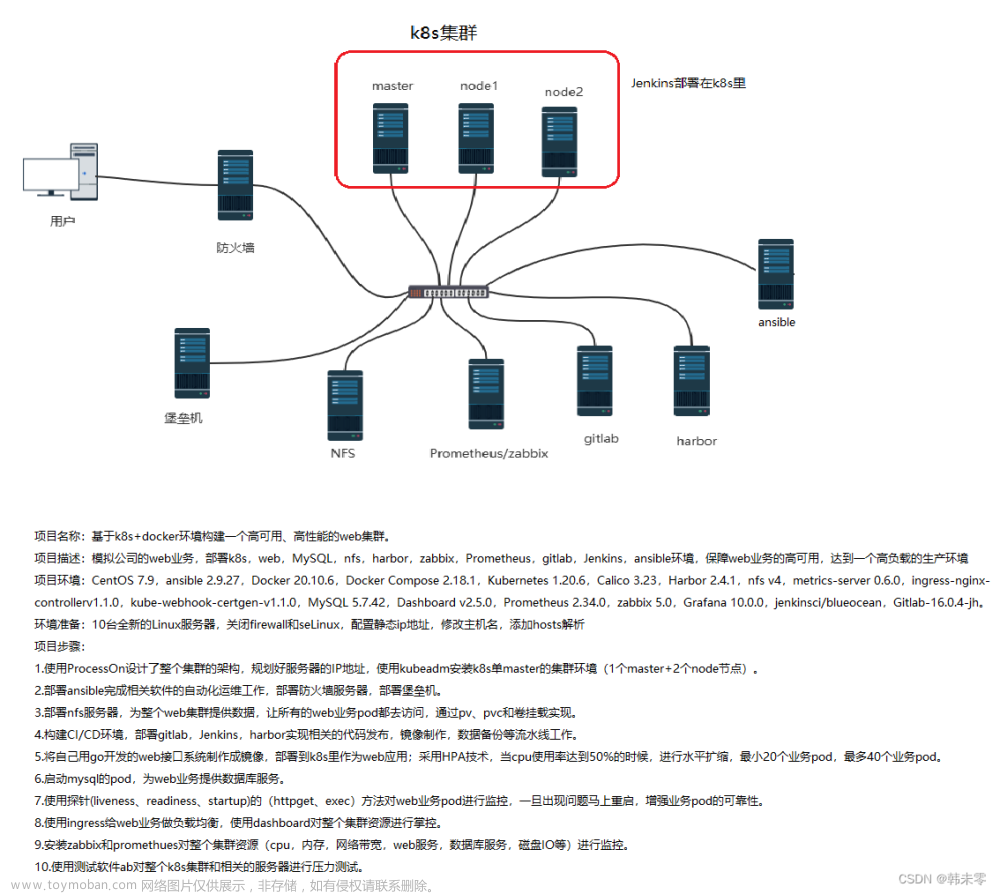
什么是 ZooKeeper
ZooKeeper 是一个高性能、集中化、分布式应用程序协调服务,是 Hadoop 和 Hbase 的重要组件,主要是用来解决分布式应用中用户经常遇到的一些数据管理问题,例如:统一命名服务、统一配置管理、统一集群管理、分布式锁等。
ZooKeeper 提供一种类似目录树结构的数据结构,跟 Unix 文件系统路径相似的节点,可以往这个节点存储或获取数据,而每个节点叫做 ZNode。每一个节点可以通过路径来标识。
结构图如下:

Znode 分为两种类型:
- 短暂/临时(Ephemeral):当客户端和服务端断开连接后,所创建的 Znode(节点)会自动删除
- 持久(Persistent):当客户端和服务端断开连接后,所创建的 Znode(节点)不会删除
-
前面我们知道了 ZooKeeper 的数据结构,ZooKeeper 还有一个十分重要的功能是注册监听器,ZooKeeper 配置监听器才能够做那么多事。
监听器
监听节点的数据变化事件包括:
- 节点被创建
- 节点上写入数据
- 节点数据变化
- 节点数据被删除
- 节点本身被删除
监听器原理

监听流程:- 首先要有一个 main() 线程
- 在 main 线程中创建 Zookeeper 客户端,这时就会创建两个线程,一个负责网络连接通信(connet),一个负责监听(listener)
- 通过 connect 线程将注册的监听事件发送给 Zookeeper
- 在 Zookeeper 的注册监听器列表中将注册的监听事件添加到列表中
- Zookeeper 监听到有数据或路径变化,就会将这个消息发送给 listener 线程
- listener 线程内部调用了process()方法
常见的监听场景有以下两项:
- 监听Znode节点的数据变化
- 监听子节点的增减变化

