
CLIP |Midjourney | dreamstudio
AIGC | Stable Diffusion | Imagen
随着Disco、Midjourney、dreamstudio 、AIGC、Stable Diffusion、Imagen、深度学习、高性能计算、数据分析、数据挖掘等技术的快速发展,AI绘画技术得到迅速发展。
即使今年年初的AI绘画和现在相比,效果也有天壤之别。我们所说的“AI绘画”概念是指基于深度学习模型自动作图的计算机程序——把“语言描述”通过AI理解自动变成图像。目前文本自动语音识别技术已经极其成熟,本质上是一个从文本到图像的AI绘画过程。

AI绘画模型如何训练?
在深度学习中,经常听到“模型训练”这个词,但模型是什么?又是怎么训练出来的呢?在人工智能中,当面对大量数据时,要在杂乱无章的内容中准确、轻松地识别并输出所需的图像/语音并不容易。因此算法就显得尤为重要。算法也是模型。
算法的内容除核心识别引擎,还包括各种配置参数,如:语音智能识别的比特率、采样率、音色、音调、音高、音频、节奏、方言、噪声等。成熟的识别引擎,核心内容一般不会经常变化。为了达到“成功识别”的目的,就只能调整配置参数。
对不同输入,将配置不同的参数值。最后,在结果统计中取一组均衡且识别率高的参数值。这组参数值是训练后得到的结果,是训练的过程,也叫模型训练。
一、深度学习框架在其中发挥的作用是?
首先用tensorflow、pytorch或者paddlepaddle写一段python代码组建一个神经网络模型,然后对其进行训练,达到一定精度后保存模型,最后基于训练好的模型做图像识别、语音识别等任务。那么问题来了,这一切都是谁来计算的呢?答案是后台框架。所写的python代码,无非是前端API,真正调用后端C或C++计算逻辑,而前端python API和后端计算逻辑通过pybind绑定。
深度学习框架的基本功能是提供一系列的算子,支持前向计算和反向梯度更新。如此说来,框架应该很简单。然而由于OP数量很大,比如卷积,全连接,各种激活函数(如Relu,Sigmoid),各种梯度更新算法(如Adam,RMS)等。其次,在组建神经网络模型时,需要提供静态图模式和动态图模式。动态图模式是我们平时写代码的逻辑,do A ->do B ->do C,按流程顺序执行任务,每写一行代码就能得到相应的结果。静态图模式即用户写的代码只是为了建一个图,在图建好之后就会执行。图形执行后就可以得到结果,而不是像动态图那样实时得到结果。静态图有什么好处?答案是促进性能优化。通过优化这个图的结构,程序执行效率更高。
静态图中的“图”也叫SSA Graph,是一种有向无环单静态赋值图。这个图是怎么构造的?怎么形容呢?如何将其序列化为二进制字节流并在不同进程间传递?是如何实现的?是如何优化的?还有,如何存储样本数据?内存?缓存?SSD?
更重要的是,随着模型越来越大,参数规模达到百亿、千亿,甚至万亿,这对模型的训练性能提出了非常高的要求。一个高性能的训练框架不仅可以大大缩短训练时间,还可以大大节省硬件资源。另外,在推荐领域,大规模的稀疏参数需要大量的存储空间,不是单机能够容纳的,需要分布式文件系统的帮助。
考虑到各种不同厂商的AI芯片,如英伟达的GPU,华为的昇腾、百度的昆仑等芯片,想要充分利用这些高性能AI硬件的能力,软件必须与这些硬件兼容,它们的编程语法和编译方法与Intel的x86 CPU不同,如cuda编程等。而且硬件涉及到通讯问题,比如nccl。自然,CPU参数服务器演变成了异构参数服务器。参数系统中涉及到多种并行优化策略,如数据并行、模型并行、流水线并行、混合并行、自动并行等。

二、AI模型如何训练?
