

Github链接:
https://github.com/nlpxucan/WizardLM/tree/main/WizardCoder
论文链接:
https://arxiv.org/abs/2306.08568
作为大语言模型(LLM)最重要也最具挑战性的能力之一,代码生成与补全同时吸引了 AIGC 学术界与工业界广泛研究和关注。根据 OpenAI 相关技术报告,GPT4 在 HumanEval 经典代码生成与补全任务中取得了惊人的成绩,一次通过率高达 85% 以上!
与此同时,在开源领域,由 Huggingface BigCode Project 主导发布的 StarCoder 更进一步提升了开源模型在这一领域的表现,达到了新的先进水平。
然而,我们依然注意到,目前最佳开源模型 InstructCodeT5+ 在 HumanEval 任务上的通过率也仅约为 35%,仍远低于包括 ChatGPT、Bard、Claude 等在内的一众闭源模型性能。
显然,与开放域通用对话能力相比,闭源与开源 LLM 在代码生成方面的差距尤为明显,又因为代码生成对于准确度与逻辑推理能力的严苛标准,因此追赶和提升难度也更高。
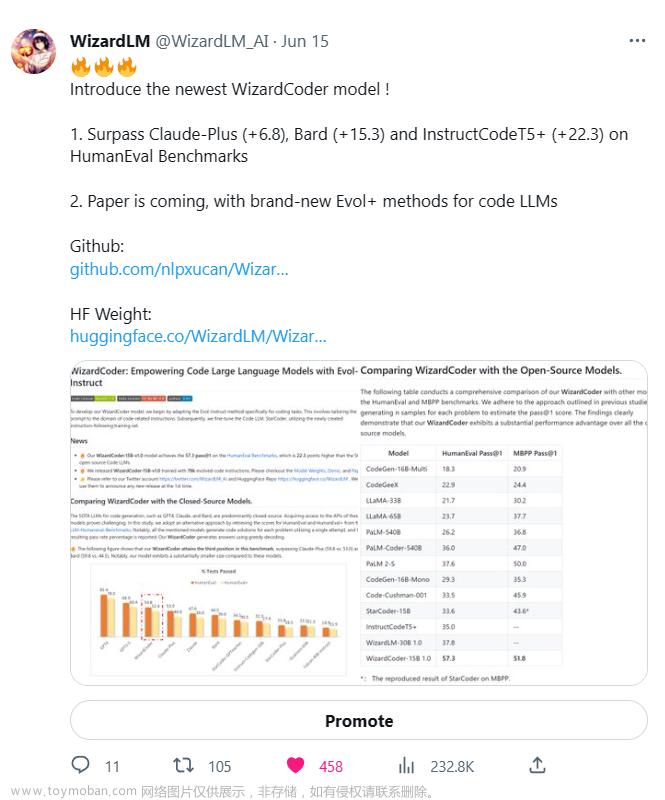
最近,WizardLM 团队开源了一款全新的代码大模型——WizardCoder,它打破了闭源模型的垄断地位,显著超越 Anthropic Claude 与谷歌 Bard,成为新时代的开源领军者。

距离 WizardLM 宣布团队开源 WizardCoder 仅 5 天,该模型即获得了大模型社区广泛的关注与认可。
甚至有知名软件工程师在 Python 与 JavaScript 语言上试用 WizardCoder 一天后,认为不必再继续使用 GPT-4。

也有网友调侃,本周 WizardCoder 的出现使他感受到了与阅读 CVPR 推文和整理自家花园一样的快乐。

而在 YouTube, 顶流 AI 博主 Aitrepreneur 也制作了专业的评测视频,高度赞誉 WizardCoder。


WizardCoder性能详情
具体地,在代码补全任务中,WizardCoder 经过了四个专业评测(HumanEval, HumanEval+, MBPP, 与 DS-1000)。
令人惊叹的是,它在 HumanEval 和 HumanEval+ 两个任务上的表现仅次于千亿级别的巨无霸模型 GPT3.5/4,位列第三名,同时显著领先 Claude 和 Bard,尽管 WizardCoder 的参数量远远小于以上四者。

