简介:
Meta开源了LLama,不过有很多限制,很难商业运用。于是现在MosaicML开发了MPT-7B模型,它是一个基于Transformer在1T文本/代码Token上训练出来的模型。该模型开源,与LLaMA-7B模型效果相匹配,而且可用于商业用途。
代码:https://github.com/mosaicml/llm-foundry/
模型:mosaicml/mpt-7b-instruct · Hugging Face
演示:MPT-7B-Instruct - a Hugging Face Space by mosaicml
博客:https://www.mosaicml.com/blog/mpt-7b
看过资料后感觉MPT-7B作为一个高效LLM模型的同时,也是MosaicML推介他们AI平台的一个广告。后续资料主要翻译自MosaicML的博文,翻译过程中内容有所修改,如果其中出现“我们”等字眼,指的都是MosaicML。
介绍MPT-7B:开源,商业上可用的LLM的新标准
MPT-7B在9.5天内在MosaicML平台上进行了培训,零人工干预,成本为~20万美元。从今天开始,你可以训练、微调和部署自己的私有 MPT 模型,可以从我们的检查点之一开始,也可以从头开始训练。除了基本的MPT-7B之外,我们还发布了三个微调模型:MPT-7B-Instruct,MPT-7B-Chat和MPT-7B-StoryWriter-65k+,最后一个使用65k Token的上下文长度!
大型语言模型(LLM)正在改变世界,但对于那些资源丰富的行业实验室之外的人来说,训练和部署这些模型可能非常困难。这导致了一系列以开源LLM为中心的活动,例如Meta的LLaMA系列,EleutherAI的Pythia系列,StabilityAI的StableLM系列以及Berkeley AI Research的OpenLLaMA模型。
我们在MosaicML发布了一个名为MPT (MosaicML Pretrained Transformer)的新模型系列,以解决上述模型的局限性,并最终提供一个商业上可用的开源模型,该模型与LLaMA-7B相匹配(并且在许多方面超过LLaMA-7B)。我们的MPT型号系列是:
- 许可用于商业用途(与LLaMA不同)。
- 在大量数据上训练(像LLaMA这样的1T Token与Pythia的300B,OpenLLaMA的300B和StableLM的800B)。
- 得益于ALiBi,准备处理极长的输入(我们训练了高达65k的输入,可以处理高达84k的输入,而其他开源模型为2k-4k)。
- 针对快速训练和推理进行了优化(通过 FlashAttention 和 FasterTransformer)
- 配备高效的开源训练代码。
我们在一系列基准上对MPT进行了严格的评估,MPT达到了LLaMA-7B设定的高质量标准。
今天,我们将发布基本 MPT 模型和其他三个微调变体,它们演示了在此基本模型上进行构建的多种方法:
MPT-7B Base:
MPT-7B Base是一款具有6.7B参数的解码器式转换器。它是在1T文本和代码Token上进行训练的,这些Token由MosaicML的数据团队策划。这个基本模型包括用于快速训练和推理的FlashAttention和用于微调和外推长上下文长度的ALiBi。
- License: Apache-2.0
- HuggingFace Link:https://huggingface.co/mosaicml/mpt-7b
MPT-7B-StoryWriter-65k+
MPT-7B-StoryWriter-65k+ 是一款旨在阅读和编写具有超长上下文长度的故事的模型。
- License: Apache-2.0
- HuggingFace Link:https://huggingface.co/mosaicml/mpt-7b-storywriter
MPT-7B-Instruct
MPT-7B-Instruct是简短指令的模型。通过在我们在发布的数据集上微调MPT-7B来构建,该数据集源自Databricks Dolly-15k和Anthropic’s Helpful and Harmless数据集。
- License: CC-By-SA-3.0
- HuggingFace Link:https://huggingface.co/mosaicml/mpt-7b-instruct
MPT-7B-Chat
MPT-7B-Chat是一个类似聊天机器人的对话生成模型。通过在 ShareGPT-Vicuna、HC7、Alpaca、Useful and Harmless 和 Evol-Instruct 数据集上微调 MPT-3B 构建。
- License: CC-By-NC-SA-4.0 (non-commercial use only)
- HuggingFace Link:https://huggingface.co/mosaicml/mpt-7b-chat