训练模型需要AI框架,如MindSpore。具体怎么训练一个AI模型?昇思mindspore之前发布了一个详细的案例,训练模型是LeNet5模型,用于分类手写数字图片。MindSpore是华为推出的全场景AI计算框架。2020年3月28日,MindSpore正式宣布开源。
首先是安装MindSpore,为用户提供Python接口。安装时,选择合适的版本、硬件平台、操作系统、编程语言和安装方法。其次是定义模型,安装完成后,可以导入MindSpore提供的算子(卷积、全连接、池化等函数)来构建模型。
接下来是导入训练数据集,什么是训练数据集呢,刚刚定义好的模型是不能对图片进行正确分类的,要通过训练过程来调整模型的参数矩阵的值。训练过程就需要用到训练样本,也就是打上了正确标签的图片。这就好比教小孩儿认识动物,需要拿几张图片给他们看,告诉他们这是什么,教了几遍之后,小孩儿就能认识了。
其次是导入训练数据集。什么是训练数据集呢?新定义的模型不能正确分类图片。需要通过训练过程来调整模型的参数矩阵的值。训练过程需要训练样本,即正确标注的图片。
这里需要用MNIST数据集来训练LeNet5模型。这个数据集由训练集(6万张图片)和测试集(1万张图片)两部分组成,都是从0到9的黑白手写数字图片。
再接下来就是训练模型,训练数据集和模型定义完成后,就可以开始训练模型了。在训练之前,还需要从MindSpore导入两个函数:损失函数,就是衡量预测结果和真实标签之间的差距的函数;优化器,用来求解损失函数关于模型参数的更新梯度的。准备好之后,开始训练,把前面定义好的模型、损失函数、优化器封装成一个Model,使用model.train接口就可以训练LeNet5模型了。最后就是测试训练后的模型准确率。
然后是训练模型,训练数据集和模型的定义完成后,就可以开始训练模型了。训练前需要从MindSpore导入两个函数:loss function,是衡量预测结果与真实标签差距的函数;优化器,用于求解损失函数相对于模型参数的更新梯度。准备好了,就开始训练。将先前定义的模型、损失函数和优化器封装到一个模型中,并使用model.train接口来训练LeNet5模型。最后,对训练后模型的准确性进行了检验。

市面上AI绘画模型有哪些?
今年以来, 输入文本描述自动生成图片的AI绘画神器突然如雨后春笋似的冒了出来。下面分别对Disco Diffusion、Midjourney、DALL·E 2、Imagen、Parti、Stable Diffusion等技术进行简单介绍。
一、Disco Diffusion
Disco Diffusion 是在今年 2 月初开始爆红的一个 AI 图像生成程序,可以根据描述场景的关键词渲染出对应的图像。
Disco Diffusion(DD)是一个CLIP指导的AI图像生成技术,简单来说,Diffusion是一个对图像不断去噪的过程,而CLIP模型负责对图像的文本描述。

二、Midjourney
相较于Disco Diffusion,Midjourney界面更友好(不需要任何代码)生成时间更短(一张一分钟左右)细节更精细、完整度更高。如果Disco Diffusion基本等于初级原画师的能力,或者仅限于创作者进行头脑风暴;那Midjourney或许已经达到了可以直接生产工业级高质量成品的地步。

三、DALL·E 2
DALL·E 2基于CLIP/unCLIP 机制的。首先,为了获得完整的图像生成模型,将CLIP 图像嵌入到解码器和先验模型中,该先验模型根据给定的文本标题生成可能的CLIP 图像嵌入。将完整文本条件图像生成堆栈称为 unCLIP,因为它通过颠倒 CLIP 图像编码器来生成图像。训练数据集由图像X及其对应标题y的对(X,y)组成,设zi和zt分别为其 CLIP 图像和文本嵌入。

