1.准备ES环境配置
网上一搜一大把教程,这里就不多做陈述。
1.elasticsearch-7.17.1(es服务)
2.elasticsearch-head-master(可视化软件)
-
打开ES服务
进入es安装目录下F:\elasticsearch-7.17.1\bin,双击elasticsearch.bat,如图

成功后,如图

2. 打开ES可视化服务
进入安装F:\elasticsearch-head-master路径下,执行npm run start
3. 打开浏览器

2.maven父类依赖包
<!-- https://mvnrepository.com/artifact/org.springframework.boot/spring-boot-starter-data-elasticsearch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>2.6.6</version>
</dependency>
3.自己模块依赖包
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
4.创建映射ES依赖类
package com.datago.serve.domain;
import lombok.Data;
@Data
public class ESEntity {
private String images;//文件地址
private String name;//名称
private String fileType;
private String content;
}
5. 创建ES工具类
package com.datago.serve.utlis;
import com.alibaba.fastjson.JSON;
import com.datago.serve.domain.ESEntity;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.ingest.PutPipelineRequest;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.bytes.BytesArray;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.Operator;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Base64;
import java.util.List;
/**
* ES搜索引擎工具类(支持word、pdf、excel)
*/
@Component
@Slf4j
public class ESUtil {
private static RestHighLevelClient client;
private static String es_index;
@Autowired
public void setClient(RestHighLevelClient client) {
this.client = client;
}
@Value(value = "${elasticsearch.index}")
public void setEs_index(String es_index) {
this.es_index = es_index;
}
/**
* ES数据写入
*/
public static void getContent(MultipartFile file, String filePath) throws IOException {
ESEntity esEntity = new ESEntity();
byte[] bytes = file.getBytes();
//将文件内容转化为base64编码
String base64 = Base64.getEncoder().encodeToString(bytes);
String fileName = file.getOriginalFilename();
esEntity.setName(fileName);
esEntity.setContent(base64);
esEntity.setImages(filePath);
String prefix = fileName.substring(fileName.lastIndexOf(".") + 1);
esEntity.setFileType(prefix);
IndexRequest indexRequest = new IndexRequest(es_index);
indexRequest.source(JSON.toJSONString(esEntity), XContentType.JSON);
indexRequest.setPipeline("attachment");
client.index(indexRequest, RequestOptions.DEFAULT);
}
/**
* 创建attachment管道
* "indexed_chars": -1 (-1代表可是创建10W+数据)
* @throws Exception
*/
public static void putAttachmentPipeline() throws Exception {
String source = "{\n" +
" \"description\": \"Extract attachment information\",\n" +
" \"processors\": [\n" +
" {\n" +
" \"attachment\": {\n" +
" \"field\": \"content\",\n" +
" \"indexed_chars\": -1,\n" +
" \"ignore_missing\": true\n" +
" }\n" +
" },\n" +
" {\n" +
" \"remove\": {\n" +
" \"field\": \"content\"\n" +
" }\n" +
" }\n" +
" ]\n" +
"}";
PutPipelineRequest pipelineRequest = new PutPipelineRequest("attachment", new BytesArray(source), XContentType.JSON);
AcknowledgedResponse acknowledgedResponse = client.ingest().putPipeline(pipelineRequest, RequestOptions.DEFAULT);
System.out.println("创建管道成功:" + acknowledgedResponse.isAcknowledged());
}
/***
* 多条件搜索
* @param keyword
* @return
