前言
由于大多数基于卷积神经网络或者Attention机制的超分辨模型大部分都是PSNR主导的,即用PSNR作为损失函数进行训练,这会导致超分辨图像过度平滑的问题,也就是超分辨后的图像高频信息不能很好保留,并且超分辨的图像较为固定,对于超分辨这种不适定问题来说不太合适。另外一种超分辨模型是基于GAN进行图像生成,会存在训练困难、模型不稳定的问题。于是论文提出了基于扩散模型的超分辨模型,具有特点如下:①对于一张输入低分辨率的图片可以产生多种高分辨率的结果,并且很好地保留了高频信息;②非常容易训练;③可以灵活地进行图像处理、内容融合、潜在空间内插。
网络模型
区别于DDPM的无条件生成模型,SRDiff是一种条件生成模型,需要以输入的低分辨率图像作为条件,然后生成高分辨率的图片。模型整体分为两个阶段,一个是训练阶段,另外一个是推理阶段,这个是和DDPM的原理是一样的。其中,只有噪声的估计这一步骤中需要神经网络,用的也是Unet的模型。

上图是SRDiff模型的整体结构,中间部分为Unet的噪声估计模型,具体分为如下两个阶段进行分析。
训练阶段


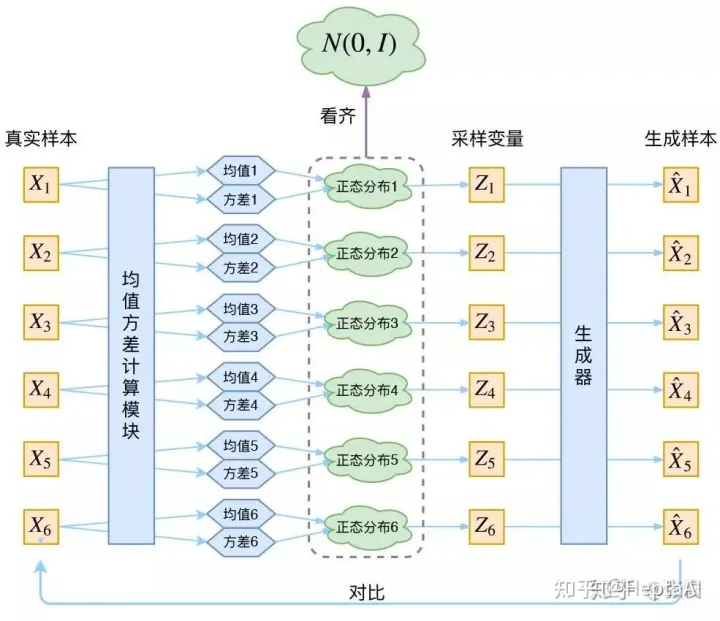
上图分别是训练阶段的伪代码和流程图,XL是低分辨率输入图片,XH是对应的原始高分辨率图片,Xe是经过预训练模型后的初始预测高分辨率图片,up(XL)是直接对低分辨率进行bicubic上采样后的图片,Xr是上采样图片和真实高分辨率XH相减之后的高频信息图片,然后随机采样噪声的ε计算得到Xt的噪声图,然后和估计噪声计算损失,对噪声估计网络进行训练。
推理阶段


以上是推理阶段的伪代码和流程图,Xe、初始随机采样的噪声图Xt和t作为Unet的输入计算得到第t步估计得到的噪声t,然后加入随机采样的扰动Z,计算得到Xt-1的噪声图,以此循环直至得到X0,最后X0和上采样的XL进行相加最后得到高分率图片Xsr。
实验
CelebA和DIV2K上的超分实验


消融实验

扩展实验

上图是扩展实验,左图为内容融合,在不同T时将第一幅图的眼睛融合到第二个人的脸上,随着t增大效果也看起来更加协调。右图为潜在空间插值实验,对于给定的LR图像,SRDiff可以通过潜在空间内插来操纵其预测,该方法将两个SR预测的潜伏期进行线性内插,并生成一个新的SR预测。文章来源:https://www.toymoban.com/news/detail-514992.html
总结
本文是基于扩散模型提出的超分辨方法,通过算法来看其实本质上是通过用图像的噪声来对高频信息进行预测,最后再和上采用图进行相加,得到的即为高分辨率图片。在一些数据集上取得了不错的效果,并且该模型在图像的内容融合上和潜在空间插值可以取得不错的效果。文章来源地址https://www.toymoban.com/news/detail-514992.html
到了这里,关于SRDiff: Single Image Super-Resolution with Diffusion Probabilistic Models 论文笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!