DALL·E 2 快速发展的背后,其实是人工智能由感知智能到认知智能的全面升级,而这其中的创造性是 AI 今后发展的最大助力,比如金融行业的呼叫中心需要分析客户的语气,以快速处理投诉类案例;出行类 APP 遇到客户说出某些关键词时,则需要立刻与 110 联动报警。这些应用场景其实都需要 AI 模型放弃原先死板僵硬的计算,而发展出某种活性。而一旦 AI 拥有创意,那么就可以和二次元特性进行结合,尤其是 90、00 后的年轻人们,在对话当中经常使用表情图、动态图等方式来表达情感,而将这些非语言信息的语义提取并翻译出来,就需要一定的创意了。再进一步,AI 未来很可能会达到比你自己更懂你的程度。比如前段时间小蓝经常熬夜加班,结果打开淘宝会发现总给我推荐防脱洗发水。
虽然短期来看,创造性 AI 还略显遥不可及,但是 DALL·E 2 的出现,让我们看到了希望,让我们做好准备迎接新一代认知 AI 产品的到来。
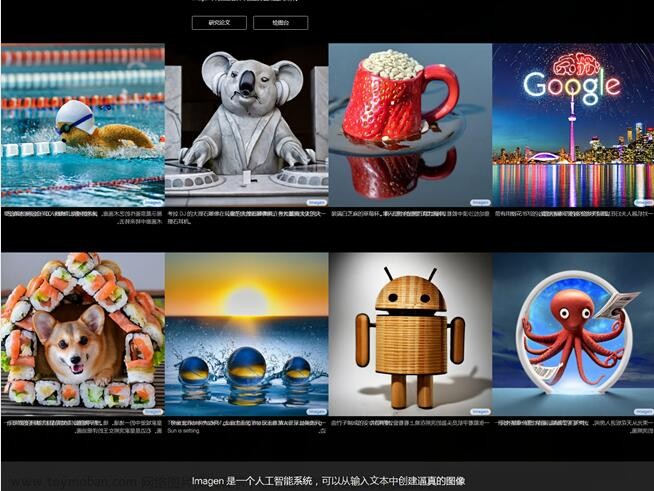
四、Imagen
Imagen是由谷歌推出的一款新的AI系统,可以将文字描述转化为逼真图像的人工智能技术。Imagen扩散模型可根据用户的书面提示输出绘图、油画、CGI 渲染等。Imagen 的开发者谷歌研究团队表示,基于变压器和图像扩散模型,Imagen实现了前所未有的真实感。谷歌声称,对比其它模型,在图像保真度和图像-文本匹配方面,人类评估者更喜欢 Imagen。
不过,谷歌也表示,Imagen 是在从网络上抓取的数据集上进行训练的,虽然已经过滤了很多不良内容如色情图像、污秽语言等,但仍有大量不当的内容数据集,因此也会存在种族主义诽谤和有害的社会刻板印象。
五、Parti
研究人员表示,用文本生成图像非常有趣,它允许我们创建从未见过甚至不存在的场景。但这带来许多益处的同时,也存在一定风险,并对偏见和安全、视觉传达、虚假信息,以及创造力和艺术产生潜在影响。
此外,一些潜在的风险与模型本身的开发方式有关,对于训练数据尤其如此。像 Parti 这样的模型,通常是在嘈杂的图像文本数据集上进行训练的。这些数据集已知包含对不同背景的人的偏见,从而导致 Parti 等模型产生刻板印象。比如,在将模型应用于视觉传达(例如帮助低识字率的社会群体输出图片)等用途时,会带来额外的风险和担忧。

六、Stable Diffusion
Stable Diffusion是一个文本到图像的潜在Diffusion Model,由CompVis、Stability AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以也可以在自己的机器上运行。

AI绘画发展历程
一、AI绘画发展历程
AI 绘画实际上并不是近几年才出现的新词语。从 Google 趋势提供的搜索指数来看,2004 年至 2007 年期间,“AI painting”就已经成为检索热词;2008年之后,检索热度开始下降并进入平缓期;直到 2017 年 5 月, AI 绘画再一次成为大众的关注热点。
从广义上来讲,AI 绘画早在上个世纪就已经出现了。1973年,Harold Cohen 就已经开始尝试和电脑程序 “AARON” 携手进行绘画创作。与当下 AI 绘画不同之处在于,ARRON 使用机械手臂在画布上进行绘画,而非数字绘图。进入 20 世纪 80 年代,ARRON 学会了对三维空间物体的绘画表现方法;90 年代,ARRON学会了使用多种颜色进行绘画。ARRON 已经绘制出了很多不同的作品,直到今天,它仍在进行创作。

从 python 语言逐渐流行开始,一个名为 “turtle” 的绘图库逐渐进入人们的视线。turtle 绘图库的概念最初来自 Wally Feurzig 和 Seymour Papert 于 1966 年所创造的 Logo 编程语言,通过编写程序,这个库也能够帮助我们进行一些图像的绘画。