* @throws IOException
*/
public static List<ESEntity> eSearch(RestHighLevelClient client, String keyword, String index, String categoryId) throws IOException {
List<ESEntity> list = new ArrayList<>();
try {
BoolQueryBuilder qb = QueryBuilders.boolQuery();
if (StringUtils.isNotNull(keyword) && !keyword.equals("")) {
qb.must(QueryBuilders.matchQuery("attachment.content", keyword));
}
if (StringUtils.isNotNull(categoryId)) {
qb.must(QueryBuilders.matchQuery("categoryId", categoryId));
}
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.size(10000);
searchSourceBuilder.query(qb);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest();
searchRequest.source(searchSourceBuilder);
searchRequest.indices(index);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
// 根据状态和数据条数验证是否返回了数据
if (RestStatus.OK.equals(searchResponse.status())) {
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits) {
// 将 JSON 转换成对象
ESEntity esEntity = JSON.parseObject(hit.getSourceAsString(), ESEntity.class);
list.add(esEntity);
}
}
//5.解析查询结果
// System.out.println("花费的时长:" + searchResponse.getTook());
// SearchHits hits = searchResponse.getHits();
// System.out.println("符合条件的总文档数量:" + hits.getTotalHits().value);
// hits.forEach(p -> System.out.println("文档原生信息:" + p.getSourceAsString()));
} catch (Exception e) {
e.printStackTrace();
}
return list;
}
/**
* 通过ID删除数据
*
* @param index 索引,类似数据库
* @param id 数据ID
* @return
*/
public static String deleteDataById(RestHighLevelClient client, String index, String id) throws IOException {
DeleteRequest request = new DeleteRequest(index, id);
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
return deleteResponse.getId();
}
/**
* 使用from+size的方式实现 ES的分页查询
*
* @param client
* @param index 索引-
* @param keyword 关键词
* @param categoryId 分类ID
* @param pageNum 从第几条开始
* @param pageSize 显示多少条记录
* @return Map: 当前页的数据 总页数
*/
public static Map<String, Object> page(RestHighLevelClient client, String index,
String keyword, String categoryId, int pageNum, int pageSize) {
BoolQueryBuilder qb = QueryBuilders.boolQuery();
if (StringUtils.isNotNull(keyword) && !keyword.equals("")) {
qb.must(QueryBuilders.matchQuery("attachment.content", keyword));
}
if (StringUtils.isNotNull(categoryId)) {
qb.must(QueryBuilders.matchQuery("categoryId", categoryId));
}
// 创建查询源构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.from(pageNum);
searchSourceBuilder.size(pageSize);
searchSourceBuilder.query(qb);
// 创建查询请求对象,将查询对象配置到其中
SearchRequest searchRequest = new SearchRequest();
searchRequest.source(searchSourceBuilder);
searchRequest.indices(index);
Map<String, Object> result = new HashMap<>();
List<ESEntity> resultList = new ArrayList<>();
int page = 0;
try {
SearchResponse searchResponse =
client.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = searchResponse.getHits();
long totalValue = hits.getTotalHits().value; //获得总记录数 3.0/2=1.5 Math.ceil(1.5) 2.0;
page = (int) Math.ceil((double) totalValue / pageSize); //总页数
SearchHit[] searchHits = hits.getHits();