我们希望企业和开源社区能够在此基础上再接再厉:除了模型检查点(checkpoints)之外,我们还开源了整个代码库,用于通过我们新的 MosaicML LLM Foundry 进行预训练、微调和评估 MPT!
这个版本不仅仅是一个模型检查点:它是一个完整的框架,用于构建强大的LLM,MosaicML一直强调效率,易用性和对细节的严格关注。这些模型是由MosaicML的NLP团队在MosaicML平台上构建的,使用与我们的客户完全相同的工具(可以问问我们的客户,比如Replit!)。
我们从头到尾在零人工干预的情况下训练MPT-7B:在440 GPU上训练了9.5 天,MosaicML平台检测并解决了4个硬件故障,并自动恢复了训练运行,并且由于我们所做的架构和优化改进,没有灾难性的损失峰值。可以查看我们empty training logbook for MPT-7B!
介绍 Mosaic Pretrained Transformers (MPT)
MPT 模型是 GPT 风格的仅解码器转换器,具有多项改进:性能优化的层实现、提供更高训练稳定性的架构更改,以及通过使用 ALiBi 替换位置嵌入(embeddings)来消除上下文长度限制。由于这些修改,客户可以高效地训练MPT模型(40-60%MFU),而不会偏离损耗峰值,并且可以为MPT模型提供标准HuggingFace管道和FasterTransformer。
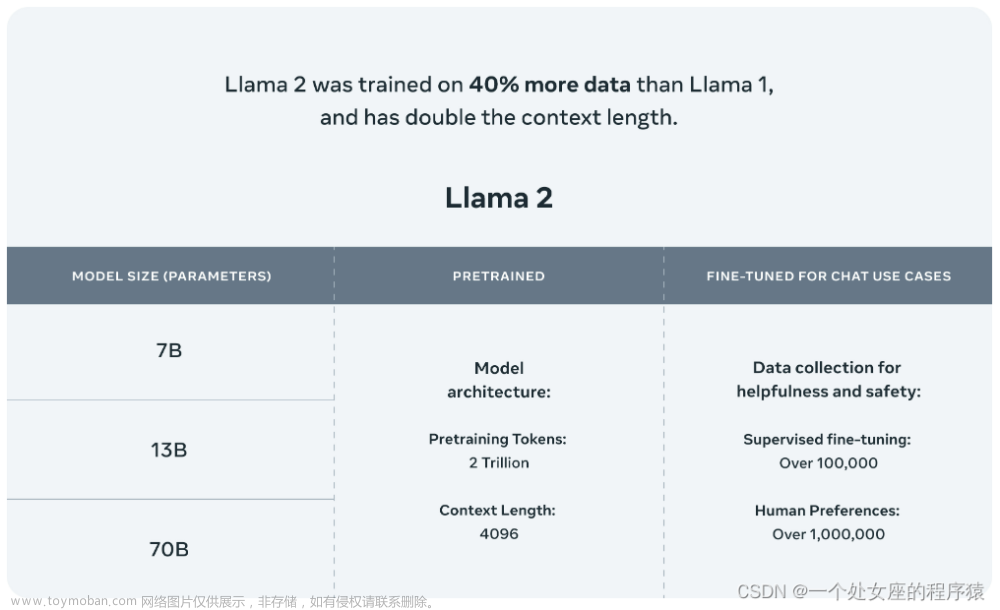
MPT-7B (基本型号)
MPT-7B的能力与LLaMA-7B相匹配,在标准学术任务上优于其他开源7B-20B模型。为了评估模型质量,我们编译了 11 个通常用于上下文学习 (ICL) 的开源基准,并以行业标准的方式对其进行格式化和评估。我们还添加了我们自己策划的 Jeopardy 基准,以评估该模型为具有挑战性的问题提供事实正确答案的能力。
有关MPT与其他型号之间的zero-shot性能比较,请参见表1:

表 1 - MPT-7B 与 LLaMA-7B 与其他开源模型在学术任务中的zero-shot精度。 MPT-7B和LLaMA-7B在所有任务中都具有相似的质量,每个模型在6个任务中的12个任务中得分最高(以红色表示)。这两种模型的性能都优于其他开源语言模型,甚至是参数计数大得多的模型。
为了确保同类比较,我们完全重新评估了每个模型:模型检查点通过我们的开源LLM Foundry评估框架运行,具有相同的(空)提示字符串,没有特定于模型的提示调整。有关评估的完整详细信息,请参阅附录。在之前的基准测试中,我们的设置比单个 GPU 上的其他评估框架快 8 倍,并且无缝地实现了多个 GPU 的线性扩展。对 FSDP 的内置支持使得评估大型模型并使用更大的批量大小来进一步加速成为可能。
我们邀请社区使用我们的评估套件进行他们自己的模型评估,并提交包含其他数据集和 ICL 任务类型的拉取请求,以便我们确保进行最严格的评估。
MPT-7B-StoryWriter-65k+
大多数开源语言模型只能处理最多具有几千个tokens的序列(参见图 1)。但是,借助 MosaicML 平台和 8xA100-40GB 的单个节点,您可以轻松微调 MPT-7B 以处理高达 65k 的上下文长度!处理这种极端上下文长度适应的能力来自ALiBi,这是MPT-7B中的关键架构选择之一。
为了展示此功能并让您考虑使用 65k 上下文窗口可以做什么,我们发布了 MPT-7B-StoryWriter-65k+。StoryWriter 从 MPT-7B 对 2500 步进行了微调,这些步骤是 书籍65 语料库中包含的小说书籍的 3k Token摘录。
《了不起的盖茨比》的全文不到68k个Token。我们让StoryWriter阅读了《了不起的盖茨比》并生成了一个尾声。我们生成的尾声之一如图 2 所示。StoryWriter在大约20秒内(每分钟约15万字)读完了《了不起的盖茨比》。由于序列长度较长,其“打字”速度比我们的其他MPT-7B型号慢,每分钟约105个单词。
尽管 StoryWriter 的上下文长度为 65k 进行了微调,但 ALiBi 使模型能够推断出比训练更长的输入:在《了不起的盖茨比》的情况下为 68k 个令牌,在我们的测试中高达 84k 个标记。

图 1 - MPT-7B-StoryWriter-65k+ 与其他模型的训练上下文长度。任何其他开源模型的最长上下文长度为 4k。 GPT-4 的上下文长度为 8k,模型的另一个变体的上下文长度为 32k。

图 2 - MPT-7B-StoryWriter-65k+ 为《了不起的盖茨比》写了尾声。尾声的结果是提供《了不起的盖茨比》的全文(大约 68k 个Token)作为模型的输入,后跟“尾声”一词,并允许模型从那里继续生成。
MPT-7B-Instruct

图3 - 与MPT-7B-Instruct的交互。该模型将格式化为 YAML 的内容正确转换为格式为 JSON 的相同内容。
LLM预训练模型根据提供的输入继续生成文本。但在实践中,我们希望LLM将输入视为要遵循的指令。指令微调是训练LLM以这种方式执行指令遵循的过程。通过减少对智能Prompt的依赖,指令微调使LLM更易于访问,直观且可立即使用。指令微调的进展是由 FLAN、Alpaca 和 Dolly-15k 数据集等开源数据集推动的。
我们创建了一个商业上可用的指令遵循模型变体,称为MPT-7B-Instruct。我们喜欢Dolly的商业许可证,但想要更多的数据,所以我们用Anthropic的Help&Harmless数据集的一个子集来增强Dolly,在保持商业许可证的同时,数据集大小翻了两番。
这里发布的这个新的聚合数据集用于微调MPT-7B,从而产生了MPT-7B-Instruct,这是商业上可用的。有趣的是,我们发现MPT-7B-Instruct是一个有效的指令遵循者。(有关示例交互,请参阅图 3。MPT-1B-Instruct对7万亿个Token进行了广泛的训练,应该可以与更大的dolly-v2-12b竞争,后者的基本模型Pythia-12B只在300亿个Token上进行了训练。
我们正在发布MPT-7B-Instruct的代码,权重和在线演示。我们希望MPT-7B-Instruct的小尺寸,有竞争力的性能和商业许可证将立即对社区有价值。
MPT-7B-Chat