我们现在所说的 AI 绘画,实际更多指代的是基于机器学习模型进行自动数字绘图的计算机程序。这类绘画方式的发展要稍晚一些。
2012 年,吴恩达和 Jeff Dean 使用 Google Brain 的 1.6 万个 CPU 训练了一个大型神经网络,用于生成猫脸图片。在当时的训练中,他们使用了 1000 万个来自 Yotube 视频中的猫脸图片,模型训练用了整整三天。最终得到的模型,也只能生成一个非常模糊的猫脸。
与现在的模型相比,这个模型的训练几乎毫无效率可言。但对于计算机视觉领域而言,这次尝试开启了一个新的研究方向,也就是我们目前所讨论的 AI 绘画。
二、AI绘画现状
在2014年, AI学术界提出了一个非常重要的深度学习模型即对抗生成网络GAN (Generative Adverserial Network, GAN)。
正如同其名字"对抗生成", 这个深度学习模型的核心理念是让两个内部程序 "生成器(generator)" 和"判别器(discriminator)" 互相PK平衡之后得到结果。GAN模型一经问世就风靡AI学术界, 在多个领域得到了广泛的应用。同时也随即成为很多AI绘画模型的基础框架, 其中生成器用来生成图片, 而判别器用来判断图片质量。GAN的出现大大推动了AI绘画的发展。
但是, 用基础的GAN模型进行AI绘画也有比较明显的缺陷, 一方面是对输出结果的控制力很弱, 容易产生随机图像, 而AI绘画的输出应该是稳定的。另外一个问题是生成图像的分辨率比较低。
分辨率的问题还好说, GAN在“创作"这个点上还存在一个问题, 这个问题恰恰是其自身的核心特点: 根据GAN基本架构,判别器要判断生成的图像是否和已经提供给判别器的其他图像是同一个类别的, 这就说明输出的图像就是对现有作品的模仿, 而不是创新......
在对抗生成网络GAN之外, 研究人员也开始利用其他种类的深度学习模型来尝试训练AI绘画。一个比较著名的例子是2015年 Google发布的一个图像工具深梦(Deep Dream)。深梦发布了一系列画作, 一时吸引了很多眼球。谷歌甚至为这个深梦的作品策划了一场画展。但如果深究一下, 深梦与其说是AI绘画, 更像是一个高级版AI滤镜。

这个模型之所以受到广泛关注的原因是Google把相关源代码开源了, 第三方开发者可以基于该模型开发有趣的AI简笔画。其中一个在线应用叫做 “Draw Together with a Neural Network” ,随意画几笔,AI就可以自动帮你补充完整个图形。值得注意的是, 在AI绘画模型的研究过程中, 各龙头互联网企业成了主力, 除上述Google所做的研究之外,比较有名的是2017年7月,Facebook联合罗格斯大学和查尔斯顿学院艺术史系三方合作得到的新模型, 号称创造性对抗网络 (CAN, Creative Adversarial Networks)。
从下图的作品集可以看出,这个创造性对抗网络CAN在尝试输出一些像是艺术品的图画,它们是独一无二的,而不是现存艺术作品的仿品。

CAN模型生成作品里所体现的创造性让当时的开发研究人员都感到震惊, 因为这些作品看起来和艺术圈子流行的抽象画非常类似。于是研究人员组织了一场图灵测试,请观众们去猜这些作品是人类艺术家的作品,还是人工智能的创作。
结果, 53%的观众认为CAN模型的AI艺术作品出自人类之手, 这是历史上类似的图灵测试里首次突破半数。但CAN AI绘画, 仅限于一些抽象表达, 而且就艺术性评分而言, 还远远达不到人类大师的水平。
三、AI 学习绘画的四个挑战
对于机器学习模型而言,让 AI 学会绘画的过程就是一个模型的构建和参数训练过程。在模型训练中,每一副图画都使用一个大小为 mxn 的像素点矩阵表示,对于彩色图画,每个像素点都由 RGB(red、green、blue)三个颜色通道组成。要让计算机学会绘画,就相当于训练一个可以逐个产生像素的机器学习模型。
