1.新建虚拟机配置网络并测试网络连接
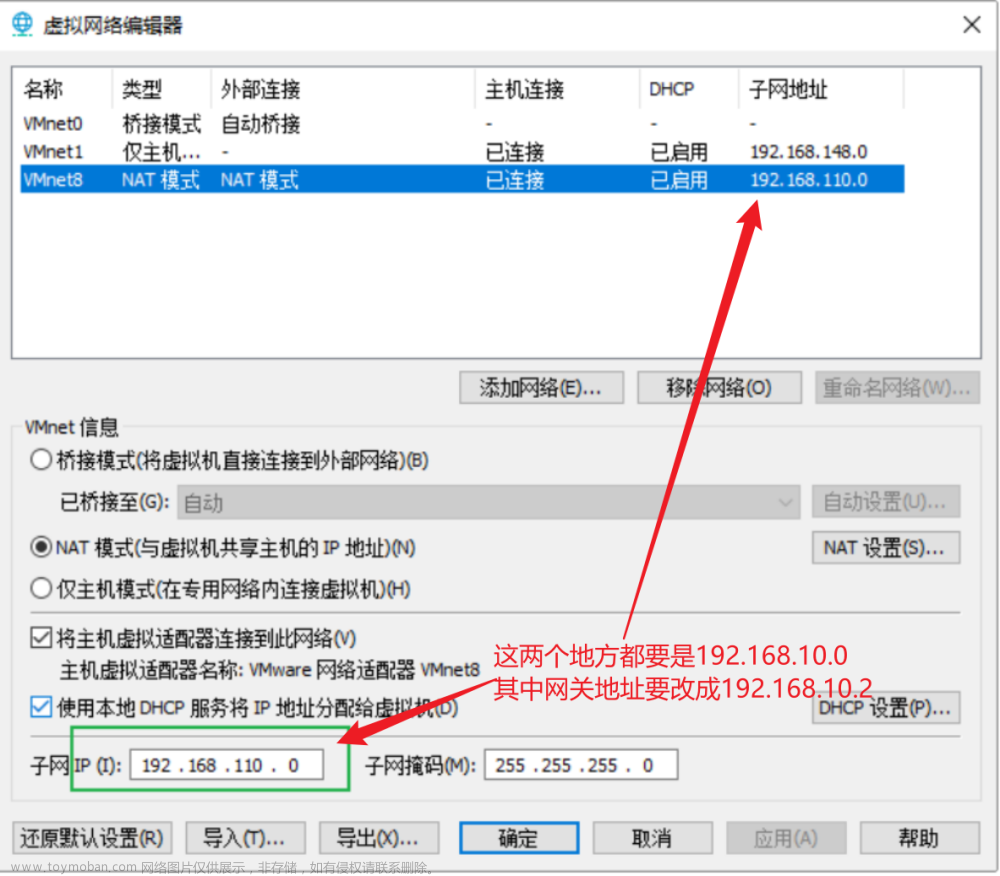
1.鼠标单击左侧虚拟机名称,接着单击菜单栏“编辑”,在下拉菜单中选择“虚拟网络适配器”, 如图 1-2-20 所示。

4.在打开的“虚拟网络编辑器”对话框,单击“NAT 设置”按钮,将网关的 IP 地址设置“192.168.110.2”

5.修改网络适配器配置文件。输入命令“cd /etc/sysconfig/network-scripts”按回车键,在输入ls查看网络名称

然后输入命令“vi ifcfg-ens33”按回车键,先按“i”字母键,修改内容如下:

6.关闭防火墙
systemctl stop firewalld.service
systemctl disable firewalld.service网络重置
service network restart测试互联网
ping www.baidu.com2.修改主机名及主机名与IP映射
1.启动linux系统,输入用户名和密码
2.查看用户名
hostname
或者hostnamectl3.使用hostnamectl set-hostname master将主机名修改为master
或者在文件/etc/sysconfig/network 里修改主机名。在任何目录下执行命令cd /etc/sysconfig,切换到该目录并查看目录下的文件,可以发现存在文件 network,
执行命令vi network 回车,编辑其中内容:
NETWORKING=yes HOSTNAME=master系统重新启动,执行reboot
3.安装JDK
1.用 CRT 将 jdk-8u171-linux-x64.tar.gz上传到 Linux 系统里
2.切换为root用户 su –root;
3.mkdir /simple,创建目录;
4.
## 解压jdk文件到simple目录下 tar -zxvf jdk-8u171-linux-x64.tar.gz /simple/
5.解压之后,执行命令 cd /simple,ll /simple,可以看到/simple 目录下多了一个解压后的JDK 文件

6.修改 JDK 环境变量,执行命令 vi /etc/profile,并“i”进入编辑内容,在文件最后添加下面的
export JAVA_HOME=/simple/jdk1.8.0_171
export PATH=$PATH:$JAVA_HOME/bin
在文件里编辑完成后按 Esc 接着 shift+“:”,输入“wq”保存并退出7.编辑完成之后使配置文件生效,
source /etc/profile8.完成以上步骤之后,需要测试环境变量是否配置成功,任何目录下输入 java -version,如果正确显示了 java 版本号,则表示配置成功,

4.安装伪分布式Hadoop
1.用 CRT 软件将 Hadoop-2.7.7.tar.gz 上传到 centos7 系统的/simple/software;
2.tar -zxvf hadoop-2.7.7.tar.gz –C /simple/ 解压到/simple 目录
3.在/simple/hadoop-2.7.7/etc/hadoop 目录下 hadoop-env.sh中添加如下内容:

4.修改配置文件core-site.xml
<configuration>
<property>
<!--指定 fs 缺省名称-->
<name>fs.default.name</name>
<value>hdfs://虚拟机名(或IP地址):9000</value>
</property>
<!--指定 HDFS 的 Namenode 的缺省路径地址-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://虚拟机名(或 IP 地址):9000</value>
</property>
<!--指定 hadoop 运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/simple/hadoop-2.7.7/tmp</value>
</property>
</configuration>5.修改文件hdfs-site.xml
<configuration>
<!--指定 hadoop 副本数-->
<property>
<name>dfs.replication </name>
<value>1</value>
</property>
<!--指定 namenode 存储目录-->
<property>
<name>dfs.name.dir</name>
<value>/simple/hadoop-2.7.7/hdfs/name</value>
</property>
<!--指定 datanode 存储目录-->
<property>
<name>dfs.data.dir</name>
<value>/simple/hadoop-2.7.7/hdfs/data</value>
</property>
</configuration>6.修改文件mapred-site.xml
<!--指定 hadoop 计算系统为 yarn-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
7.修改文件yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>虚拟机名(或者虚拟机 IP 地址)</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
8.执行命令 vi /etc/profile,把 Hadoop 的安装目录配置到环境变量中。
export JAVA_HOME=/simple/jdk1.8.0_171
export HADOOP_HOME=/simple/hadoop-2.7.7
export PATH=$JAVA_HOME/bin:$JAVA_HOME/sbin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH9.让配置文件生效 ;
source /etc/profile10.格式化命令
hdfs namenode -format
或者 hadoop namenode -format 格式化命令只能 1 次,多次执行就会造成 namenode 与 datanode 的 ID 值不一致,namenode 无法启动
12.start-dfs.sh,启动 HDFS 系统;
13.start-yarn.sh,启动 Yarn 进程;
14.在浏览器地址栏中输入虚拟机 IP 地址:50070和虚拟机IP地址:8080文章来源:https://www.toymoban.com/news/detail-516466.html
15.停止进程,执行命令 stop-dfs.sh,stop-yarn.sh。文章来源地址https://www.toymoban.com/news/detail-516466.html
到了这里,关于Hadoop伪分布搭建完整步骤的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!