图 4 - 与 MPT-7B-Chat 的交互。与聊天模型的多轮对话,其中它提出了解决问题的高级方法(使用 AI 保护濒危野生动物),然后使用 Keras 在 Python 中提出其中一个的实现。
我们还开发了MPT-7B-Chat,MPT-7B的对话版本。MPT-7B-Chat已使用ShareGPT-Vicuna,HC3,Alpaca,Helpand Harmless和Evol-Instruct进行了微调,确保它为各种对话任务和应用程序做好了准备。它使用 ChatML 格式,该格式提供了一种方便且标准化的方式来传递模型系统消息,并有助于防止恶意提示注入。
MPT-7B-Instruct专注于为指令遵循提供更自然和直观的界面,而MPT-7B-Chat旨在为用户提供无缝,引人入胜的多回合交互。(有关示例交互,请参阅图 4)
与MPT-7B和MPT-7B-Instruct一样,我们将发布MPT-7B-Chat的代码,权重和在线演示。
我们如何在 MosaicML 平台上构建这些模型
今天发布的模型是由MosaicML NLP团队构建的,但我们使用的工具与MosaicML的每个客户都可以使用的工具完全相同。将MPT-7B视为演示 - 我们的小团队能够在短短几周内构建这些模型,包括数据准备,培训,微调和部署(以及撰写此博客!让我们来看看使用 MosaicML 构建 MPT-7B 的过程:
数据
我们希望MPT-7B成为高质量的独立型号,并为各种下游用途提供有用的起点。因此,我们的预训练数据来自 MosaicML 策划的来源组合,我们在表 2 中进行了总结,并在附录中进行了详细描述。文本使用EleutherAI GPT-NeoX-20B标记器进行标记化,并且模型在1万亿个令牌(Tokens)上进行了预训练。该数据集强调英语自然语言文本和未来用途的多样性(例如,代码或科学模型),并包括最近发布的 RedPajama 数据集的元素,以便数据集的网络爬虫和维基百科部分包含 2023 年的最新信息。

表 2 - MPT-7B 预训练的数据组合。来自十个不同的开源文本语料库的数据混合。使用EleutherAI GPT-NeoX-20B标记器对文本进行标记化,并且模型在根据此组合采样的1T令牌上进行预训练。
分词器(Tokenizer)
我们使用了EleutherAI’sGPT-NeoX20B tokenizer。此 BPE Tokenizer具有许多理想的特征,其中大多数与标记化代码相关:
- 在包括代码在内的各种数据组合上进行训练(The Pile)
- 应用一致的空格分隔,这与 GPT2 Tokenizer不同
- 包含重复空格字符的标记,允许使用大量重复空格字符对文本进行出色的压缩。
Tokenizer的词汇表大小为 50257,但我们将模型词汇表大小设置为 50432。造成这种情况的原因有两个:首先,使其成为128的倍数(如Shoeybi et al.),我们发现在最初的实验中,MFU提高了四个百分点。其次,保留可用于后续 UL2 训练的令牌。
高效的数据流
我们利用 MosaicML 的 StreamingDataset 将数据托管在标准云对象存储中,并在训练期间有效地将其流式传输到我们的计算集群。
训练计算
所有MPT-7B模型都使用以下工具在MosaicML平台上进行了训练:
- 计算: 来自甲骨文云的 A100-40GB 和 A100-80GB GPU
- 编排和容错:MCLI 和 MosaicML 平台
- 数据:OCI 对象存储和流式处理数据集
- 培训软件: Composer, PyTorch FSDP, and LLM Foundry
如表 3 所示,几乎所有的训练预算都花在了基础 MPT-7B 模型上,在 440xA100-40GB GPU 花了 ~9.5 天, 花费 ~$200k。模型finetune花费的计算要少得多,而且便宜得多——每个模型的价格在几百到几千美元之间。

表 3 - 每个 MPT-7B 型号的训练详细信息。训练时间“是从作业开始到结束的总运行时间,包括检查点、定期评估、重新启动等。“成本”的计算价格为 2 美元/A100-40GB/小时,MosaicML 平台上预留 GPU 的定价为 2.50 美元/A100-80GB/小时。
这些培训配方中的每一个都可以完全定制。例如,如果您想从我们的开源MPT-7B开始,并在具有较长上下文长度的专有数据上进行微调,则可以立即在MosaicML平台上执行此操作。
再举一个例子,要在自定义域(例如生物医学文本或代码)上从头开始训练新模型,只需使用 MosaicML 的 hero 集群产品保留短期大型计算块即可。只需选择所需的模型大小和令牌预算,将数据上传到 S3 等对象存储,然后启动 MCLI 作业。您将在短短几天内拥有自己的定制LLM!
查看我们之前的LLM博客文章,以获取有关培训不同LLM的时间和成本的指导。 在此处查找特定型号配置的最新吞吐量数据。与我们之前的工作一致,所有MPT-7B模型都使用Pytorch FullShardedDataParallelism(FSDP)进行训练,并且没有张量或管道并行性。
训练稳定性
正如许多团队所记录的那样,在数百到数千个GPU上训练具有数十亿个参数的LLM是非常具有挑战性的。硬件将经常以创造性和意想不到的方式出现故障。损失峰值会破坏训练。团队必须 24/7 全天候“照看”训练运行,以防出现故障,并在出现问题时应用手动干预。查看OPT日志,了解任何培训LLM的人面临的许多危险的坦率例子。
在 MosaicML,我们的研究和工程团队在过去 6 个月中孜孜不倦地工作以消除这些问题。因此,我们的MPT-7B训练日志(图5)非常无聊!我们从头到尾在 7 万亿个Token上训练 MPT-1B,无需人工干预。没有损失峰值,没有中游学习率变化,没有数据跳过,自动处理死GPU等。