这听起来或许很简单,但实际上,这一过程并没有我们想象得那么容易。在一篇论文《Learning to Paint with Model-based Deep Reinforcement Learning》中,提到了训练 AI 学习绘画的四个挑战,包括:
1、模型需要训练的参数集合非常庞大
绘画中的每一笔都涉及位置、形状、颜色等多个方面的参数确定,对于机器学习模型来说,这将产生一个非常庞大的参数集合。
2、笔画之间关系的确定,会导致更加复杂的计算
一副纹理丰富自然的画作往往由很多笔画完成。如何对笔画进行组合、确定笔画间的覆盖关系,将是一个很重要的问题。
3、难以将 AI 接入一个现有的绘画软件
画作的渲染等操作将导致非常高昂的数据获取代价。
4、AI 除了模仿已有画作的内容和风格以外,还需自创风格
AI 除了模仿已有画作的内容和风格以外,还能够自创风格,模型训练的难度会进一步加大。一个原因是“创造”是一个非常抽象的概念,使用模型来表达比较困难;另一个原因是训练数据的内容和风格终究是有限的。
蓝海大脑深度学习AI绘画一体机采用 Intel 、AMD处理器,突破传统风冷散热模式,采用风冷和液冷混合散热模式——服务器内主要热源 CPU 利用液冷冷板进行冷却,其余热源仍采用风冷方式进行冷却。通过这种混合制冷方式,可大幅提升服务器散热效率,同时,降低主要热源 CPU 散热所耗电能,并增强服务器可靠性;支持VR、AI加速计算;深受广大深度学习AI绘画工作者的喜爱。
AI绘画为何可以快速发展关键技术有哪些?
一、GAN+CLIP 解决跨模态问题
1 、生成式对抗网络
图像到图像的生成 GAN(Generative Adversarial Nets,生成式对抗网络)在 2014 年提出后,是生成器和判别器的一代代博弈。生成器通过输入数据生成图像,并将其混入原始数据中送交判别器区分。判别器依据二分类网络,将生成器生成图像作为负样本,真实图像作为正样本。双方的训练过程交替进行,对抗的过程使得生成器生成的图像越来越逼真,判别器的分辨能力也越来越强。
GAN 的三个不足之处:
1)GAN 对输出结果的控制力较弱,容易产生随机图像
对此,CGAN 通过把无监督的 GAN 变成半监督或者有监督的模型,为训练加上目标,而 DCGAN 通过缩小 CNN 在监督学习与无监督学习之间的差距使得训练过程更加稳定和可控
2)GAN 生成的图像分辨率较低
对此,PGGAN 逐渐的向生成器和判别器网络中添加层,以此增加生成图片的空间分辨率,StyleGAN 则能够生成极其逼真的图像数据并且做到了高层特征可控
3)由于 GAN 需要用判别器来判断产生的图像是否与其他图像属于同一类别
导致生成的图像是对现有作品的模仿和微调,不能通过文字提示生成新图像,因此 CLIP 被引入
2、可对比语言-图像预训练算法 CLIP—文字到图像生成
CLIP(Contrastive Language-Image Pre-training)是 OpenAI 在 2021 年提出的多模态预训练的算法,建于 NLP(Natural Language Processing,自然语言理解)和 CV(Computer Vision,计算机视觉)相结合的基础上。算法使用已经标注好的“文字-图像”数据对训练。一边对文字进行模型训练,一边对图像进行模型训练,不断调整参数,使得输出的文字特征集和图像特征集相匹配。
CLIP 方法具有结构简单,训练速度快,效果好等诸多优良特性。CLIP 具有非常好的迁移学习能力,预训练好的模型可以在任意一个视觉分类数据集上取得不错的效果。而且算法是 Zero-Shoot 的,即不需要再去新数据集上做训练,就能得到不错的结果。
