Spark的常用算子
Spark 内置算子是指 Spark 提供的具有高性能、高效率和高可靠性的数据操作函数。Spark 内置算子可以帮助我们完成大量的数据预处理、处理和分析任务。其主要包括以下 4 类算子:
转换算子(Transformation):用于将一个 RDD 转换为另一个 RDD,常见的有 map、flatMap、filter 等。
行动算子(Action):用于对 RDD 执行计算,常见的有 reduce、collect、count 等。
键值对算子(PairRDDFunctions):用于处理 K-V 形式的 RDD,常见的有 reduceByKey、groupByKey、sortByKey 等。
文件系统算子(File System):用于进行文件系统的操作,常见的有 textFile、saveAsTextFile、wholeTextFiles 等。
下面简单介绍一下这些内置算子的详细用法:
一、转换算子(Transformation)
map(func): 将原 RDD 中的每个元素传递给函数 func,得到一个新的 RDD。
flatMap(func): 与 map 类似,但每个元素都可以生成多个输出,这些输出被平铺(flattening)成一个新的 RDD。
filter(func): 返回输入 RDD 中通过函数 func 的筛选结果为 true 的元素。
distinct([numTasks])): 返回输入 RDD 中所有不同的元素,可选参数 numTasks 指定任务的数量。
union(otherRDD): 返回对输入 RDD 和参数 RDD 执行联合操作的结果,生成一个新的 RDD,不去重。
intersection(otherRDD)): 返回对输入 RDD 和参数 RDD 执行交集操作的结果,生成一个新的 RDD。
subtract(otherRDD): 返回对输入 RDD 和参数 RDD 执行差集操作的结果,生成一个新的 RDD。
cartesian(otherRDD): 返回对输入 RDD 和参数 RDD 执行笛卡尔积的结果,生成一个新的 RDD。
二、行动算子(Action)
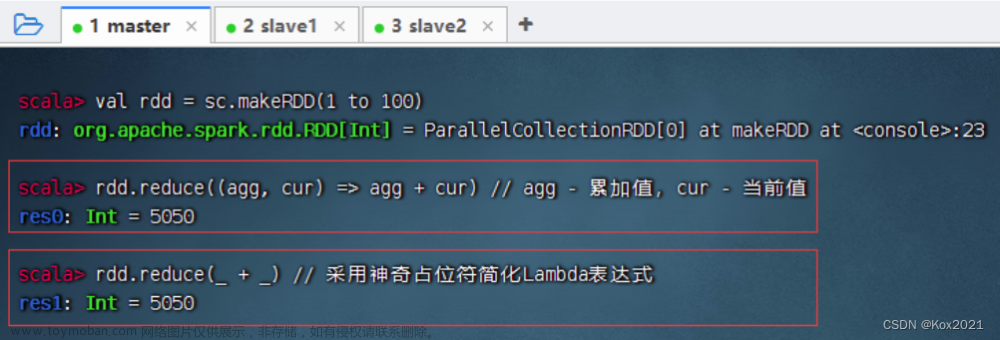
reduce(func): 使用函数 func 组合 RDD 中的所有元素,返回计算结果。
collect(): 将 RDD 中的所有元素都返回给驱动程序程序。
count(): 返回 RDD 中元素的数量。
first(): 返回 RDD 的第一个元素。
take(n): 返回 RDD 的前 n 个元素。
takeSample(withReplacement, num, [seed]): 从 RDD 中随机取样 num 个元素,withReplacement 指定是否允许取样后返回的元素有重复,seed 指定随机数种子。
takeOrdered(n, [ordering]): 返回包含 RDD 前 n 个元素的列表,元素是按顺序排序的。
aggregate(zeroValue, seqOp, combOp): 使用给定的函数对 RDD 的元素进行聚合,seqOp 计算在分区中初始值到中间结果的聚合计算,而 combOp 在节点上对中间结果进行聚合。
fold(zeroValue, func): 与 aggregate 类似,但这里的 seqOp 和 combOp 相同。
foreach(func): 对 RDD 中的每个元素执行指定的函数。
三、键值对算子(PairRDDFunctions)
reduceByKey(func, [numTasks]): 按键值对中的键将数据聚合在一起,并使用给定的函数进行聚合。
groupByKey([numTasks]): 按键值对中的键将数据分组,并生成一个迭代器,该迭代器包含与每个唯一键关联的所有元素。
mapValues(func): 对键值对的值应用给定的函数。
flatMapValues(func): 对键值对的值应用给定的函数,并生成一个迭代器,该迭代器包含每个键的所有结果。
keys(): 返回键值对 RDD 中所有键的列表。
values(): 返回键值对 RDD 中所有值的列表。
sortByKey([ascending], [numTasks]): 对键值对 RDD 中的键进行排序,ascending 指定是否按升序排序,numTasks 指定任务数量。
四、文件系统算子(File System)
textFile(path, [minPartitions]): 读取一个文件或文件系统中的所有文件,并返回表示它们的 RDD。
wholeTextFiles(path, [minPartitions]): 读取一个文件或文件系统中的所有文件,返回两项组成的元组,第一项是文件名,第二项是文件中的内容。
saveAsTextFile(path): 将 RDD 的内容写入一个文本文件。
saveAsSequenceFile(path): 将 RDD 的内容作为 Hadoop SequenceFile 保存。文章来源:https://www.toymoban.com/news/detail-515913.html
saveAsObjectFile(path): 将 RDD 的内容序列化成字节并保存到文件中。文章来源地址https://www.toymoban.com/news/detail-515913.html
到了这里,关于【Spark】Spark的常用算子的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!