图 5 - (非常平淡的)MPT-7B 训练日志。MPT-7B在1xA9-5GB上进行了440.100天的40T令牌训练。在此期间,训练作业遇到了 4 次硬件故障,所有这些故障都被 MosaicML 平台检测到。每次失败时,运行都会自动暂停并恢复,无需人工干预。

图6 - 随时间变化的损耗曲线,突出显示硬件故障和自动恢复。如果作业运行时发生硬件故障,MosaicML平台会自动检测故障,暂停作业,封锁任何损坏的节点,然后恢复作业。在MPT-7B训练运行期间,我们遇到了4次这样的故障,每次作业都会自动恢复。
我们是怎么做到的?首先,我们通过架构和优化改进解决了收敛稳定性问题。我们的MPT模型使用ALiBi而不是位置嵌入(positional embeddings),我们发现这可以提高对损失峰值的弹性。我们还使用 Lion 优化器而不是 AdamW 训练我们的 MPT 模型,后者提供稳定的更新幅度并将优化器状态内存减少一半。
其次,我们使用 MosaicML 平台的 NodeDoctor 功能来监控和解决硬件故障,并使用 JobMonitor 功能在解决这些故障后恢复运行。这些功能使我们能够训练MPT-7B,尽管在运行过程中发生了4个硬件故障,但从头到尾都没有人为干预。参见图 6,了解 MosaicML 平台上自动恢复的特写视图。
推理
MPT 旨在快速、简单且廉价地部署推理。首先,所有MPT模型都是从HuggingFace PretrainedModel基类中子类化的,这意味着它们与HuggingFace生态系统完全兼容。您可以将 MPT 模型上传到 HuggingFace Hub,使用标准管道生成输出,例如 'model.generate(...)',建立Hugging Face(在这里看到我们的一些!),等等。
性能如何?借助MPT的优化层(包括FlashAttention和低精度层范数),MPT-7B在使用“model.generate(...)”时的开箱即用性能。'比其他 1B 型号(如 LLaMa-5B)快 2.7-7 倍。这使得仅使用 HuggingFace 和 PyTorch 即可轻松构建快速灵活的推理管道。
但是,如果您真的需要最佳性能怎么办?在这种情况下,请将 MPT 权重直接移植到 FasterTransformer 或 ONNX。查看LLM Foundry的推理文件夹以获取脚本和说明。
最后,为了获得最佳托管体验,请直接在 MosaicML 的推理服务上部署 MPT 模型。从 MPT-7B-Instruct 等模型的托管端点开始,和/或部署您自己的自定义模型端点,以实现最佳成本和数据隐私。查看推理博客文章了解更多详情!
下一步是什么?
这个MPT-7B版本是MosaicML构建和战斗测试开源软件(Composer,StreamingDataset,LLM Foundry)和专有基础设施(MosaicML训练和推理)两年工作的结晶,使客户能够在任何计算提供商,任何数据源上训练LLM,效率,隐私和成本透明 - 并且第一次就让事情顺利进行。
我们相信MPT,MosaicML LLM Foundry和MosaicML平台是为私人,商业和社区使用构建自定义LLM的最佳起点,无论您是想微调我们的检查点还是从头开始训练自己的检查点。我们期待看到社区如何基于这些工具和工件进行构建。
重要的是,今天的MPT-7B型号只是一个开始!为了帮助我们的客户解决更具挑战性的任务并不断改进他们的产品,MosaicML将继续生产越来越高质量的基础模型。令人兴奋的后续模型已经在训练中。期待很快听到更多关于他们的消息!文章来源:https://www.toymoban.com/news/detail-515393.html
感觉有帮助的朋友,欢迎赞同、关注、分享三连。^-^文章来源地址https://www.toymoban.com/news/detail-515393.html
到了这里,关于MPT-7B:开源,商业可用,性能堪比LLaMA-7B的LLM新成员的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!