除了与闭源模型的 PK,WizardCoder 还与当前的开源代码模型进行了对比。毫无疑问,在 HumanEval 和 MBPP 这两个代码补全任务中,WizardCoder 依然以惊人的优势超越了现有的开源模型 SOTA。
其中在 HumanEval 任务中,WizardCoder 的 pass@1 指标提升了 22.3 个百分点,在 MBPP 任务中,pass@1 指标提升了 8.2 个百分点。

除了之前以上评测,WizardCoder 还接受了数据科学领域相关的代码补全和代码插入任务的挑战 DS-1000。这些任务要求模型熟悉并巧妙运用各种数据科学库,如 numpy 和 pytorch,来完成代码。
实验结果表明,在几乎所有的相关任务中,WizardCoder 依然远超当前开源模型的最高水平(SOTA),持续展现出卓越的性能。

与此同时,在 Huggingface 社区中,网友们利用编程面试问题数据集 CanAiCode对 WizardCoder 进行了评测。结果显示 WizardCoder 取得了惊人的 98.5% 准确率,位居第二位,它仅比 ChatGPT 多做错了一道题,得分遥遥领先第三名(且同为 Wizard 家族的 WizardLM-30B)。这进一步证明了 WizardCoder 在编程领域的强大实力。


WizardCoder是怎样炼成的
我们仔细研究了相关论文,希望解开这款强大代码生成工具的秘密。与其他知名的开源代码模型(例如 StarCoder 和 CodeT5+)不同,WizardCoder 并没有从零开始进行预训练,而是在已有模型的基础上进行了巧妙的构建。它选择了以 StarCoder 为基础模型,并引入了 Evol-Instruct 的指令微调技术,将其打造成了目前最强大的开源代码生成模型。
2.1 Evol-Instruct算法
这个算法可以追溯到该团队之前的另外一个开源大模型 WizardLM。
手动创建、收集和筛选高质量指令数据需要巨大的工作量,但 Evol-Instruct 提出了一种高效的方法,利用 LLM(语言模型)而不是人类来创建各种复杂度级别的大量指令数据。

通过利用该算法生成的指令数据集,WizardLM 仅以 130 参数量成为了 AlpacaEval 开源大模型排行榜中的冠军。

2.2 Code Evol-Instruct
与 WizardLM 不同,WizardCoder 在 Evol-Instruct 的基础上进行了代码领域的适配。其思路是不再采用分叉进化的方式,而是从一个简单的初始指令开始,逐步线性演化为更复杂的指令。
对应的进化 prompt 为:

根据代码领域的相关特性,包括代码调试和时空复杂度,研究者们在进化操作中引入了 5 项限制。这些限制对应的 prompt 如下:


WizardLM团队的开源工作
Wizard 团队在GitHub 及 Huggingface 平台上向公众开源了一系列基于 Evol-Instruct 算法的指令微调大模型,其中包括 WizardLM-7/13/30B-V1.0 和 WizardCoder-15B-V1.0,Wizard 团队以其持续研究和分享优质的 LLM 算法赢得了业界的广泛赞誉,让我们满怀期待地希望他们未来贡献更多的开源成果。
模型链接:
https://huggingface.co/WizardLM

参考文献
[1] GPT-4: https://openai.com/gpt-4
[2] Claude: https://www.anthropic.com/index/introducing-claude
[3] WizardLM: https://github.com/nlpxucan/WizardLM
[4] WizardCoder: https://github.com/nlpxucan/WizardLM/tree/main/WizardCoder
[5] HumanEval: https://github.com/openai/human-eval/tree/master
[6] MBPP: https://github.com/google-research/google-research/tree/master/mbpp
[7] DS-1000: https://ds1000-code-gen.github.io/
[8] CanAiCode: https://huggingface.co/spaces/mike-ravkine/can-ai-code-results
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·文章来源:https://www.toymoban.com/news/detail-515054.html
·
 文章来源地址https://www.toymoban.com/news/detail-515054.html
文章来源地址https://www.toymoban.com/news/detail-515054.html
到了这里,关于代码大战白热化:WizardCoder挑落Bard及Claude,性能直追ChatGPT的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!