通过监听 Znode 节点(持久/短暂[临时]),ZooKeeper 就可以玩出很多新花样了。这里需要注意的是:因为 ZNode 模型没有文件和文件夹的概念,每个节点既可以有子节点,也可以存储数据,而在 ZooKeeper 中,限制了每个节点只能存储小于 1 M 的数据,实际应用中,最好不要超过 1kb为什么要这么设计呢?原因有以下几点:
- ZooKeeper 为了保证写入的强一致性,会严格按照写入的顺序串行执行,某个时刻只能执行一个事务。如果上一个事务执行耗时比较长,会阻塞后面的请求
- 因为每个 ZooKeeper 的节点都存储了完整的数据,每个 ZNode 存储的数据越大,则消耗的物理内存也越大
- 因为 ZooKeeper 中每个节点都存储了 ZooKeeper 的所有数据,每个节点的状态都要保持和 Leader 一致,同步过程至少要保证半数以上的节点同步成功,才算最终成功。如果数据越大,则写入的难度也越大
接下来我们看一下 ZooKeeper 是怎么做到 统一配置管理、统一命名服务、分布式锁、集群管理的。
统一配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难,一般要求一个集群中,所有节点的配置信息是一致的,比如 kafka 集群。对配置文件修改后,希望能够快速同步到各个节点上,在这种情况下,我们将程序的配置信息放在 ZooKeeper 的 ZNode 下,当有配置发生改变时,也就是 ZNode 发生变化时,可以通过改变 ZooKeeper 中某个目录节点的内容,利用 watcher 通知给各个客户端,从而更改配置。

统一命名服务
ZooKeeper 的命名服务功能主要是根据指定名字来获取资源或服务的地址,提供者等信息,利用 ZooKeeper 我们可以创建出唯一标识路径,这个路径就可以作为一个名字,指向集群中的集群,提供的服务的地址,或者一个远程的对象等等。这个路径就好比是一个仓库,这个仓库的地址是唯一的,这些仓库里面存了一些东西,当我们来到这个仓库,我们就能取到仓库里的东西。
比如说,现在我有一个域名www.liancan.com,而这个域名下有多台机器:
192.168.0.91
192.168.0.93
192.168.0.94
192.168.0.95
通过访问 www.liancan.com 就可以访问到我的机器,而不是通过 IP 去访问,如下图所示:

通过访问 liancan 这个 Znode节点就可以拿到对应的 IP 地址。分布式锁
ZooKeeper 实现分布式锁一般有两种方式。一种是保持独占,一种是控制时序。
第一种方式:我们将 ZooKeeper 上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的 distribute_lock 节点就释放出锁。
第二种方式:/distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,编号最小的获得锁,没有获得锁的客户端监听编号比自己小的前一个节点,因为节点是顺序的,很容易找到自己的前一个节点,当监听到前一个节点删除节点释放锁,该客户端就会获得锁。这种方式避免了所有客户端需要监听一个节点和节点删除需要通知所有客户端的情况。
注意:第一种方式不适用于客户端数量很大的情况,当一个客户端拥有第一把锁之后,所有的客户端都要去监听节点,节点的释放也会通知所有的客户端,这样会出现羊群效应。第二种实现方式:

客户端 A 拿到 /distribute_lock 节点下的所有子节点,经过比较,发现自己(id_001),是所有子节点最小的。所以得到锁。
客户端 B 拿到 /distribute_lock 节点下的所有子节点,经过比较,发现自己(id_002),不是所有子节点最小的。所以监听比自己小的节点 id_001 的状态。
客户端 C 拿到 /distribute_lock 节点下的所有子节点,经过比较,发现自己(id_003),不是所有子节点最小的。所以监听比自己小的节点 id_002 的状态。
等到客户端 A 执行完操作以后,将自己创建的节点 id_001 删除。通过监听,客户端 B 发现 id_001 节点已经删除了,发现自己已经是最小的节点了,于是顺利拿到锁。
以此类推。。。。。。。
集群管理
在分布式环境中,掌握集群中每个节点的状态是有必要的,我们用zookeeper做集群管理可以实现检测是否有机器加入或者退出,还可以用来选举集群的master。
要实现检测是否有机器退出,我们要在集群中的所有机器约定在父目录下创建临时目录节点,然后监听父目录节点的子节点变化情况。如果有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他的机器都将收到通知:这台机器离开了集群。检测是否有机器加入也是类似的过程。

只要客户端 A 挂了,那/GroupMember/A这个节点就会删除,通过监听 GroupMember 下的子节点,客户端 B 和客户端 C 就能够感知到客户端 A 已经挂了(新增也是同理)文章来源:https://www.toymoban.com/news/detail-515690.html
总结
这篇文章主要讲解了ZooKeeper 的入门相关的知识,解释 ZooKeeper 是什么,可以用来做什么,以及是怎么做到这些事情的,ZooKeeper 通过 Znode 的节点类型+监听机制就可以做到这么多事。文章来源地址https://www.toymoban.com/news/detail-515690.html
到了这里,关于ZooKeeper能做什么?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!