询userName和age字段
* 4, 权重计算,权重越高月靠前: 给name精确查询提高权重为2 QueryBuilders.termQuery("name", "kimchy").boost(2.0f)
* 高于设定分数, 不计算相关性查询: QueryBuilders.constantScoreQuery(QueryBuilders.termQuery("name", "kimchy")).boost(2.0f);
* 5,Nested&Join父子类型:得检索效率慢,不建议在ES做Join操作
* 父子查询:QueryBuilders.hasChildQuery("tweet", QueryBuilders.termQuery("user", "kimchy")).scoreMode("max")
* 嵌套查询, 内嵌文档查询 QueryBuilders.nestedQuery("location", QueryBuilders.boolQuery()
* .must(QueryBuilders.matchQuery("location.lat", 0.962590433140581))
* .must(QueryBuilders.rangeQuery("location.lon").lt(36.0000).gt(0.000))).scoreMode("total")
* 6, 排序:在查询的结果上进行二次排序,date、float 等类型添加排序,text类型的字段不允许排序 SearchSourceBuilder.sort()
*/
@SneakyThrows
public List<Map<String, Object>> findAll(String indexName, QueryBuilder builder) {
// 设置源字段过虑,第一个参数结果集包括哪些字段,第二个参数表示结果集不包括哪些字段
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder()
.query(builder)
.fetchSource(new String[]{"userName", "age"}, new String[]{});
SearchRequest request = new SearchRequest(indexName).source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
return handleResponse(response, 0, 0).getRecords();
}
/**
* 1,from-size浅分页适合数据量不大的情况(官网推荐是数据少于10000条),可以跳码进行查询
* 2,scroll 是一种滚屏形式的分页检索,scroll查询是很耗性能的方式,不建议在实时查询中运用
*/
@SneakyThrows
public P<Map<String, Object>> fromSizePage(String indexName, QueryBuilder queryBuilder, BasePageForm basePageForm) {
int from = basePageForm.getPageSize() * (basePageForm.getPageNum() - 1);
// 构建分页搜寻器
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(queryBuilder)
.from(from)
.size(basePageForm.getPageSize());
if (StrUtil.isNotBlank(basePageForm.getOrderBy())) {
sourceBuilder.sort(basePageForm.getOrderBy(), basePageForm.getOrderType() ? SortOrder.ASC : SortOrder.DESC);
}
SearchRequest request = new SearchRequest(indexName).source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
return handleResponse(response, basePageForm.getPageNum(), basePageForm.getPageSize());
}
/**
* 分页返回值处理
*/
@SneakyThrows
private P<Map<String, Object>> handleResponse(SearchResponse response, int pageNum, int pageSize) {
SearchHit[] hits = response.getHits().getHits();
List<Map<String, Object>> result = Arrays.stream(hits).map(h -> {
Map<String, Object> sourceAsMap = h.getSourceAsMap();
sourceAsMap.put("id", h.getId());
return sourceAsMap;
}).collect(Collectors.toList());
return new P<>(result, response.getHits().getTotalHits().value, pageSize, pageNum);
}
/**
* search_after 适用于深度分页+ 排序,分页是根据上一页最后一条数据来定位下一页的位置,所以无法跳页请求,性能最好
*/
@SneakyThrows
public P<Map<String, Object>> searchAfterPage(String indexName, QueryBuilder queryBuilder, BasePageForm basePageForm) {
// 构建分页搜寻器
// searchAfter需要将from设置为0或-1,当然也可以不写
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(queryBuilder)
.from(0)
.size(basePageForm.getPageSize());
if (StrUtil.isNotBlank(basePageForm.getOrderBy())) {
sourceBuilder.sort(basePageForm.getOrderBy(), basePageForm.getOrderType() ? SortOrder.ASC : SortOrder.DESC);
}
if (null != basePageForm.getSortCursor() && basePageForm.getSortCursor().length > 0) {
sourceBuilder.searchAfter(basePageForm.getSortCursor());
}
SearchRequest request = new SearchRequest(indexName).source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = response.getHits().getHits();
Object[] sortCursor = hits[hits.length - 1].getSortValues();
P<Map<String, Object>> page = handleResponse(response, basePageForm.getPageNum(), basePageForm.getPageSize());
page.setSortCursor(sortCursor);
return page;
}
/**
* moreLikeThisQuery: 实现基于内容推荐, 支持实现一句话相似文章查询
* percent_terms_to_match:匹配项(term)的百分比,默认是0.3
* min_term_freq:一篇文档中一个词语至少出现次数,小于这个值的词将被忽略,默认是2
* max_query_terms:一条查询语句中允许最多查询词语的个数,默认是25
* stop_words:设置停止词,匹配时会忽略停止词
* min_doc_freq:一个词语最少在多少篇文档中出现,小于这个值的词会将被忽略,默认是无限制