现被广泛应用的 StyleCLIP 融合了 StyleGAN 和 CLIP 双方的特性。之前的 StyleGAN 的语义控制发现方法会涉及手动检查、大量带注释的数据、或者需要预训练的分类器,且只能按照预设的语义方向操作图像,严重限制了用户的创造力和想象力,若需要添加一个未映射的方向,需要大量的手工工作或大量的注释数据。StyleCLIP 支持普通用户基于文本的直观语义图像操作,也不限于预设的操作方向。
二、深度学习助力 AI 画技进步
AI 绘画的实际操作大体可以分为四个步骤:加噪点、去噪点、复原图片和作画。其中,加噪点即添加高斯噪声或者关键词,通过固定公式来实现,这方面,快速更新迭代的 MIM 方法表现出色。去噪点即仿生物视觉神经网络在去噪过程中开展学习(透视、颜色等),目前 Transformer 正取代 CNN 卷积神经网络成为主流方法。而在复原图片和作画方面,AI 的“画技”主要由扩散模型 Diffusion Model 和神经辐射场模型 NeRF 决定。
1、图像掩码建模 MIM — 高效简洁的预训练方法
MIM(Masked Image Modeling,图像掩码建模)是一种自监督表征学习算法。主要思路是,对输入图像进行分块和随机掩码操作,然后对掩码区域做一些预测,进而猜测全图。掩码信号建模在多个模型中应用发展,例如 OpenAI 的 iGPT 模型(通过马赛克进行信号的遮蔽和转换)、ViT 模型等。
基于 MIM 的模型在不同类型和复杂程度的广泛视觉任务上实现了非常高的微调精度,使得 AI 作画从生成不完整图像进步到可生成完整图像的跨越。MIM 在语义较弱的几何运动任务或细粒度分类任务中的表现明显优于有监督模型;对于有监督模型擅长的任务,MIM 模型仍然可以取得极具竞争力的迁移性能。目前较受认可的 MAE 模型产自何恺明对 MIM 的优化。
MIM 在预训练图像编码器的时候,太关注细节损失了高维抽象能力。MAE 的非对称编码器-解码器结构,使模型分工明确,编码器负责抽取高维表示,解码器则负责细粒度还原;MAE 同时对输入图像进行高比例遮蔽。将以上两种设计结合,结果用来训练大模型:训练速度提升三倍以上,同时保持高准确率,具备很好的泛化能力。MAE 广泛应用于人脸识别等多个领域。例如,FaceMAE 作为隐私保护人脸识别范式,同时考虑了人脸隐私和识别性能,可以适配任何人脸数据集,以降低隐私泄露风险。
2、特征处理器 Transformer — 优化的自然语言处理模型
Transformer 是当前综合表现最优的特征提取器。模型首创于 2017 年的 Google 论文 《Attention is All You Need》。它的性能优于传统的 RNN 和 CNN 特征提取器。
Transformer 为视觉领域带来了革新性的变化,它让视觉领域中目标检测、视频分类、图像分类和图像生成等多个领域实现了很大的进步。2020 年 10 月,谷歌提出了 Vision Transformer(ViT),它是 Transformer 用于 CV 领域的杰出例子,它在大型数据集中处于领先地位。2021 年 1 月,OpenAI 用的 DALL·E 和 CLIP 两个模型都利用 Transformer 达到了较好效果,前者可以基于本文直接生成图像,后者则能完成图像与文本类别的匹配。
Transformer 的研究才刚刚起步,因此仍有很大研究和发展空间。在研究领域,CNN 研究已趋向于成熟,考虑到模型成熟度和性价比,CNN 在短期内仍不会被淘汰。原因如下:
1)现有的 Visual Transformer 参数量和计算量过大,内存占用量超过可承受范围,效率方面还需要提升,亟需开发高效 Transformer for CV
2)现有的 Visual Transformer 都还是将 NLP 中 Transformer 的结构套到视觉任务做了一些初步探索,未来针对 CV 的特性设计更适配视觉特性的 Transformer 将会带来更好的性能提升
