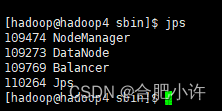
hadoop集群slave节点jps后没有datanode

这个问题是重复格式化造成的,重复格式化namenode造成datanode中的VERSION文件中clusterID与主节点的不一致。
1.关闭集群
stop-all.sh
2.找到安装hadoop的文件夹,我的是(/usr/local/hadoop)再找到里面的tmp/dfs/name/current,打开VERSION查看并复制clusterID的内容。
操作:在master里输入命令
cd /usr/local/hadoop/tmp/dfs/name/current
vim VERSION
:q

3.切换到slave节点,将/usr/local/hadoop/tmp/dfs/data/current里的VERSION文件中的clusterID替换成与master的VERSION文件中clusterID一致。
操作:在slave里输入命令
cd /usr/local/hadoop/tmp/dfs/data/current
vim VERSION
替换一致后:
4.重启集群:文章来源:https://www.toymoban.com/news/detail-516564.html
start-all.sh
 文章来源地址https://www.toymoban.com/news/detail-516564.html
文章来源地址https://www.toymoban.com/news/detail-516564.html
到了这里,关于hadoop集群slave节点jps后没有datanode解决方案的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!