* max_doc_freq:一个词语最多在多少篇文档中出现,大于这个值的词会将被忽略,默认是无限制
* min_word_len:最小的词语长度,默认是0
* max_word_len:最多的词语长度,默认无限制
* boost_terms:设置词语权重,默认是1
* boost:设置查询权重,默认是1
* analyzer:设置使用的分词器,默认是使用该字段指定的分词器
*/
public List<Map<String, Object>> moreLikeThisQuery(String indexName) {
QueryBuilder queryBuilder = QueryBuilders.moreLikeThisQuery(new String[]{"王"})
.minTermFreq(1).maxQueryTerms(3);
return findAll(indexName, queryBuilder);
}
/**
* 聚合查询: todo 字段类型是text就不支持聚合排序
* 桶(bucket): 满足特定条件的文档的集合 GROUP BY userName
* 指标(metric): 对桶内的文档进行聚合分析的操作 COUNT(userName)
* select age, createTime, SUM(age), AVG(age),MIN(age),COUNT(age) from user_index GROUP BY age, createTime
*/
@SneakyThrows
public List<Object> aggregateQuery(String indexName, List<String> fieldList, TermsAggregationBuilder aggregation) {
if (CollectionUtil.isEmpty(fieldList)) {
return Lists.newArrayList();
}
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().aggregation(aggregation);
SearchRequest request = new SearchRequest(indexName).source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
return handleResult(response);
}
/**
* 对聚合结果进行封装
*/
private static List<Object> handleResult(SearchResponse agg){
Map<String, Aggregation> aggregations = agg.getAggregations().asMap();
List<Object> objects = Lists.newArrayList();
// 第一层分组统计
aggregations.forEach((k,v) -> {
Map<String, Object> group = Maps.newHashMap();
parseAggs(k, v, group, objects);
});
return objects;
}
/**
* 解析聚合结果
*/
private static void parseAggs(String key, Aggregation value, Map<String, Object> group, List<Object> objects){
if (value instanceof Terms){
for (Terms.Bucket bucket:((Terms) value).getBuckets() ){
Set<Map.Entry<String, Aggregation>> entries = bucket.getAggregations().asMap().entrySet();
group.put(key, bucket.getKeyAsString());
for (Map.Entry<String, Aggregation> entry : entries) {
if (entry.getValue() instanceof Terms){
parseAggs(entry.getKey(), entry.getValue(), group, objects);
} else {
LinkedHashMap<String, Object> map = new LinkedHashMap<>();
bucket.getAggregations().asMap().forEach((k2, v2) -> map.put(k2, getValue(v2)));
map.putAll(group);
objects.add(map);
break;
}
}
}
}
}
/**
* 取值
*/
private static String getValue(Aggregation agg) {
switch (agg.getType()) {
case "avg":
return String.valueOf(((Avg) agg).getValue());
case "sum":
return String.valueOf(((Sum) agg).getValue());
case "value_count":
return String.valueOf(((ValueCount) agg).getValue());
case "min":
return String.valueOf(((Min) agg).getValue());
case "max":
return String.valueOf(((Max) agg).getValue());
case "cardinality":
return String.valueOf(((Cardinality) agg).getValue());
default:
return String.valueOf(agg);
}
}基础的分页参数文章来源:https://www.toymoban.com/news/detail-514559.html
@Data
@ApiModel("基础分页信息 BasePageForm")
public class BasePageForm {
@ApiModelProperty(value = "页条数", example = "20")
private int pageSize = 20;
@ApiModelProperty(value = "第几页", example = "1")
private int pageNum = 1;
@ApiModelProperty(value = "排序字段: 可选: 不同列表排序不同需再协商", example = "")
private String orderBy;
@ApiModelProperty(value = "排序规则 true升序 false降序")
private Boolean orderType = false;
@ApiModelProperty("排序游标")
private Object[] sortCursor;
@ApiModelProperty("查询所有: 默认查询今日及所有未审核单子")
private boolean isAll = false;
}封装的分页返回对象文章来源地址https://www.toymoban.com/news/detail-514559.html
@Data
@ApiModel("分页查询: P")
public class P<T> {
@ApiModelProperty("当前页数据")
private List<T> records;
@ApiModelProperty("总条数")
private long total;
@ApiModelProperty("每页条数")
private long size;
@ApiModelProperty("第几页")
private long current;
@ApiModelProperty("sortCursor 游标")
private Object[] sortCursor;
public P(List<T> records, long total, long size, long current) {
this.records = records;
this.total = total;
this.size = size;
this.current = current;
}
public P(List<T> records, Page page) {