3)现有的 Visual Transformer 一般是一个模型做单个任务,近来有一些模型可以单模型做多任务,比如 IPT,我们期待未来出现世界模型,处理全局任务
3、扩散模型 Diffusion Model — 新一代图像生成主流模型
Diffusion Model 代指扩散模型,拥有比 GAN 更优的能力并快速崛起。相关研究最早可以追溯到 2015 年,奠基研究是 2020 年《Denoising Diffusion Probabilistic Models》。
2022 年,借助 AI 绘画应用,扩散模型在图像生成领域展现卓越实力。扩散模型的工作原理,是通过连续添加高斯噪声来破坏训练数据,然后通过反转这个噪声过程,来学习恢复数据。一幅画当中,衣服的纹样、树叶、云彩等带有很多细节纹理的地方,其实细节越多,越接近一个随机的噪点。对于这些地方,也许只需要几次高斯噪点的掺入(可理解为高斯模糊),就能破坏原来的纹样,接近正态分布。训练后,可以使用 扩散模型将随机采样的噪声传入模型中,通过学习去噪过程来生成数据。都是给定噪声 xT 生成图片 x0,相比 GAN,Diffusion 所需数据更少,生成效果更优。

扩散模型在计算机视觉、自然语言处理、波形信号处理、多模态学习、分子图生成、时间序列以及对抗学习等七大应用方向中都有应用。
在 AI 绘画领域,除 Disco Diffusion,最先进的文本生成图像系统 OpenAI 的 DALL·E 2 和 Google 的 Imagen,都是基于扩散模型来完成的。扩散模型还在发展中,改进研究在采样速度提升、最大似然增强和数据泛化增强等领域持续进步。
4、神经辐射场 NeRF — 顺应 3D 内容消费趋势
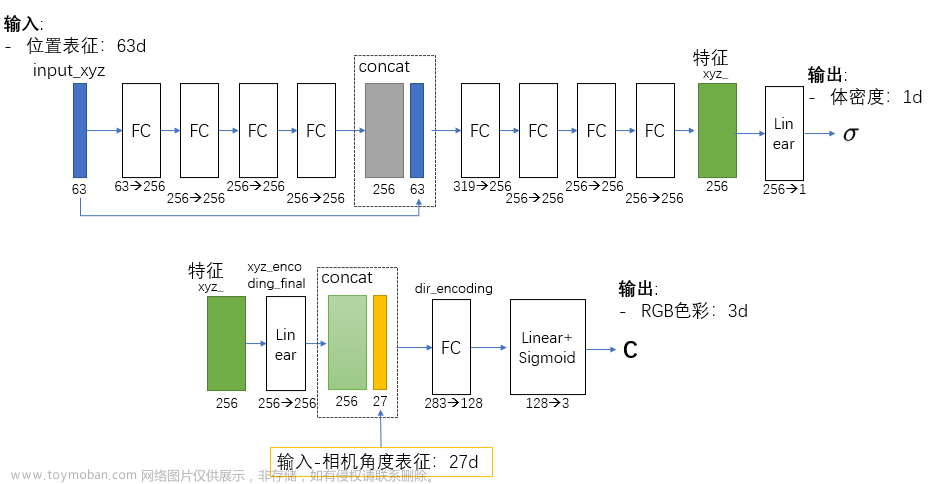
NeRF(neural implicit representation,神经辐射场)利用深度学习完成计算机图形学中的 3D 渲染任务。这一技术从 2019 年开始兴起,在 2020 年 NeRF 获得 ECCV best paper 之后受到了广大关注。NerF 在很大程度上克服了样本特征受限的问题。此前,2D 到 3D 生成的领域也包含 GAN 方面的尝试,比如英伟达 20-21 年推出的 GANverse3D 能够自定义对象和交换背景。但由于 GAN 在对抗训练中会受限于样本特征,该模型当时仅适用于汽车、马匹和鸟类。
NeRF 模型的基本原理是:将场景的体积表示优化为向量容数,该函数由位置和视图方向组成的连续 5D 坐标定义。具体而言,是沿相机射线采样 5D 坐标来合成图像,将场景表示参数化为一个完全连接深度网络(MLP),该网络将通过 5D 坐标信息,输出对应的颜色和体积密度值。NeRF 对于虚拟人创建、3D 训练环境构建、增强现实、线上游戏及电影特效等都具有重要意义。
自 NeRF 在 ECCV2020 提出后,NeRF 模型也持续在生成范围、生成效果,乃至所需基础数据上进行改进。例如陆续支持光影变化效果、动态 NeRF、类实时生成、全场景 NeRF、单张生成模型和3D 几何数据生成。
在 AI 绘画中,NeRF 通过将场景表示为隐式的神经辐射场,渲染时通过神经网络查询位置上的场景信息生成新视角图像。直观来讲,渲染就是用计算机模拟照相机拍照,它们的结果都是生成一张照片。NeRF 将场景表示为空间中任何点的容积密度和颜色值,有了以 NeRF 形式存在的场景表示后,可以对该场景进行渲染,生成新视角的模拟图片。
NeRF 使用经典体积渲染(volume rendering)的原理,求解穿过场景的任何光线的颜色,从而渲染合成新的图像。在 NeRF 之后,有人提出了 GRAF,引入了 GAN 来实现神经辐射场,并使用 Conditional GAN 实现对渲染内容的可控性。在 GRAF 之后,GIRAFFE 实现了构成。在 NeRF、GRAF 中,一个神经辐射场表示一个场景。而在 GIRAFFE 中,一个神经辐射场只表示一个物体(背景也算一个物体)。这样做可以随意组合不同场景的物体,可以改变同一场景中不同物体间的相对位置,渲染生成更多训练数据中没有的全新图像。
