分类目录:《自然语言处理从入门到应用》总目录
相关文章:
· 预训练模型总览:从宏观视角了解预训练模型
· 预训练模型总览:词嵌入的两大范式
· 预训练模型总览:两大任务类型
· 预训练模型总览:预训练模型的拓展
· 预训练模型总览:迁移学习与微调
· 预训练模型总览:预训练模型存在的问题
从大量无标注数据中进行预训练使许多自然语言处理任务获得显著的性能提升。总的来看,预训练模型的优势包括:
- 在庞大的无标注数据上进行预训练可以获取更通用的语言表示,并有利于下游任务
- 为模型提供了一个更好的初始化参数,在目标任务上具备更好的泛化性能、并加速收敛
- 是一种有效的正则化手段,避免在小数据集上过拟合,而一个随机初始化的深层模型容易对小数据集过拟合
下图就是各种预训练模型的思维导图,其分别按照词嵌入(Word Embedding)方式分为静态词向量(Static Word Embedding)和动态词向量(Dynamic Word Embedding)方式分类、按照监督学习和自监督学习方式进行分类、按照拓展能力等分类方式展现:
思维导图可编辑源文件下载地址:https://download.csdn.net/download/hy592070616/87954682
预训练模型的发展经历从浅层的词嵌入到深层编码两个阶段,按照这两个主要的发展阶段,可以归纳出预训练模型编码的两大范式:静态词向量(Static Word Embedding)和动态词向量(Dynamic Word Embedding)。
静态词向量(Static Word Embedding)
静态词向量(Static Word Embedding)即浅层词嵌入,这一类预训练模型范式就是我们通常所说的“词向量”,其主要特点是学习到的是上下文独立的静态词嵌入,其主要代表为神经网络语言模型(Neural Network Language Model,NNLM)(参考《自然语言处理从入门到应用——静态词向量预训练模型:神经网络语言模型(Neural Network Language Model)》)、word2vec(参考《深入理解深度学习——Word Embedding:word2vec》),其包含CBOW(参考《深入理解深度学习——Word Embedding:连续词袋模型(CBOW, The Continuous Bag-of-Words Model)》)和Skip-Gram(参考《深入理解深度学习——Word Embedding:Skip-Gram模型》)以及Glove(参考《自然语言处理从入门到应用——全局向量的词嵌入:GloVe(Global Vectors for Word Representation)词向量》)等。这一类词嵌入通常采取浅层网络进行训练,而应用于下游任务时,整个模型的其余部分仍需要从头开始学习。因此,对于这一范式的预训练模型没有必要采取深层神经网络进行训练,采取浅层网络加速训练也可以产生好的词嵌入。
同时,静态词向量也有明显的缺陷:
- 静态词向量与上下文无关:每个单词的嵌入向量始终是相同,因此不能解决一词多义的问题。
- 容易出现未登录词(Out-Of-Vocabulary,OOV)问题,为了解决这个问题,相关文献提出了字符级表示或sub-word表示,如CharCNN 、FastText和Byte-Pair Encoding等。
| 词嵌入方式 | 训练目标 | 语料使用程度 | 特点 |
|---|---|---|---|
| NNLM | 语言模型 | 局部语料 | 基于语言模型进行训练的,词嵌入只是神经网络语言模型的一个产物 |
| word2vec | 非语言模型(窗口上下文) | 局部语料 | 为加速训练舍弃神经网络语言模型中的隐藏层;采用分层Softaax和负采样进行运算优化 |
| Glove | 非语言模型(词共现矩阵) | 全局语料 | 基于全局语料构建词共现矩阵然后进行矩阵分解求得 |
其中,Glove也可以被看作是更换了目标函数和权重函数的全局word2vec。
动态词向量(Dynamic Word Embedding)
动态词向量是通过一个预训练模型的编码器能够输出上下文相关的词向量,可以解决一词多义的问题。这一类预训练编码器输出的向量也被称为上下文相关的词向量(Contextualized Word Embedding)。
| 编码器 | 相关预训练模型 | 计算方式 | 特点 |
|---|---|---|---|
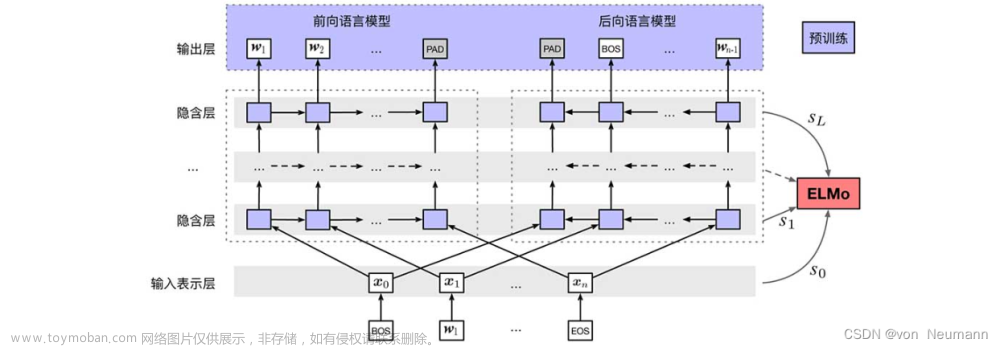
| LSTM | ELMo | 循环+串行 | 天然适合处理序列(位置)信息,但仍不能处理长距离依赖(由于BPTT导致的梯度消失等问题) |
| Transformer | GPT、BERT | 前馈+并行 | 可解解决长位置依赖;Self-Attention可以看做权重动态调整的全连接网络 |
| Transformer -XL | XL-Net | 循环+串行 | 基于Transformer 引入循环机制和相对位置编码,增强长距离建模能力 |
预训练编码器通常采用LSTM和Transformer(Transformer-XL),其中Transformer又根据其Attention Mask方式分为Transformer-Encoder和Transformer-Decoder两类。此外,Transformer也可看作是一种图神经网络(GNN)。文章来源:https://www.toymoban.com/news/detail-516110.html
参考文献:
[1] QIU XIPENG, SUN TIANXIANG, XU YIGE, et al. Pre-trained models for natural language processing: A survey[J]. 中国科学:技术科学(英文版),2020.文章来源地址https://www.toymoban.com/news/detail-516110.html
到了这里,关于自然语言处理从入门到应用——预训练模型总览:词嵌入的两大范式的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!