for (SearchHit searchHit : searchHits) {
// 将 JSON 转换成对象
ESEntity esEntity = JSON.parseObject(searchHit.getSourceAsString(), ESEntity.class);
resultList.add(esEntity);
}
} catch (IOException e) {
e.printStackTrace();
}
result.put("page", page);
result.put("list", resultList);
return result;
}
6. 控制类API接口
package com.datago.serve.controller;
import com.datago.common.core.domain.R;
import com.datago.common.core.utils.StringUtils;
import com.datago.common.core.web.controller.BaseController;
import com.datago.common.core.web.domain.AjaxResult;
import com.datago.common.core.web.page.TableDataInfo;
import com.datago.common.log.annotation.Log;
import com.datago.common.log.enums.BusinessType;
import com.datago.common.security.utils.SecurityUtils;
import com.datago.serve.domain.ESEntity;
import com.datago.serve.utlis.ESUtil;
import com.datago.system.api.RemoteFileService;
import com.datago.system.api.domain.SysFile;
import io.swagger.annotations.ApiOperation;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;
import java.io.IOException;
import java.util.*;
@RestController
@RequestMapping("/file")
public class FileDataController extends BaseController {
@Autowired
private RestHighLevelClient client;
@Value(value = "${elasticsearch.index}")
private String es_index;
@Autowired
private RemoteFileService remoteFileService;
/**
* 创建attachment管道
*
* @throws Exception
*/
@PutMapping(value = "/putAttachmentPipeline")
public void putAttachmentPipeline() throws Exception {
ESUtil.putAttachmentPipeline();
}
/**
* 文件上传
*/
@Log(title = "数据上传", businessType = BusinessType.INSERT)
@PostMapping(value = "/uploadFile")
public AjaxResult uploadFile(@RequestPart MultipartFile file) throws IOException {
//获取桶
String tenantCode = SecurityUtils.getTenantCode();
/** 上传源文件到minio上 */
R<SysFile> sysFileR = remoteFileService.uploadFile(tenantCode, file, "ES/FileKu/" + file.getOriginalFilename());
if (StringUtils.isNotNull(sysFileR)) {
SysFile data = sysFileR.getData();
//写入ES引擎
ESUtil.getContent(file, remoteFileService.getPrefix() + data.getUrl());
return AjaxResult.success();
} else {
return AjaxResult.error("上传源文件异常");
}
}
@ApiOperation(value = "ES检索")
@GetMapping(value = "/eSearch")
public TableDataInfo eSearch(@RequestParam(value = "keyword") String keyword) {
List<ESEntity> esEntities = null;
try {
startPage();
esEntities = ESUtil.eSearch(keyword);
} catch (IOException e) {
throw new RuntimeException(e);
}
return getDataTable(esEntities);
}
}
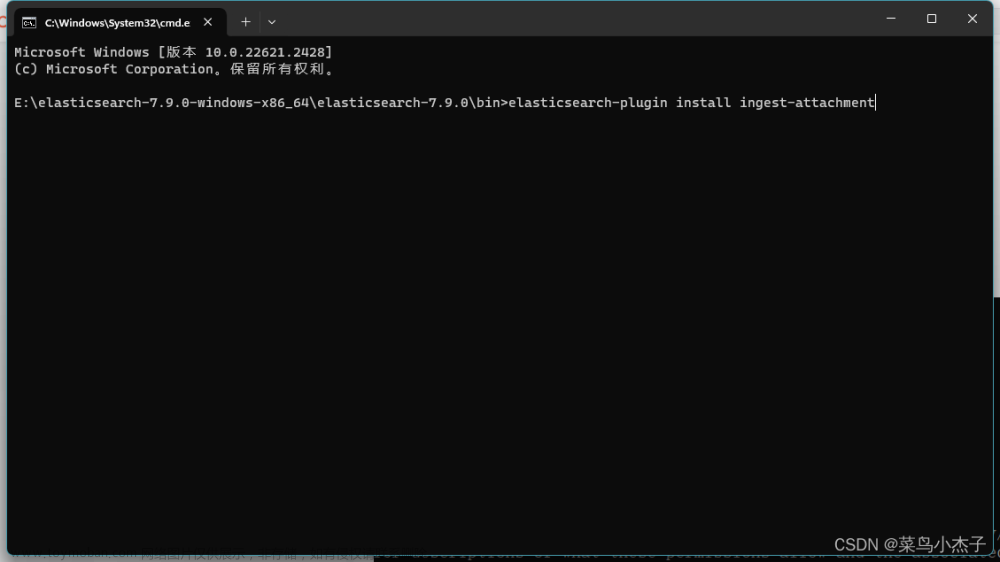
7.ES中使用插件ingest-attachment安装
进入ES安装包F:\elasticsearch-7.17.1\bin,执行elasticsearch-plugin install ingest-attachment
 文章来源:https://www.toymoban.com/news/detail-516602.html
文章来源:https://www.toymoban.com/news/detail-516602.html
8.ES与可视化软件elasticsearch-head-master分享(文件过大)-联系博主
参考文献:https://blog.csdn.net/mjl1125/article/details/121975950文章来源地址https://www.toymoban.com/news/detail-516602.html
到了这里,关于ES+微服务对文档进行全文检索的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![全文检索[ES系列] - 第495篇](https://imgs.yssmx.com/Uploads/2024/02/763717-1.png)