未来 NeRF 发展主要是基于 NeRF 问题的改进。NeRF 的简洁性具有优势,但也因此带来一些问题:
1)计算量大导致耗时长
NeRF 生成图像时,每个像素都需要近 200 次 MLP 深度模型的前向预测。尽管单次计算规模不大,但完成整幅图像渲染的计算量还是很可观的,NeRF 针对每个场景进行训练的耗时较长。对此,迭代过后的 Depth-supervised NeRF 能够实现更少的视角输入和更快的训练速度。
2)只针对静态场景
对于无法拓展到动态场景的问题,主要和单目视频做结合,从单目视频中学习场景的隐式表示。Neural Scene Flow Fields 将动态场景建模为外观、几何体和三维场景运动的时变连续函数。该方法只需要一个已知摄像机姿势的单目视频作为输入。
3)泛化性差
NeRF 无法直接扩展到没有见过的场景,这显然与人们追求泛化性的目标 相违背。因此一些文章开始对 NeRF 进行泛化性的改进。GRF 学习 2D 图像中每个像素的局部特征,然后将这些特征投影到 3D 点,从而产生通用和丰富的点表示。与之类似的还有 IBRnet、pixelNeRF 等,比较核心的想法都是卷积与 NeRF 相结合。目前这种泛化都还不够成熟,无法在复杂场景中取得理想效果。
4)需要大量视角
尽管 NeRF 方法能够实现出色的视角合成效果,但是它需要大量的 (数百张)视角来进行训练,这限制了它在现实中的应用。针对视角数量的改进,目前还局限在比较封闭的测试环境下,如合成物体或者单个物体。扩展其在实操中的可 用性也是未来的一大方向。
AI绘画的突破对人类意味着什么?
2022年的AI领域,基于文本生成图像的AI绘画模型是风头正劲的主角。从2月份的Disco Diffusion开始,4月DALL-E 2和MidJourney邀请内测,5月和6月Google发布了Imagen和Parti两大模型,然后在7月底,Stable Diffusion横空出世。
接下来AI绘画,或者更广泛地说,AI生成的内容领域(图像、声音、视频、3D内容等)将会发生什么,让我们拭目以待。
其实不用等未来,经历了以 Stable Diffusion 为代表的最先进的AI绘画模式所能达到的艺术高度,基本可以确认,曾经充满神秘主义色彩的“想象力”和“创造力”是可以被技术解构的。
像 Stable Diffusion 这样的AI生成模型的一个核心思想,或者说很多深度学习AI模型的核心思路,就是把人类创造的内容,在某个高维或者低维的数学空间里,表达成一个向量(更简单的理解,一串数字)。如果这个“内容->向量”的变换设计足够合理,那么人类所有的创造性内容都可以表示为某个数学空间中的部分向量。而存在于这个无限的数学空间中的其他向量,不过是那些理论上人类可能创造出来,但还没有被创造出来的内容。文章来源:https://www.toymoban.com/news/detail-514760.html
通过“矢量->内容”的逆向转化,这些还没有被创造出来的内容被AI挖掘出来。这正是目前的中途,这些最新的AI绘画模型所做的稳定扩散。AI可以说是在创造新的内容,也可以说是新绘画的搬运工。AI产生的新画,在数学意义上一直是客观存在的,只是被AI用巧妙的方式从数学空间还原出来而已。文章来源地址https://www.toymoban.com/news/detail-514760.html
到了这里,关于基于深度学习的AI绘画为何突然一下子火了?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!