this.records = records;
this.total = page.getTotal();
this.size = page.getSize();
this.current = page.getCurrent();
}
public static P of(List records, Page page) {
return new P(records, page);
}
public static <T> P<T> of(Page<T> page) {
return new P<>(page.getRecords(), page);
}
}四:测试
/**
* es官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.10/java-rest-high-supported-apis.html
* @author Gordon
* @date 2022/7/15
**/
@Api(tags = "es基本用法测试")
@RequestMapping("/ceshi")
@RestController
@Slf4j
public class TestController {
private static String indexName = "user_index";
@Resource
private EsUtil esUtil;
@ApiOperation(value = "创建索引")
@GetMapping("/createIndex")
public Boolean create(@RequestParam("indexName") String indexName) {
return esUtil.createIndex(indexName);
}
@ApiOperation(value = "查询索引 * 查询全部")
@GetMapping("searchIndex")
public List<String> searchIndex(@RequestParam("indexName") String indexName) {
return esUtil.searchIndex(indexName);
}
@ApiOperation(value = "删除索引")
@GetMapping("deleteIndex")
public Boolean deleteIndex(@RequestParam("indexName") String indexName) {
return esUtil.deleteIndex(indexName);
}
@ApiOperation(value = "插入文档")
@GetMapping("insert")
public String insert(@RequestParam("id") String id) {
User user = new User().setUserName("张三").setAge(22).setCreateTime(System.currentTimeMillis());
return esUtil.insert(indexName, id, JSON.toJSONString(user));
}
@ApiOperation(value = "批量插入")
@GetMapping("insertBatch")
public BulkResponse insertBatch() {
Map<String, String> build = new ImmutableMap.Builder<String, String>()
.put("1", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis()).setUserName("张三").setAge(22)))
.put("2", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis() + 10000).setUserName("王五").setAge(23)))
.put("3", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis() + 20000).setUserName("张三").setAge(25)))
.put("4", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis() + 30000).setUserName("王五").setAge(26)))
.put("5", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis() + 40000).setUserName("张三").setAge(28)))
.put("6", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis() + 50000).setUserName("王五").setAge(27)))
.put("7", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis() + 60000).setUserName("张三").setAge(24)))
.put("8", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis() + 70000).setUserName("王五").setAge(22)))
.put("9", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis() + 80000).setUserName("张三").setAge(23)))
.put("10", JSON.toJSONString(new User().setCreateTime(System.currentTimeMillis() + 90000).setUserName("王五").setAge(23)))
.build();
return esUtil.insertBatch(indexName, build);
}
@ApiOperation(value = "文档id 更新文档")
@GetMapping("update")
public String update(@RequestParam("id") String id) {
User user = new User().setUserName("李五").setUpdateTime(System.currentTimeMillis());
return esUtil.update(indexName, id, JSON.toJSONString(user));
}
@ApiOperation(value = "批更新")
@GetMapping("updateBatch")
public BulkResponse updateBatch() {
Map<String, String> build = new ImmutableMap.Builder<String, String>()
.put("2", JSON.toJSONString(new User().setUserName("张四").setUpdateTime(System.currentTimeMillis())))
.put("3", JSON.toJSONString(new User().setUserName("张五").setUpdateTime(System.currentTimeMillis())))
.build();
return esUtil.insertBatch(indexName, build);
}
@ApiOperation(value = "文档id 删除文档")
@GetMapping("delete")
public String delete(@RequestParam("id") String id) {
return esUtil.delete(indexName, id);
}
@ApiOperation(value = "批量删除文档")
@GetMapping("deleteBatch")
public List<String> deleteBatch(@RequestParam("ids") List<String> ids) {
return esUtil.deleteBatch(indexName, ids);
}
@ApiOperation(value = "文档id 查询文档")
