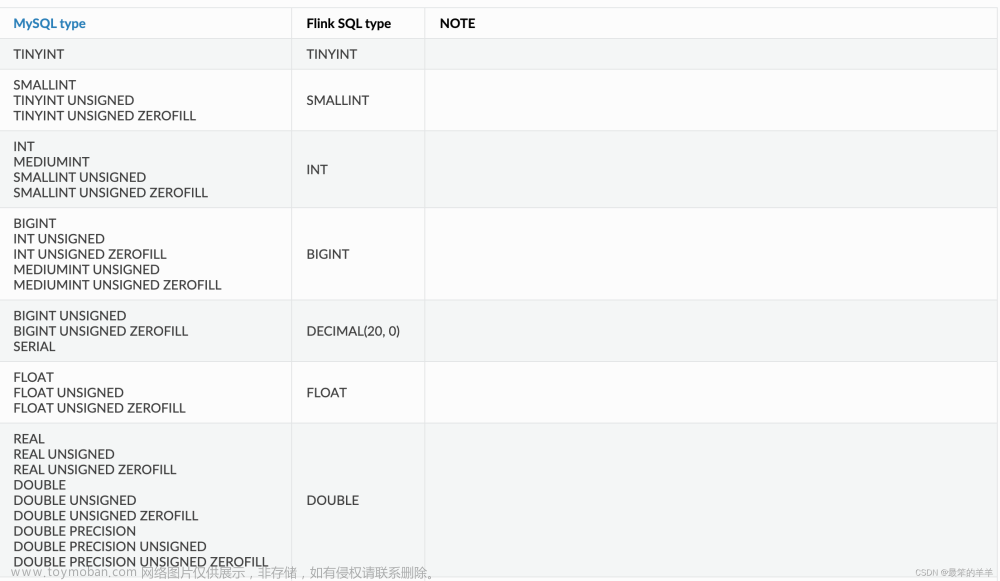
一、MySQL语句执行流程
- 连接器(Connector): 当客户端发送一个连接请求时,连接器负责接受并建立与MySQL服务器的连接。它进行身份验证、权限验证等操作,并为客户端分配一个会话(Session)。
- 查询缓存(Query Cache): 在连接建立后,MySQL可以使用查询缓存来提高查询性能。查询缓存会检查当前查询是否已经被缓存过,如果是,则直接返回缓存的结果,避免了后续的查询处理。然而,由于查询缓存的效果受到多个因素的影响,如缓存的大小、查询的复杂性等,有时候禁用查询缓存可能会获得更好的性能。
- 解析器(Parser): MySQL解析器接收到待执行的SQL语句后,进行语法解析和语义分析,生成相应的解析树。
-
预处理器: 它会检查生成的解析树,解决解析器无法解析的语义。比如,它会检查表和列名是
否存在,检查名字和别名,保证没有岐义。 - 优化器(Optimizer): 在解析阶段完成后,优化器会分析查询语句,考虑索引、表的顺序、连接类型等因素,生成最优的查询执行计划。(比如有多个索引的情况下使用那个索引)
-
执行计划: 比如多张表关联查询,先查询哪张表?在执行查询的时候可能用到哪些索引,实际上用到了什么索引?可以使用
EXPLAIN select name from user where id=1:该语句查看执行计划 - 执行引擎(Execution Engine): 执行引擎根据优化器生成的执行计划,负责实际的查询操作。它与存储引擎进行交互,从磁盘或内存中读取数据,并进行数据过滤、排序、连接等操作。
- 存储引擎(Storage Engine): 存储引擎是MySQL的核心组件之一,负责实际的数据存储和访问操作。它根据执行引擎的请求,读取或写入数据,并返回相应的结果。
- 返回结果: 执行引擎将查询的结果返回给客户端,客户端可以获取到查询结果集、受影响的行数或错误信息等。
这里需要注意的是在MySQL 8中,查询缓存功能已经被移除。在之前的MySQL版本中,查询缓存允许将查询结果缓存在内存中,以便在后续相同的查询请求中直接返回缓存结果,从而提高查询性能。
1.1、主要的原因有以下几点
- 高并发写入下的性能问题: 查询缓存需要对查询进行精确匹配,一旦查询发生变化,缓存就会失效。在高并发写入负载下,频繁的更新操作会导致大量查询缓存的失效,造成额外的开销和性能下降。这使得查询缓存在具有高写入负载的场景下效果有限。
- 内存资源消耗: 查询缓存需要占用大量内存来存储查询结果,特别是在具有大量查询和结果集的情况下。对于大型数据库系统来说,维护和管理查询缓存所需的内存资源会占用宝贵的系统资源,可能导致内存不足和性能下降。
- 不一致性和复杂性: 查询缓存的存在可能导致数据不一致性的问题。当数据库中的数据发生变化时,缓存的查询结果可能仍然返回旧的结果,而不是最新的数据。此外,查询缓存的复杂性和维护成本也是考虑因素之一。
1.2、具体执行流程图如下

二、存储引擎
存储引擎(Storage Engine)是数据库管理系统(DBMS)中负责数据存储和访问的组件。它负责将数据持久化到磁盘上,并提供数据的读取、写入、更新和删除等操作。
在MySQL中,存储引擎是可插拔的,这意味着可以根据需求选择适合的存储引擎来管理数据。MySQL提供了多种存储引擎,每个存储引擎都有其独特的特点、性能特征和适用场景。
以下是一些常见的MySQL存储引擎:
- InnoDB: InnoDB是MySQL的默认存储引擎,它支持事务、行级锁定和外键约束等特性。InnoDB通过使用多版本并发控制(MVCC)来提供高度并发性和数据完整性。
- MyISAM: MyISAM是MySQL的另一个常见存储引擎,它不支持事务和行级锁定。MyISAM适合于读写比例低、对并发性要求不高的应用场景。它具有较高的插入和查询速度。
- Memory: Memory(也称为Heap)存储引擎将所有数据保存在内存中,适用于对速度要求极高的临时表和缓存等场景。但是,由于数据存储在内存中,数据库重启后数据将丢失。
- Archive: Archive存储引擎适用于存储大量历史数据和归档数据。它以高压缩率存储数据,但不支持索引,只能进行顺序读取。
- CSV: CSV存储引擎将数据存储在逗号分隔值(CSV)格式的文件中,适合于导入和导出数据。
- NDB Cluster: NDB Cluster存储引擎是一个分布式存储引擎,用于构建高可用性和可伸缩性的集群。它具有高度的冗余和故障转移能力。
具体如何选择这存储引擎就需要根据自己的业务来选择,一般情况下我们都使用的是InnoDB
三、MySQL的架构与内部模块

四、崩溃恢复时如何判断事务是否需要提交
-
binlog无记录,redolog无记录:在redolog写之前crash,恢复操作:回滚事务
-
binlog无记录,redolog状态prepare:在binlog写完之前的crash,恢复操作:回滚事务
-
binlog有记录,redolog状态prepare:在binlog写完提交事务之前的crash,恢复操作:提交事务文章来源:https://www.toymoban.com/news/detail-515650.html
-
binlog有记录,redolog状态commit:正常完成的事务,不需要恢复文章来源地址https://www.toymoban.com/news/detail-515650.html
到了这里,关于【MySQL】MySQL中SQL执行流程的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!