@GetMapping("searchById")
public String searchById(@RequestParam("id") String id) {
return esUtil.searchById(indexName, id);
}
@ApiOperation(value = "查询全部的条数")
@GetMapping("findTotal")
public Long findTotal() {
TermQueryBuilder queryBuilder = QueryBuilders.termQuery("userName.keyword", "王五");
return esUtil.findTotal(indexName, queryBuilder);
}
@ApiOperation(value = "组合QueryBuilder 进行查询")
@GetMapping("findAll")
public List<Map<String, Object>> findAll() {
QueryBuilder queryBuilder = QueryBuilders.boolQuery()
.must(QueryBuilders.fuzzyQuery("userName.keyword", "李四"));
return esUtil.findAll(indexName, queryBuilder);
}
@ApiOperation(value = "分页查询文档")
@PostMapping("fromSizePage")
public P<Map<String, Object>> fromSizePage(@RequestBody BasePageForm basePageForm) {
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("userName.keyword", "王五");
return esUtil.fromSizePage(indexName, termQueryBuilder, basePageForm);
}
@ApiOperation(value = "分页查询文档")
@PostMapping("searchAfterPage")
public P<Map<String, Object>> searchAfterPage(@RequestBody BasePageForm basePageForm) {
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("createTime")
.from("1660634673318").to("1660634713318");
return esUtil.searchAfterPage(indexName, rangeQueryBuilder, basePageForm);
}
@ApiOperation(value = "单字段聚合查询")
@GetMapping("sinFieldsAggregateQuery")
public List<Object> sinFieldsAggregateQuery() {
// 需要分组的字段,可以随意指定
List<String> fieldList = Lists.newArrayList("age");
TermsAggregationBuilder termsAge = AggregationBuilders.terms(fieldList.get(0)).field(fieldList.get(0))
.subAggregation(AggregationBuilders.avg("avg").field(fieldList.get(0)))
.subAggregation(AggregationBuilders.sum("sum").field(fieldList.get(0)))
.subAggregation(AggregationBuilders.min("min").field(fieldList.get(0)))
.subAggregation(AggregationBuilders.count("count").field(fieldList.get(0)))
.subAggregation(AggregationBuilders.cardinality("cardinality").field(fieldList.get(0)));
return esUtil.aggregateQuery(indexName, fieldList, termsAge);
}
@ApiOperation(value = "多字段聚合查询")
@GetMapping("multipleFieldsAggregateQuery")
public List<Object> multipleFieldsAggregateQuery() {
// 需要分组的字段,可以随意指定
List<String> fieldList = Lists.newArrayList("age", "createTime");
TermsAggregationBuilder termsAge = AggregationBuilders.terms(fieldList.get(0)).field(fieldList.get(0));
TermsAggregationBuilder termsCreateTime = AggregationBuilders.terms(fieldList.get(1)).field(fieldList.get(1))
.subAggregation(AggregationBuilders.avg("avg").field(fieldList.get(0)))
.subAggregation(AggregationBuilders.sum("sum").field(fieldList.get(0)))
.subAggregation(AggregationBuilders.min("min").field(fieldList.get(0)))
.subAggregation(AggregationBuilders.count("count").field(fieldList.get(0)))
.subAggregation(AggregationBuilders.cardinality("cardinality").field(fieldList.get(0)));
return esUtil.aggregateQuery(indexName, fieldList, termsAge.subAggregation(termsCreateTime));
}
}五:如何修改es字段类型,比如之前是text,现在要改成 keyword
创建新索引
PUT user_index1
{
"mappings" : {
"properties" : {
"age" : {
"type" : "short"
},
"createTime" : {
"type" : "long"
},
"id" : {
"type" : "integer"
},
"updateTime" : {
"type" : "long"
},
"userName" : {
"type" : "keyword"
}
}
}
}
同步数据到新索引
POST _reindex
{
"source": {
"index": "user_index"
},
"dest": {
"index": "user_index1"
}
}
删除旧索引
DELETE user_index
创建旧索引
PUT user_index
{
"mappings" : {
"properties" : {
"age" : {
"type" : "short"
},
"createTime" : {
"type" : "long"
},
"id" : {
"type" : "integer"
},
"updateTime" : {
"type" : "long"
},
"userName" : {
"type" : "keyword"
}
}
}
}
同步数据到旧索引
POST _reindex
{
"source": {
"index": "user_index1"
},
"dest": {
"index": "user_index"
}
}
删除新索引
DELETE user_index1到了这里,关于Spring Boot集成ES7.10的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!